모란의 자아는 무엇인가? (정의 & #038; 예)
Moran의 I는 공간적 자기상관을 측정하는 방법입니다.
쉽게 말하면 2차원 공간에서 값들이 얼마나 촘촘하게 밀집되어 있는지를 수량화하는 방법이다. 이는 지리 및 지리 정보 과학(GIS) 에서 가계 소득, 교육 수준 등과 같은 다양한 기능이 지도에 얼마나 밀접하게 그룹화되어 있는지 측정하는 데 자주 사용됩니다.
모란의 I: 공식
Moran의 I를 계산하는 공식은 다음과 같습니다.
I = (N/W)*ΣΣw ij (x i – x )(x j – x )/Σ(x i – x ) 2
금:
- N: i 와 j 로 인덱스된 공간 단위의 수
- W: 모든 w ij 의 합
- x: 관심변수(가계소득, 교육기간 등)
- x : x의 평균
- w ij : 공간 가중치 행렬
대부분의 통계 소프트웨어가 이를 계산해 주므로 이 측정값을 직접 계산할 필요는 없지만 내부적으로 사용되는 공식을 알아두면 도움이 됩니다.
Moran’s I의 값 범위는 -1에서 1까지입니다.
- -1: 관심 변수가 완벽하게 분산되어 있습니다.
- 0: 관심 변수가 무작위로 분산되어 있습니다.
- 1: 관심 변수가 완벽하게 그룹화되어 있습니다.
Moran의 I 계산과 함께 대부분의 통계 소프트웨어는 데이터가 무작위로 분산되어 있는지 여부를 결정하는 데 사용할 수 있는 해당 p-값을 계산합니다.
Moran 테스트는 다음과 같은 귀무 가설과 대립 가설을 사용합니다.
귀무 가설(H 0 ): 데이터가 무작위로 분산되어 있습니다.
대립 가설( HA ): 데이터가 무작위로 분산되지 않습니다 . 즉, 눈에 보이는 패턴으로 그룹화됩니다.
Moran의 I에 해당하는 p-값이 특정 유의 수준(즉, α = 0.05)보다 낮으면 귀무 가설을 기각하고 데이터가 공간적으로 클러스터링될 가능성이 없도록 공간적으로 클러스터링되어 있다는 결론을 내릴 수 있습니다. 우연히 발생했습니다.
모란의 I: 몇 가지 예
다음 예는 Moran의 I에 대해 서로 다른 값을 가진 거짓 카드를 나타냅니다.
지도의 각 사각형이 카운티를 나타내고 평균 가계 소득이 $50,000 이상인 카운티가 파란색으로 표시되어 있다고 가정해 보겠습니다.
Moran의 I = 0: 평균 가계 소득이 무작위로 분산됩니다(즉, 무작위 영역의 무작위 클러스터).
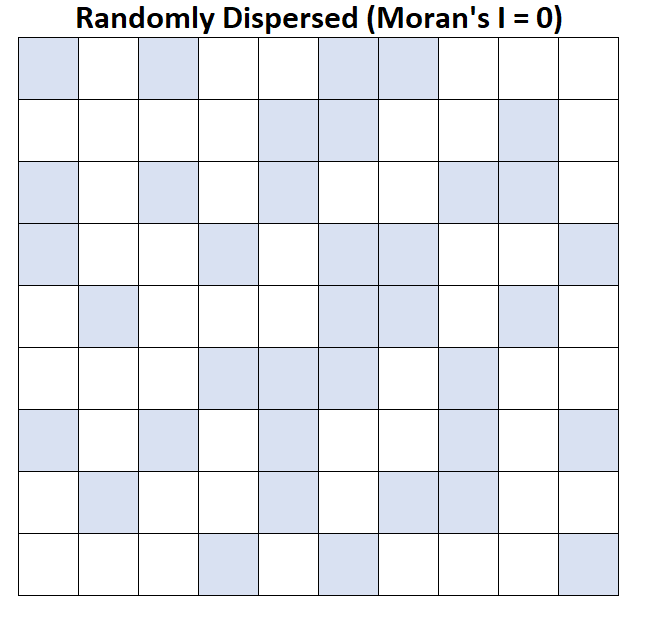
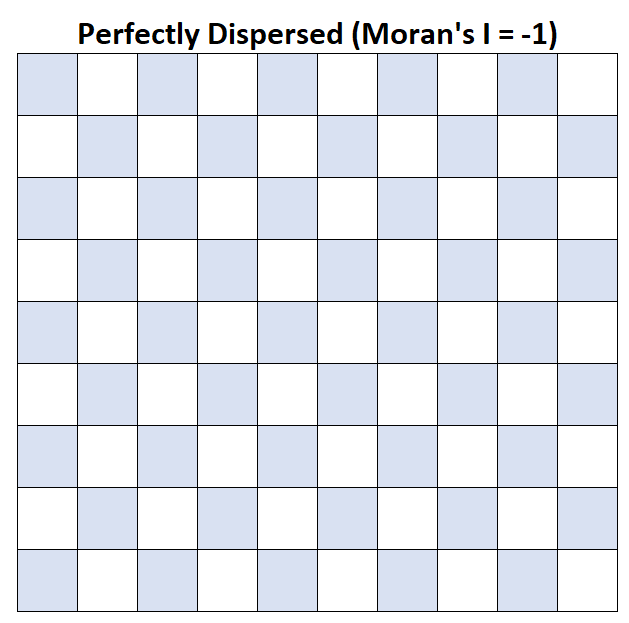
Moran의 I = -1: 평균 가계 소득이 완벽하게 분산되어 있습니다.
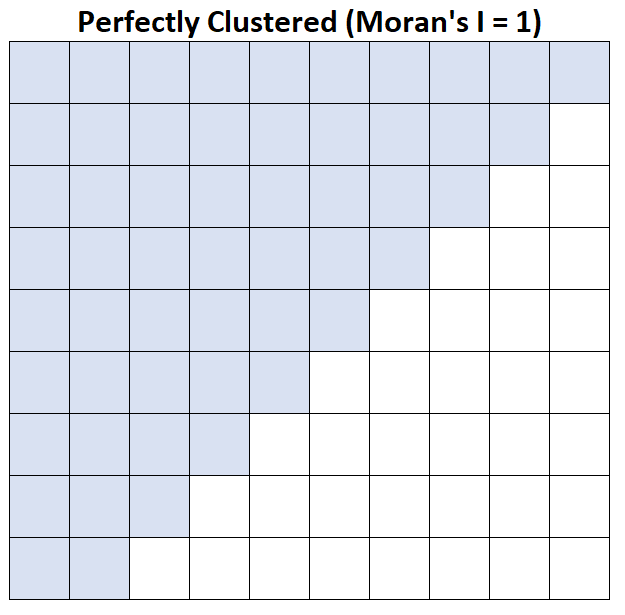
Moran의 I = 1: 평균 가계 소득이 완벽하게 그룹화되어 있습니다.
통계 소프트웨어 R에서 Moran의 I를 계산하는 구체적인 예는 이 예를 참조하십시오.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기