R에서 cramer-von mises 테스트를 수행하는 방법(예제 포함)
Cramer-Von Mises 검정은 표본이 정규 분포 에서 나오는지 여부를 확인하는 데 사용됩니다.
이 유형의 테스트는 주어진 데이터 세트가 회귀 , ANOVA , t-테스트 등을 포함한 많은 통계 테스트에서 일반적으로 사용되는 가정인 정규 분포에서 나오는지 여부를 결정하는 데 유용합니다. ‘다른 사람들.
R의 goftest 패키지에 있는 cvm.test() 함수를 사용하여 Cramer-Von Mises 테스트를 쉽게 수행할 수 있습니다.
다음 예에서는 이 기능을 실제로 사용하는 방법을 보여줍니다.
예 1: 정규 데이터에 대한 Cramer-Von Mises 검정
다음 코드는 샘플 크기 n=100인 데이터 세트에서 Cramer-Von Mises 테스트를 수행하는 방법을 보여줍니다.
library (goftest) #make this example reproducible set. seeds (0) #create dataset of 100 random values generated from a normal distribution data <- rnorm(100) #perform Cramer-Von Mises test for normality cvm. test (data, ' pnorm ') Cramer-von Mises test of goodness-of-fit Null hypothesis: Normal distribution Parameters assumed to be fixed data:data omega2 = 0.078666, p-value = 0.7007
테스트의 p-값은 0.7007 로 나타났습니다.
이 값은 0.05 이상이므로 표본 데이터가 정규 분포 모집단에서 나온 것이라고 가정할 수 있습니다.
표준 정규 분포 에서 임의의 값을 생성하는 rnorm() 함수를 사용하여 샘플 데이터를 생성했기 때문에 이 결과는 놀라운 일이 아닙니다.
