Stata에서 예측값과 잔차를 얻는 방법
선형 회귀 는 하나 이상의 설명 변수와 응답 변수 간의 관계를 이해하는 데 사용할 수 있는 방법입니다.
데이터 세트에 대해 선형 회귀를 수행하면 설명 변수의 값이 주어지면 응답 변수의 값을 예측하는 데 사용할 수 있는 회귀 방정식이 생성됩니다.
그런 다음 예측된 값과 실제 값의 차이를 측정하여 각 예측에 대한 잔차를 얻을 수 있습니다. 이는 회귀 모델이 응답 값을 얼마나 잘 예측하는지 파악하는 데 도움이 됩니다.
이 튜토리얼에서는 Stata에서 회귀 모델에 대한 예측값 과 잔차를 모두 구하는 방법을 설명합니다.
예: 예측값과 잔차를 구하는 방법
이 예에서는 auto 라는 내장 Stata 데이터 세트를 사용합니다. 설명변수로 mpg 와 변위를 사용하고 반응변수로 가격을 사용하겠습니다.
다음 단계를 사용하여 선형 회귀를 수행한 후 회귀 모델에 대한 예측 값과 잔차를 얻습니다.
1단계: 데이터를 로드하고 표시합니다.
먼저 다음 명령을 사용하여 데이터를 로드합니다.
시스템 자동 사용
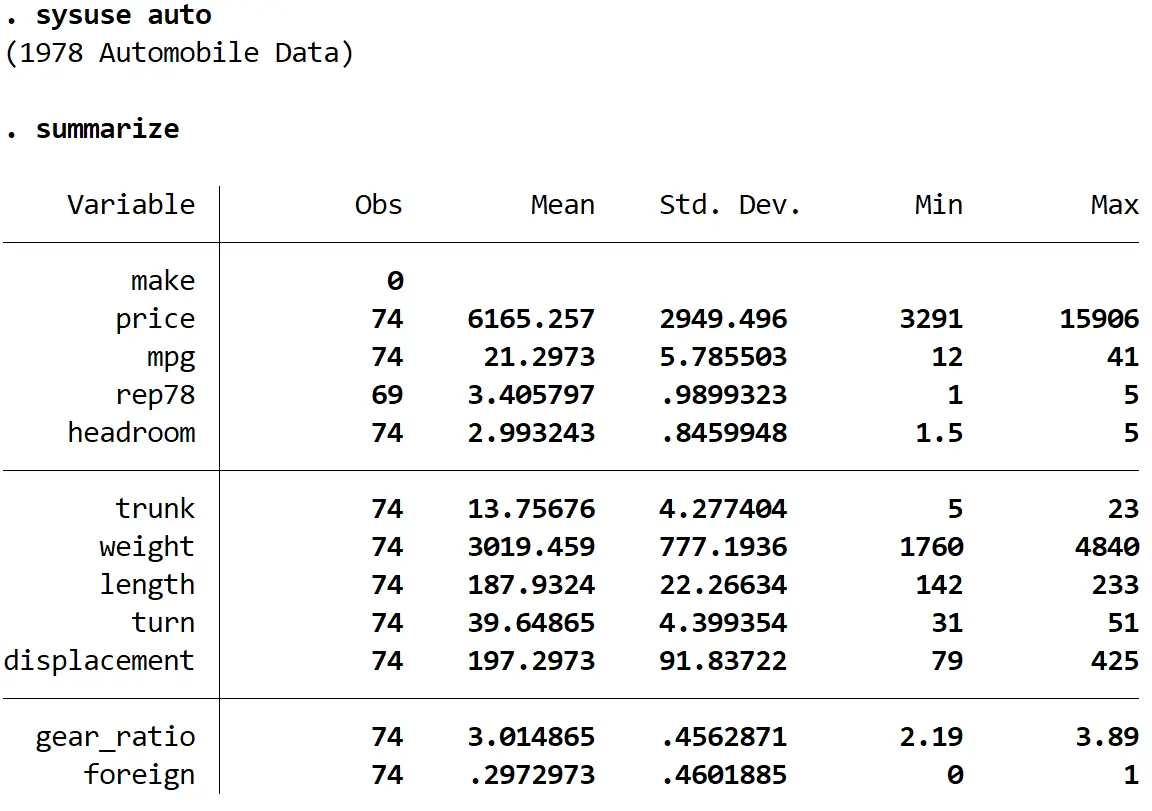
다음으로, 다음 명령을 사용하여 데이터에 대한 빠른 요약을 얻습니다.
