R의 iris 데이터세트에 대한 완전한 가이드
아이리스 데이터세트는 3종의 50개 꽃에 대한 4가지 속성(센티미터)에 대한 측정값을 포함하는 R의 통합 데이터세트입니다.
이 튜토리얼에서는 붓꽃 데이터세트를 예로 들어 R에서 데이터세트를 탐색하고 요약하는 방법을 설명합니다.
관련 항목: R의 mtcars 데이터 세트에 대한 전체 가이드
붓꽃 데이터세트 로드
붓꽃 데이터세트는 R에 내장된 데이터세트이므로 다음 명령을 사용하여 로드할 수 있습니다.
data(iris)
head() 함수를 사용하여 데이터세트의 처음 6개 행을 살펴볼 수 있습니다.
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Iris 데이터세트 요약
summary() 함수를 사용하여 데이터세트의 각 변수를 빠르게 요약할 수 있습니다.
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
각 수치 변수에 대해 다음 정보를 볼 수 있습니다.
- Min : 최소값입니다.
- 1st Qu : 1사분위수(25번째 백분위수)의 값입니다.
- 중앙값 : 중앙값입니다.
- 평균 : 평균값입니다.
- 3rd Qu : 3분위수(75번째 백분위수)의 값입니다.
- 최대 : 최대값입니다.
데이터 세트(종)의 유일한 범주형 변수에 대해 각 값의 빈도 수를 볼 수 있습니다.
- setosa : 이 종은 50번 존재한다.
- versicolor : 이 종은 50번 발생합니다.
- virginica : 이 종은 50번 존재합니다.
희미한() 함수를 사용하여 행과 열 수로 데이터세트의 차원을 얻을 수 있습니다.
#display rows and columns
dim(iris)
[1] 150 5
데이터 세트에 150개의 행과 5개의 열이 있는 것을 볼 수 있습니다.
names() 함수를 사용하여 데이터 프레임의 열 이름을 표시할 수도 있습니다.
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Iris 데이터 세트 시각화
데이터 세트의 값을 시각화하기 위해 플롯을 만들 수도 있습니다.
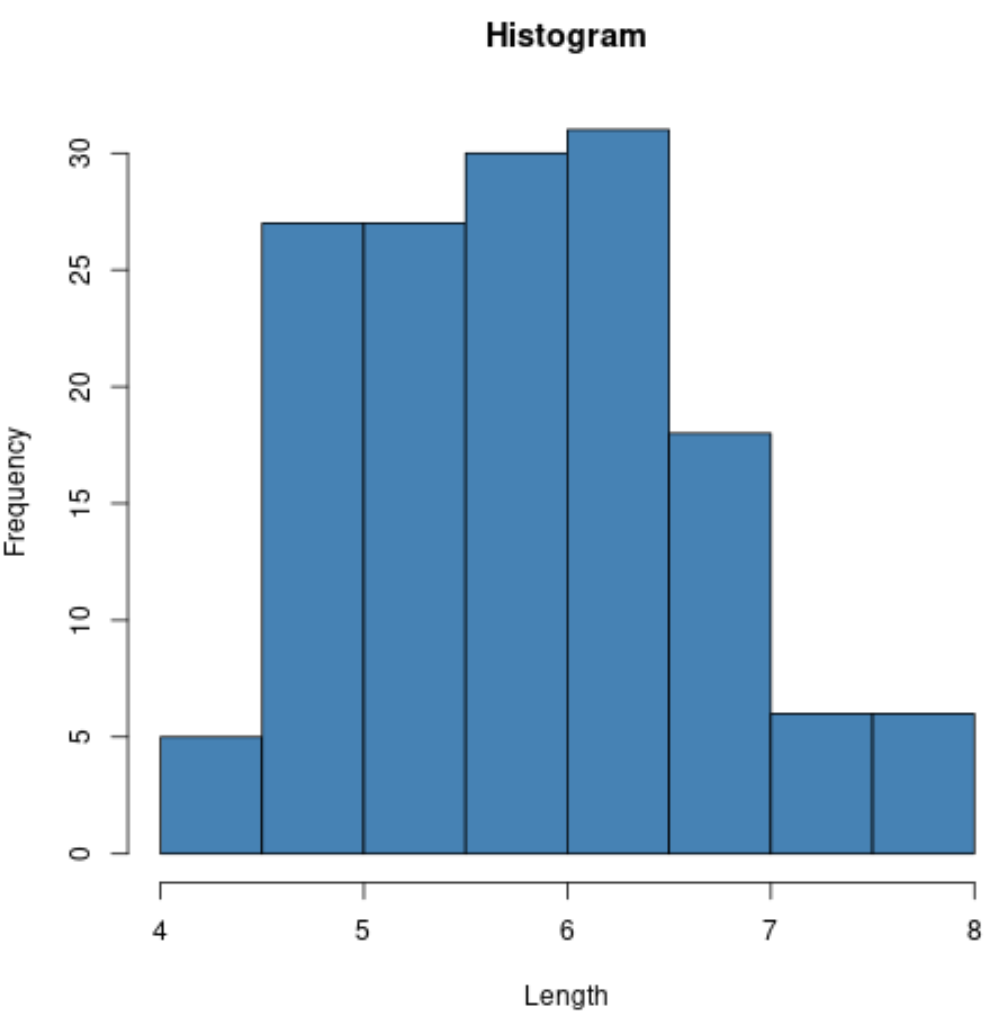
예를 들어, hist() 함수를 사용하여 특정 변수 값의 히스토그램을 만들 수 있습니다.