관련 항목: R의 dnorm, pnorm, qnorm 및 rnorm에 대한 가이드
샘플 데이터가 정규 분포를 따르는지 시각적으로 확인하기 위해 히스토그램을 생성할 수도 있습니다.
hist(data, col=' steelblue ')
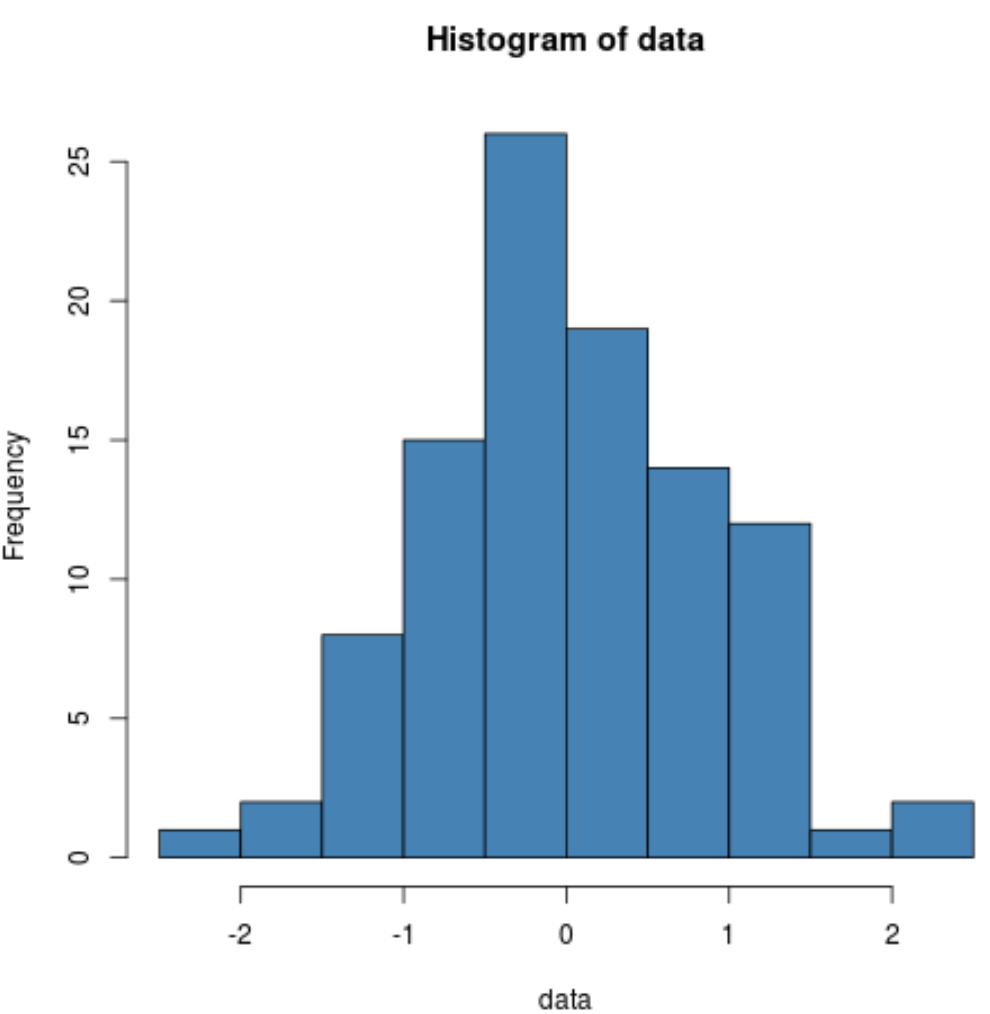
분포는 정규 분포 데이터의 전형적인 분포 중앙에 정점이 있는 종 모양임을 알 수 있습니다.
예 2: 비정규 데이터에 대한 Cramer-Von Mises 검정
다음 코드는 푸아송 분포 에서 값이 무작위로 생성되는 샘플 크기 100의 데이터 세트에 대해 Cramer-Von Mises 테스트를 수행하는 방법을 보여줍니다.
library (goftest) #make this example reproducible set. seeds (0) #create dataset of 100 random values generated from a Poisson distribution data <- rpois(n=100, lambda=3) #perform Cramer-Von Mises test for normality cvm. test (data, ' pnorm ') Cramer-von Mises test of goodness-of-fit Null hypothesis: Normal distribution Parameters assumed to be fixed data:data omega2 = 27.96, p-value < 2.2e-16
테스트의 p-값은 매우 낮은 것으로 나타났습니다.
이 값은 0.05보다 작기 때문에 표본 데이터가 정규 분포 모집단에서 나온 것이 아니라는 증거가 충분합니다.
푸아송 분포에서 임의의 값을 생성하는 rpois() 함수를 사용하여 샘플 데이터를 생성했기 때문에 이 결과는 놀라운 일이 아닙니다.
관련 항목: R의 dpois, ppois, qpois 및 rpois에 대한 가이드
샘플 데이터가 정규 분포를 따르지 않는지 시각적으로 확인하기 위해 히스토그램을 생성할 수도 있습니다.