요약
2단계: 회귀 모델을 적합시킵니다.
다음으로 회귀 모델을 맞추기 위해 다음 명령을 사용합니다.
회귀 가격 mpg 변위
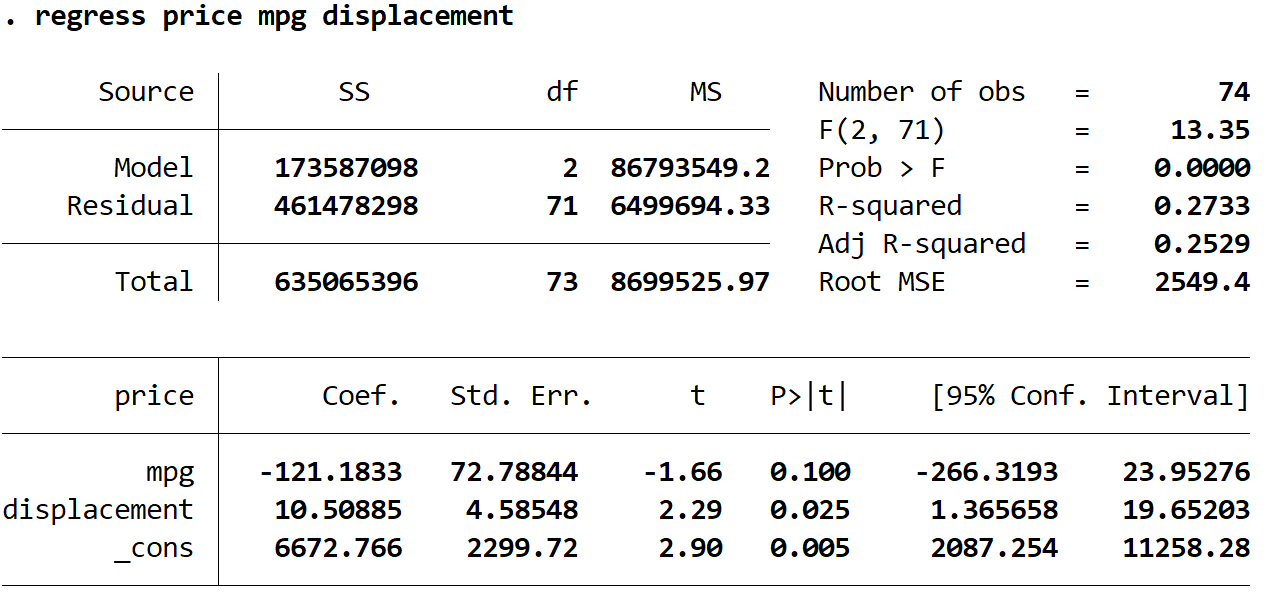
추정된 회귀 방정식은 다음과 같습니다.
예상 가격 = 6672.766 -121.1833*(mpg) + 10.50885*(배기량)
3단계: 예측 값을 가져옵니다.
