高次元データとは何ですか? (定義と例)
高次元データとは、特徴の数pが観測値の数Nよりも大きいデータ セットを指し、多くの場合p >> Nと表記されます。
たとえば、 p = 6 の特徴とN = 3 の観測値のみを含むデータセットは、特徴の数が観測値の数よりも大きいため、高次元データとみなされます。
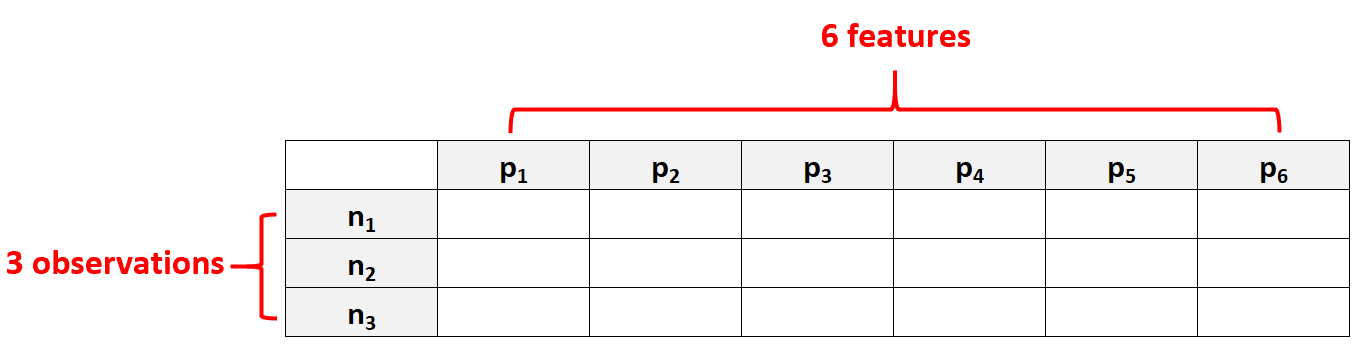
よくある間違いは、「高次元データ」とは単に多くの特徴を持つデータ セットを意味すると考えることです。しかし、これは間違いです。データセットには 10,000 個の特徴が含まれる場合がありますが、100,000 個の観測値が含まれる場合、そのデータセットは高次元ではありません。
注:高次元データの背後にある数学の詳細については、「統計学習の要素」の第 18 章を参照してください。
なぜ高次元データが問題になるのでしょうか?
データセット内の特徴の数が観測値の数を超えると、決定的な答えは得られません。
言い換えれば、モデルをトレーニングするための十分な観測値がないため、予測変数と応答変数の間の関係を説明できるモデルを見つけることは不可能になります。
高次元データの例
次の例は、さまざまなドメインの高次元データセットを示しています。
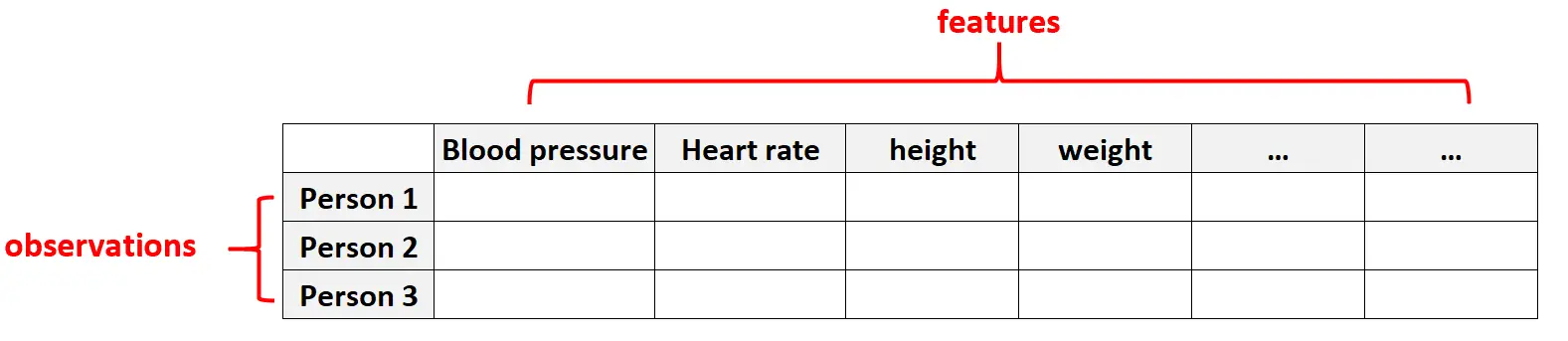
例 1: 健康データ
高次元データは、特定の個人の特徴の数が膨大になる可能性があるヘルスケア データセット (つまり、血圧、安静時心拍数、免疫システムの状態、手術歴、身長、体重、現在の状態など) で一般的です。
これらのデータセットでは、フィーチャの数が観測値の数よりも多いのが一般的です。
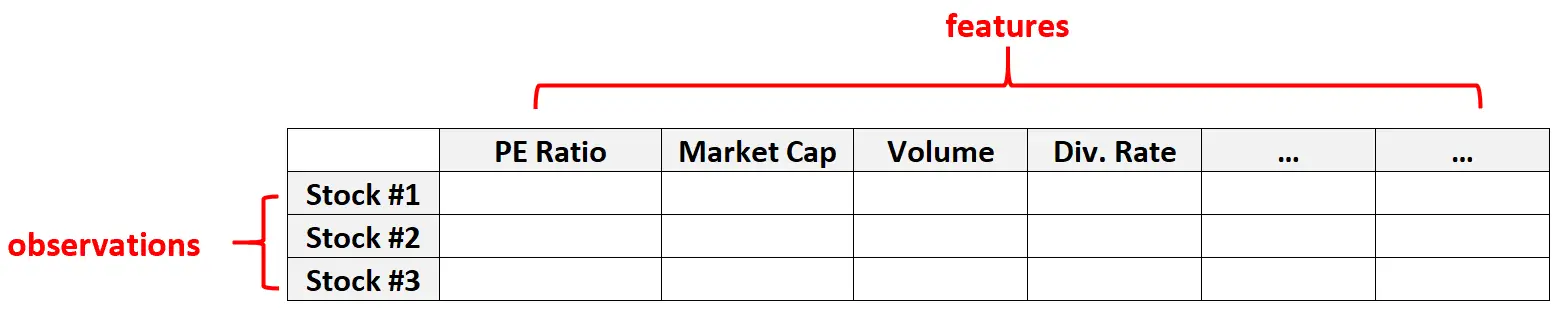
例 2: 財務データ