hist(data, col=' coral2 ')
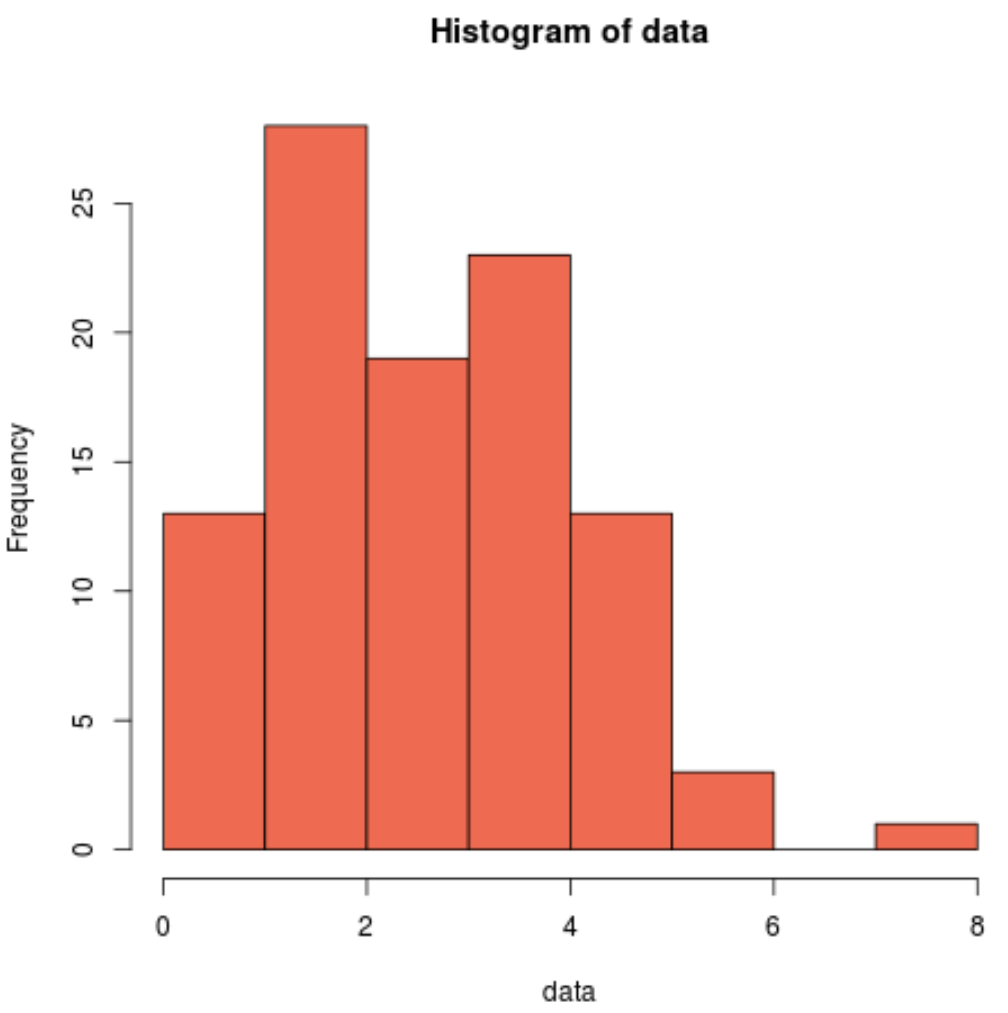
분포가 오른쪽으로 치우쳐 있고 정규 분포와 관련된 일반적인 “종 모양”이 없음을 알 수 있습니다.
따라서 히스토그램은 Cramer-Von Mises 테스트 결과와 일치하며 샘플 데이터가 정규 분포에서 나오지 않음을 확인합니다.
비정규 데이터로 무엇을 해야 할까요?
주어진 데이터 세트가 정규 분포를 따르지 않는 경우 다음 변환 중 하나를 수행하여 보다 정규 분포를 만들 수 있습니다.
1. 로그 변환: 응답 변수를 y에서 log(y) 로 변환합니다.
2. 제곱근 변환: 응답 변수를 y에서 √y 로 변환합니다.
3. 세제곱근 변환: 응답 변수를 y에서 y 1/3 으로 변환합니다.
이러한 변환을 수행하면 반응 변수는 일반적으로 정규 분포에 가까워집니다.
실제로 이러한 변환을 수행하는 방법을 보려면 이 튜토리얼을 참조하십시오.
추가 리소스
다음 튜토리얼에서는 R에서 다른 정규성 테스트를 수행하는 방법을 설명합니다.
R에서 Shapiro-Wilk 테스트를 수행하는 방법
R에서 Anderson-Darling 테스트를 수행하는 방법
R에서 Kolmogorov-Smirnov 테스트를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기