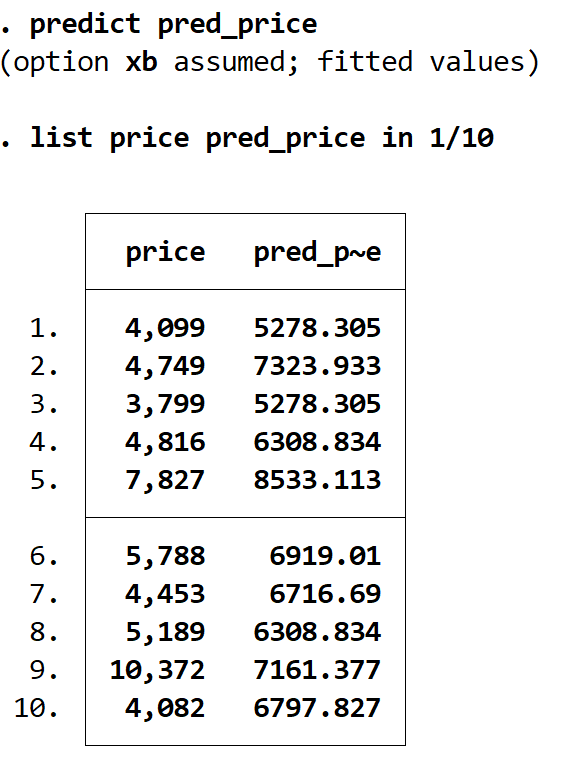
예측 명령을 사용하고 이 값을 원하는 이름의 변수에 저장하여 예측 값을 얻을 수 있습니다. 이 경우 pred_price라는 이름을 사용합니다.
pred_price 예측
list 명령을 사용하면 실제 가격과 예상 가격을 나란히 표시할 수 있습니다. 총 74개의 예측 값이 있지만 in 1/10 명령을 사용하여 처음 10개만 표시합니다.
1/10의 정가 pred_price
4단계: 잔여물을 얻으세요.
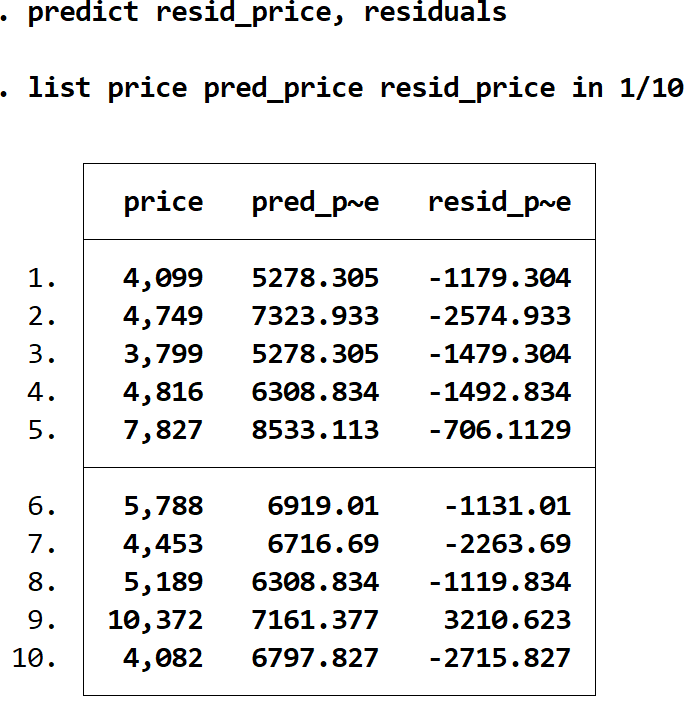
Residuals 명령을 사용하고 이 값을 원하는 이름의 변수에 저장하여 각 예측의 잔차를 얻을 수 있습니다. 이 경우 resid_price라는 이름을 사용합니다.
레지던시_가격, 잔차 예측
list 명령을 다시 사용하여 실제 가격, 예상 가격 및 잔차를 나란히 표시할 수 있습니다.
정가 pred_price 1/10의 resid_price
5단계: 잔차에 대한 예측값 플롯을 만듭니다.
마지막으로 예측값과 잔차 간의 관계를 시각화하기 위해 산점도를 만들 수 있습니다.