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
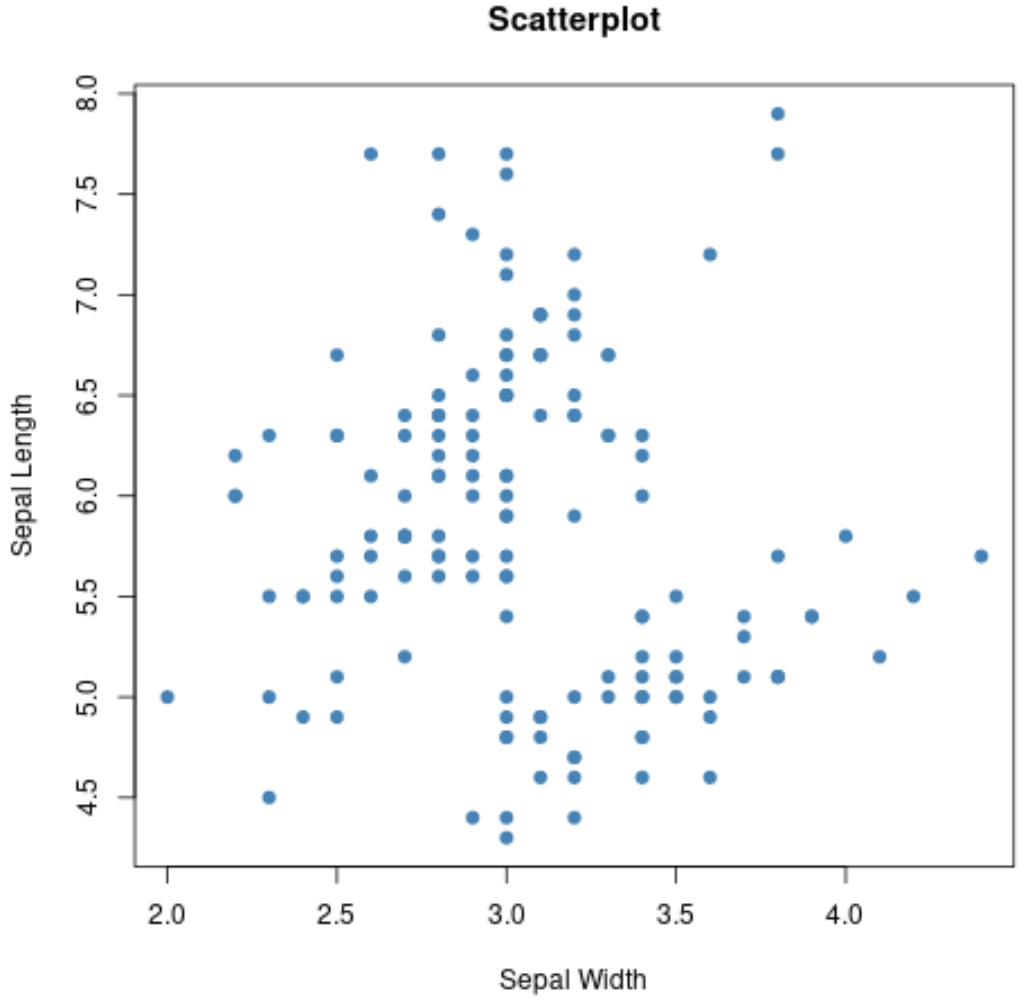
또한 플롯() 함수를 사용하여 변수의 쌍별 조합에 대한 산점도를 만들 수도 있습니다.
