Sas에서 중복을 제거하는 방법(예제 포함)
SAS에서 proc sort를 사용하면 데이터 세트에서 중복 행을 빠르게 제거할 수 있습니다.
이 절차에서는 다음 기본 구문을 사용합니다.
proc sort data =original_data out =no_dups_data nodupkey ;
by _all_;
run;
by 인수는 중복 항목을 제거할 때 검사할 열을 지정합니다.
다음 예에서는 SAS의 다음 데이터 세트에서 중복 항목을 제거하는 방법을 보여줍니다.
/*create dataset*/
data original_data;
input team $position $points;
datalines ;
A Guard 12
A Guard 20
A Guard 20
A Guard 24
A Forward 15
A Forward 15
A Forward 19
A Forward 28
B Guard 10
B Guard 12
B Guard 12
B Guard 26
B Forward 10
B Forward 10
B Forward 10
B Forward 19
;
run ;
/*view dataset*/
proc print data = original_data;
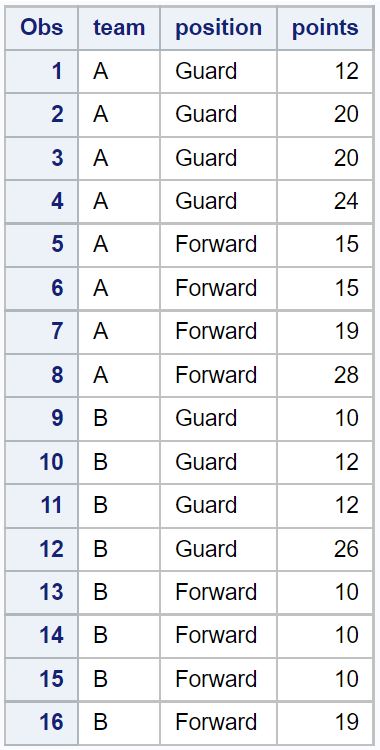
예시 1: 모든 열에서 중복 항목 제거
다음 코드를 사용하여 데이터세트의 모든 열에 중복된 값이 있는 행을 제거할 수 있습니다.
/*create dataset with no duplicate rows*/
proc sort data =original_data out =no_dups_data nodupkey ;
by _all_;
run ;
/*view dataset with no duplicate rows*/
proc print data =no_dups_data;
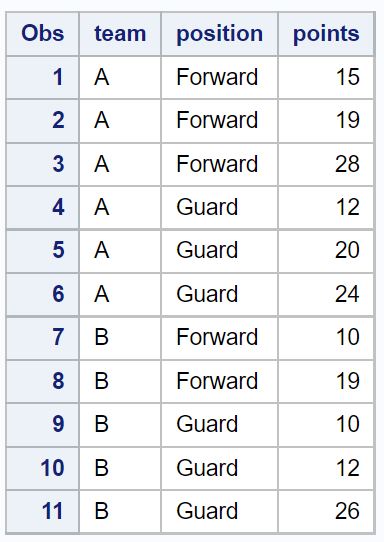
원본 데이터세트에서 총 5개의 중복 행이 제거되었습니다.
예시 2: 특정 열에서 중복 항목 제거
by 인수를 사용하여 중복 항목을 제거할 때 검사할 열을 지정할 수 있습니다.
예를 들어 다음 코드는 팀 및 직위 열에 중복된 값이 있는 행을 제거합니다.
/*create dataset with no duplicate rows in team and position columns*/
proc sort data =original_data out =no_dups_data nodupkey ;
by team position;
run ;
/*view dataset with no duplicate rows in team and position columns*/
proc print data =no_dups_data;
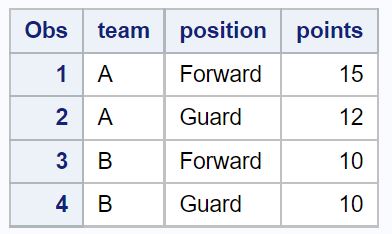
팀 및 직책 열에서 중복된 값이 있는 행을 제거한 후 데이터세트에는 4개의 행만 남습니다.
추가 리소스
다음 튜토리얼에서는 SAS에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
SAS에서 데이터를 정규화하는 방법
SAS에서 이상값을 식별하는 방법
SAS에서 절차 요약을 사용하는 방법
SAS에서 빈도표를 만드는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기