Sas で重複を削除する方法 (例あり)
SAS でproc sort を使用すると、データセットから重複行をすばやく削除できます。
この手順では、次の基本構文を使用します。
proc sort data =original_data out =no_dups_data nodupkey ;
by _all_;
run;
by引数は、重複を削除するときにスキャンする列を指定することに注意してください。
次の例は、SAS の次のデータ セットから重複を削除する方法を示しています。
/*create dataset*/
data original_data;
input team $position $points;
datalines ;
A Guard 12
A Guard 20
A Guard 20
A Guard 24
A Forward 15
A Forward 15
A Forward 19
A Forward 28
B Guard 10
B Guard 12
B Guard 12
B Guard 26
B Forward 10
B Forward 10
B Forward 10
B Forward 19
;
run ;
/*view dataset*/
proc print data = original_data;
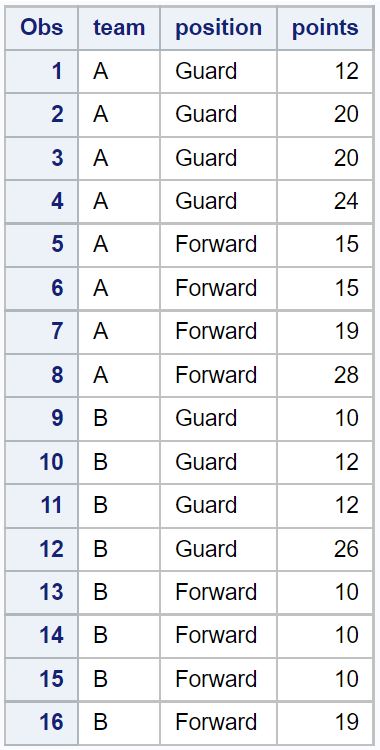
例 1: すべての列から重複を削除する
次のコードを使用して、データセット内のすべての列で重複した値を持つ行を削除できます。
/*create dataset with no duplicate rows*/
proc sort data =original_data out =no_dups_data nodupkey ;
by _all_;
run ;
/*view dataset with no duplicate rows*/
proc print data =no_dups_data;
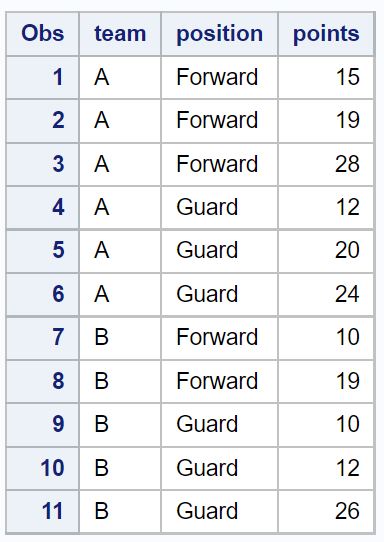
合計 5 つの重複行が元のデータセットから削除されたことに注意してください。
例 2:特定の列から重複を削除する
by引数を使用して、重複を削除するときに調べる列を指定できます。
たとえば、次のコードはチーム列とポジション列で重複した値を持つ行を削除します。
/*create dataset with no duplicate rows in team and position columns*/
proc sort data =original_data out =no_dups_data nodupkey ;
by team position;
run ;
/*view dataset with no duplicate rows in team and position columns*/
proc print data =no_dups_data;
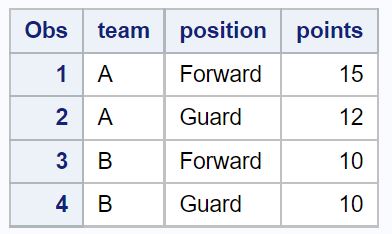
チーム列とポジション列で重複した値を持つ行を削除した後、データセットには 4 行だけが残ります。
追加リソース
次のチュートリアルでは、SAS で他の一般的な操作を実行する方法について説明します。
SAS でデータを正規化する方法
SAS で外れ値を特定する方法
SAS での手順の概要の使用方法
SAS で度数表を作成する方法
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る