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
boxplot() 함수를 사용하여 그룹별로 상자 그림을 만들 수도 있습니다.
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
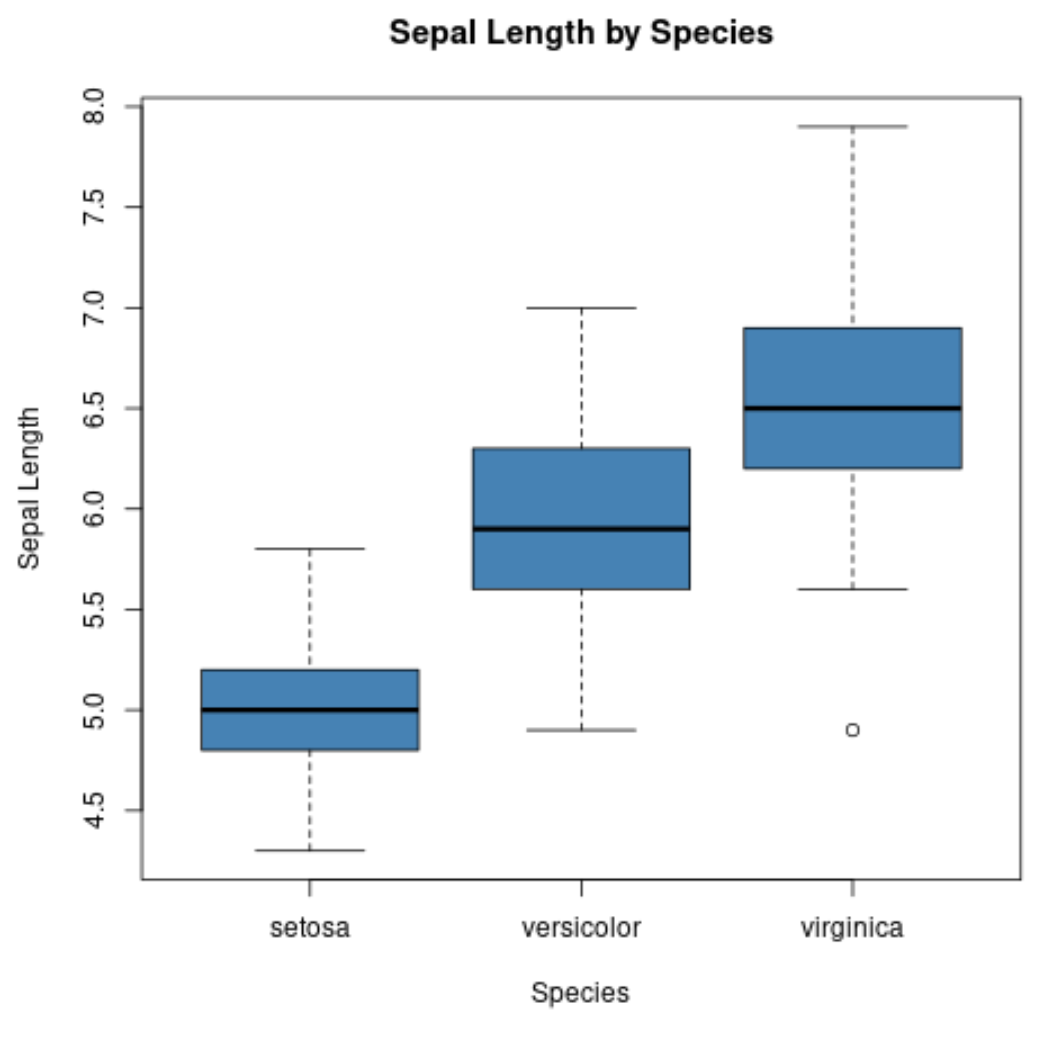
x축은 세 가지 종을 표시하고 y축은 각 종에 대한 꽃받침 길이 값의 분포를 표시합니다.
이러한 유형의 플롯을 통해 우리는 꽃받침의 길이가 버지니아 종의 경우 가장 크고 세토사 종의 경우 가장 작은 경향이 있음을 빠르게 확인할 수 있습니다.
추가 리소스
다음 튜토리얼에서는 R에서 데이터세트를 요약하는 방법을 자세히 설명합니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기