Python에서 2차 회귀를 수행하는 방법
2차 회귀 는 실제 관계가 2차(그래프에서 “U” 또는 반전된 “U” 모양)일 때 예측 변수와 응답 변수 간의 관계를 수량화하는 데 사용할 수 있는 회귀 유형입니다.
즉, 예측변수가 증가하면 반응변수도 증가하는 경향이 있으나, 일정 시점 이후에는 예측변수가 계속 증가하면서 반응변수가 감소하기 시작한다.
이 튜토리얼에서는 Python에서 2차 회귀를 수행하는 방법을 설명합니다.
예: Python의 2차 회귀
주당 근무 시간에 대한 데이터가 있고 16명의 서로 다른 사람들에 대해 보고된 행복 수준(0~100점)이 있다고 가정해 보겠습니다.
import numpy as np import scipy.stats as stats #define variables hours = [6, 9, 12, 12, 15, 21, 24, 24, 27, 30, 36, 39, 45, 48, 57, 60] happ = [12, 18, 30, 42, 48, 78, 90, 96, 96, 90, 84, 78, 66, 54, 36, 24]
이 데이터의 간단한 산점도를 작성하면 두 변수 간의 관계가 “U”자 모양임을 알 수 있습니다.
import matplotlib.pyplot as plt
#create scatterplot
plt.scatter(hours, happ)
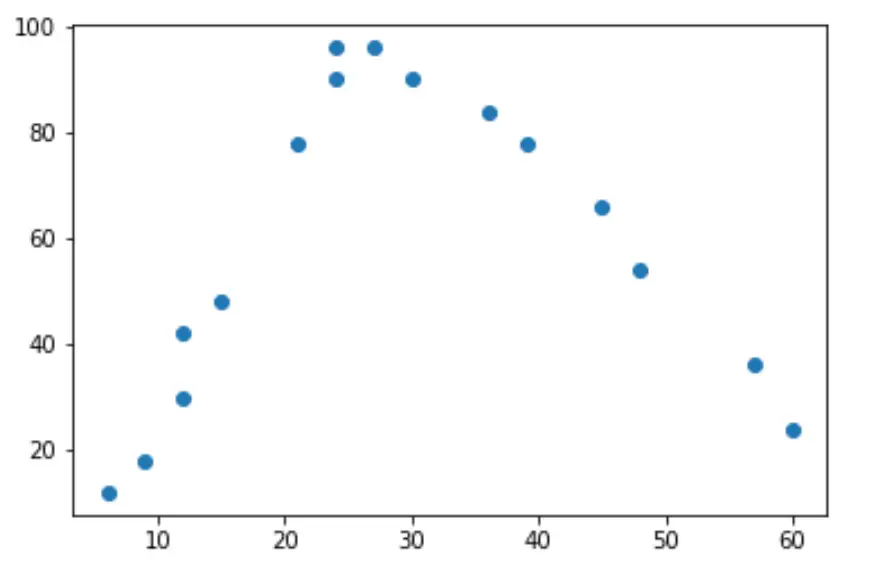
근무 시간이 늘어날수록 행복도 높아지지만, 근무 시간이 주당 약 35시간을 초과하면 행복도가 떨어지기 시작합니다.
이 “U” 모양으로 인해 이는 2차 회귀가 두 변수 간의 관계를 정량화하는 데 적합한 후보일 가능성이 높다는 것을 의미합니다.
실제로 2차 회귀를 수행하려면 numpy.polyfit() 함수를 사용하여 2차 다항식 회귀 모델을 맞출 수 있습니다 .
import numpy as np #polynomial fit with degree = 2 model = np.poly1d(np.polyfit(hours, happ, 2)) #add fitted polynomial line to scatterplot polyline = np.linspace(1, 60, 50) plt.scatter(hours, happ) plt.plot(polyline, model(polyline)) plt.show()
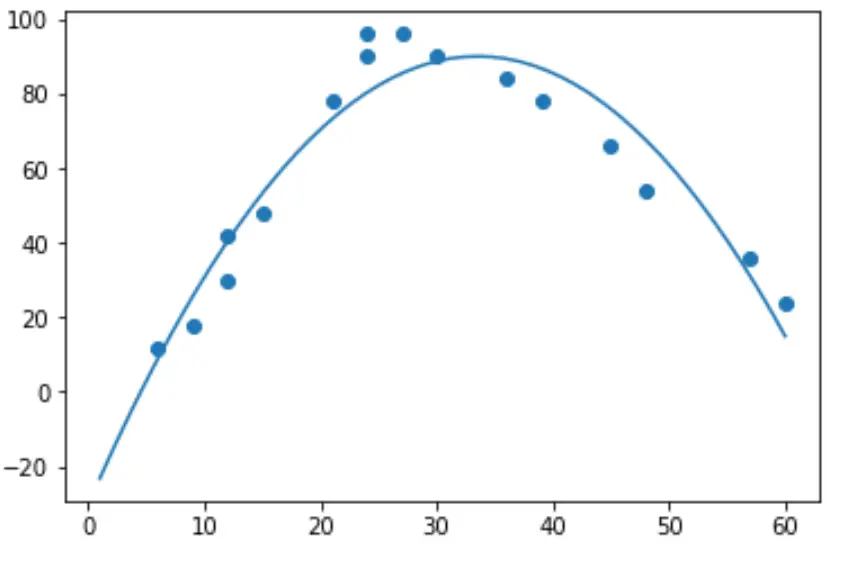
모델 계수를 인쇄하여 적합 다항식 회귀 방정식을 얻을 수 있습니다.
print (model)
-0.107x 2 + 7.173x - 30.25
적합된 2차 회귀 방정식은 다음과 같습니다.
행복 = -0.107(시간) 2 + 7.173(시간) – 30.25
우리는 이 방정식을 사용하여 근무 시간을 기준으로 개인의 기대 행복 수준을 계산할 수 있습니다. 예를 들어, 주당 30시간 일하는 사람의 기대 행복 수준은 다음과 같습니다.
행복 = -0.107(30) 2 + 7.173(30) – 30.25 = 88.64 .
예측 변수로 설명할 수 있는 응답 변수의 분산 비율인 모델의 R-제곱을 얻기 위해 짧은 함수를 작성할 수도 있습니다.
#define function to calculate r-squared def polyfit(x, y, degree): results = {} coeffs = np.polyfit(x, y, degree) p = np.poly1d(coeffs) #calculate r-squared yhat = p(x) ybar = np.sum(y)/len(y) ssreg = np.sum((yhat-ybar)**2) sstot = np.sum((y - ybar)**2) results['r_squared'] = ssreg / sstot return results #find r-squared of polynomial model with degree = 3 polyfit(hours, happ, 2) {'r_squared': 0.9092114182131691}
이 예에서 모델의 R 제곱은 0.9092 입니다.
이는 보고된 행복 수준의 변동 중 90.92%가 예측 변수로 설명될 수 있음을 의미합니다.
추가 리소스
Python에서 다항식 회귀를 수행하는 방법
R에서 2차 회귀를 수행하는 방법
Excel에서 2차 회귀를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기