高次元データは、特定の株式の特徴の数 (つまり、PER、時価総額、取引高、配当率など) が非常に大きくなる可能性がある金融データセットでも一般的です。
このようなタイプのデータセットでは、エンティティの数が個々のアクションの数よりもはるかに多いのが一般的です。
例 3: ゲノミクス
高次元データは、特定の個人の遺伝的特徴の数が膨大になる可能性があるゲノミクスの分野でも一般的です。

大きなデータをどう扱うか
高次元データを処理するには、次の 2 つの一般的な方法があります。
1. 含める機能の数を少なくします。
高次元データの処理を回避する最も明白な方法は、単にデータセットに含めるフィーチャの数を減らすことです。
データセットからどの特徴を削除するかを決定するには、次のようないくつかの方法があります。
- 欠損値が多いフィーチャを削除する:データセット内の特定の列に多くの欠損値がある場合、多くの情報を失わずに完全に削除できる場合があります。
- 分散の低い特徴量を削除する:データセット内の特定の列の値の変化がほとんどない場合、その列は他の特徴量に比べて応答変数に関する有益な情報が提供されにくいため、その列を削除できる可能性があります。
- 応答変数との相関が低い特徴を削除する:特定の特徴が関心のある応答変数と相関が高くない場合、それがモデル内で有用な特徴である可能性は低いため、データセットから削除できます。
2. 正則化手法を使用します。
データセットから特徴を削除せずに高次元データを処理するもう 1 つの方法は、次のような正則化手法を使用することです。
これらの手法はそれぞれ、高次元データを効率的に処理するために使用できます。
すべての統計的機械学習チュートリアルの完全なリストは、このページで見つけることができます。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る