분산 Resident_price pred_price
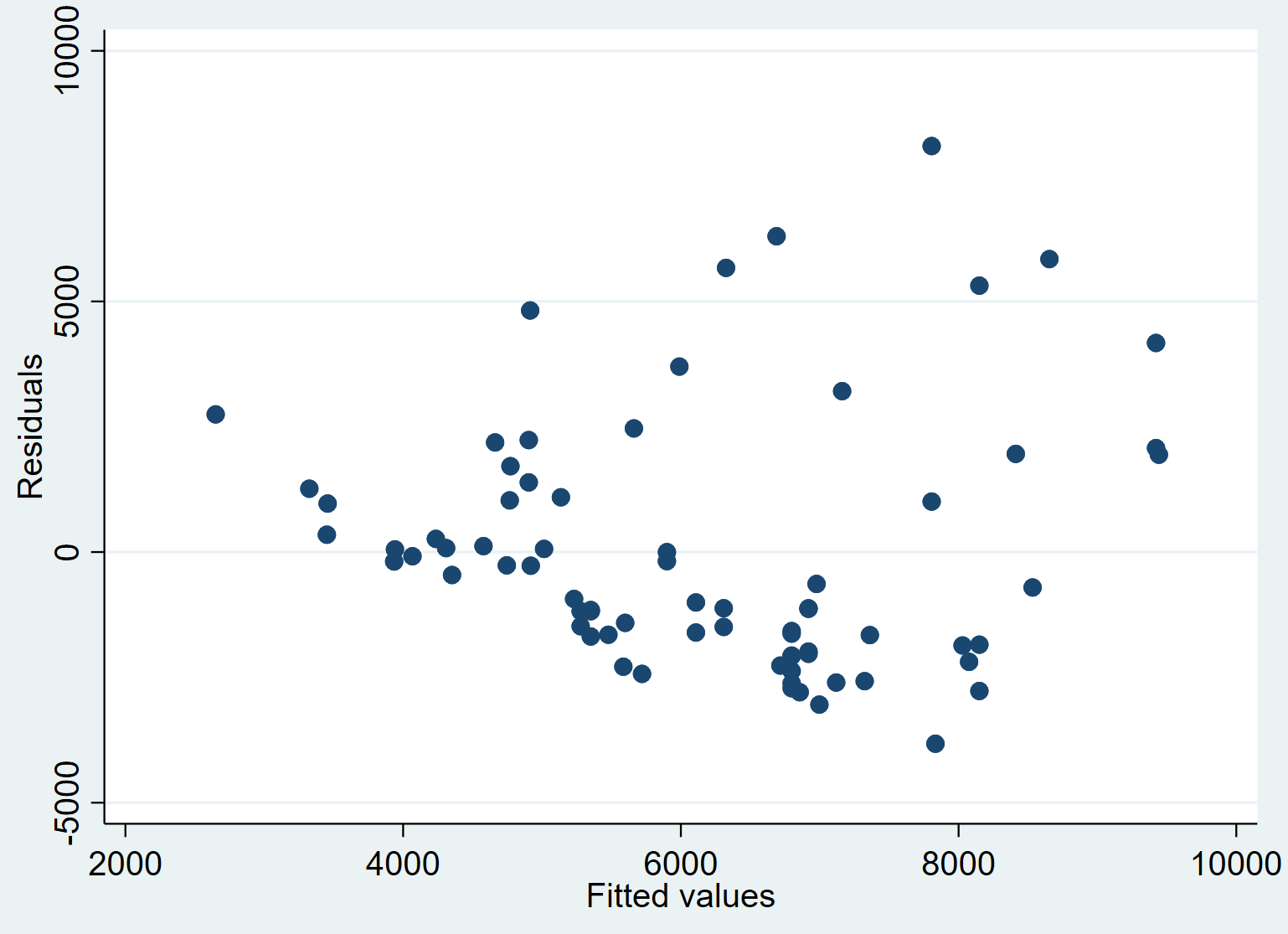
평균적으로 적합치가 증가함에 따라 잔차가 증가하는 경향이 있음을 알 수 있습니다. 이는 각 반응 수준에서 잔차 분포가 일정하지 않은 경우 이분산성 의 징후일 수 있습니다.
Breusch-Pagan 테스트를 사용하여 이분산성을 공식적으로 테스트하고 강력한 표준 오류를 사용하여 이를 해결할 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기