Sas에서 white의 테스트를 수행하는 방법
White의 테스트는 회귀 모델에 이분산성이 존재하는지 여부를 확인하는 데 사용됩니다.
이분산성은 회귀 모델에서 반응 변수 의 다양한 수준에서 잔차가 고르지 않게 분산되는 것을 의미하며, 이는 잔차가 반응 변수의 각 수준에서 동일하게 분산된다는 선형 회귀의 주요 가정 중 하나를 위반합니다.
이 튜토리얼에서는 SAS에서 White 테스트를 수행하여 주어진 회귀 모델에서 이분산성이 문제인지 여부를 확인하는 방법을 설명합니다.
예: SAS의 화이트 테스트
학생의 최종 시험 성적을 예측하기 위해 공부한 시간과 치른 연습 시험 횟수를 사용하는 다중 선형 회귀 모델을 적합화한다고 가정해 보겠습니다.
시험 점수 = β 0 + β 1 (시간) + β 2 (준비 시험)
먼저 다음 코드를 사용하여 학생 20명에 대한 이 정보가 포함된 데이터세트를 만듭니다.
/*create dataset*/ data exam_data; input hours prep_exams score; datalines ; 1 1 76 2 3 78 2 3 85 4 5 88 2 2 72 1 2 69 5 1 94 4 1 94 2 0 88 4 3 92 4 4 90 3 3 75 6 2 90 5 4 90 3 4 82 4 4 85 6 5 90 2 1 83 1 0 62 2 1 76 ; run ; /*view dataset*/ proc print data =exam_data;
다음으로 proc reg를 사용하여 이 다중 선형 회귀 모델을 적합하게 하고 spec 옵션을 사용하여 이분산성에 대한 White의 테스트를 수행합니다.
/*fit regression model and perform White's test*/
proc reg data =exam_data;
model score = hours prep_exams / spec ;
run ;
quit ;
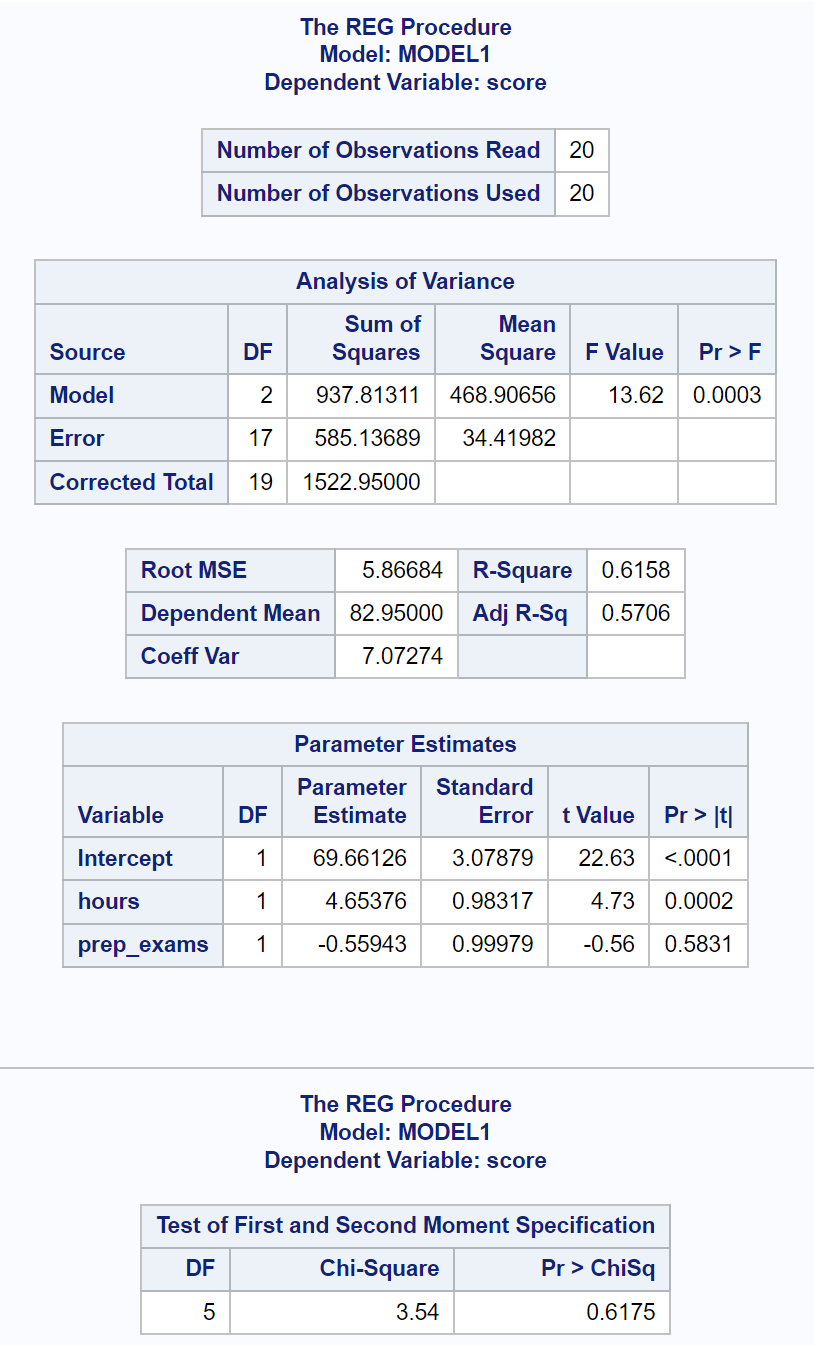
마지막 결과표는 White의 테스트 결과를 보여줍니다.
이 표에서 카이제곱 검정 통계량은 3.54 이고 해당 p-값은 0.6175 임을 알 수 있습니다.
White 테스트에서는 다음과 같은 귀무 가설과 대립 가설을 사용합니다.
- Null (H 0 ) : 이분산성이 존재하지 않습니다.
- 대안( HA ): 이분산성이 존재합니다.
p-값이 0.05 이상이므로 귀무가설을 기각할 수 없습니다.
이는 회귀 모델에 이분산성이 존재한다고 주장할 수 있는 충분한 증거가 없음을 의미합니다.
따라서 회귀 요약표에서 계수 추정치의 표준 오차를 안전하게 해석하는 것이 가능합니다.
다음에 무엇을할지
White 검정의 귀무가설을 기각하지 못하면 이분산성이 존재하지 않으며 계속해서 원래 회귀의 결과를 해석할 수 있습니다.
그러나 귀무 가설을 기각하면 데이터에 이분산성이 존재한다는 의미입니다. 이 경우 회귀 출력 테이블에 표시되는 표준 오류는 신뢰할 수 없습니다.
이 문제를 해결하는 몇 가지 일반적인 방법은 다음과 같습니다.
1. 반응 변수를 변환합니다. 반응 변수에 대한 변환을 시도할 수 있습니다.
예를 들어 원래 응답 변수 대신 로그 응답 변수를 사용할 수 있습니다.
일반적으로 반응변수의 로그를 취하는 것은 이분산성을 없애는 효과적인 방법이다.
또 다른 일반적인 변환은 반응 변수의 제곱근을 사용하는 것입니다.
2. 가중 회귀를 사용하십시오. 이 유형의 회귀는 적합치의 분산을 기반으로 각 데이터 포인트에 가중치를 할당합니다.
이는 분산이 더 높은 데이터 포인트에 작은 가중치를 부여하여 잔차 제곱을 줄입니다.
적절한 가중치를 사용하면 이분산성 문제를 해결할 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기