Pandas: 행당 열 수가 다른 csv 가져오기
행당 열 수가 다른 경우 다음 기본 구문을 사용하여 CSV 파일을 Pandas로 가져올 수 있습니다.
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
range() 함수 내부의 값은 최대 열 수가 있는 행의 열 수여야 합니다.
다음 예에서는 실제로 이 구문을 사용하는 방법을 보여줍니다.
예: 행당 열 수가 다른 Pandas로 CSV 가져오기
even_data.csv 라는 다음과 같은 CSV 파일이 있다고 가정해 보겠습니다.
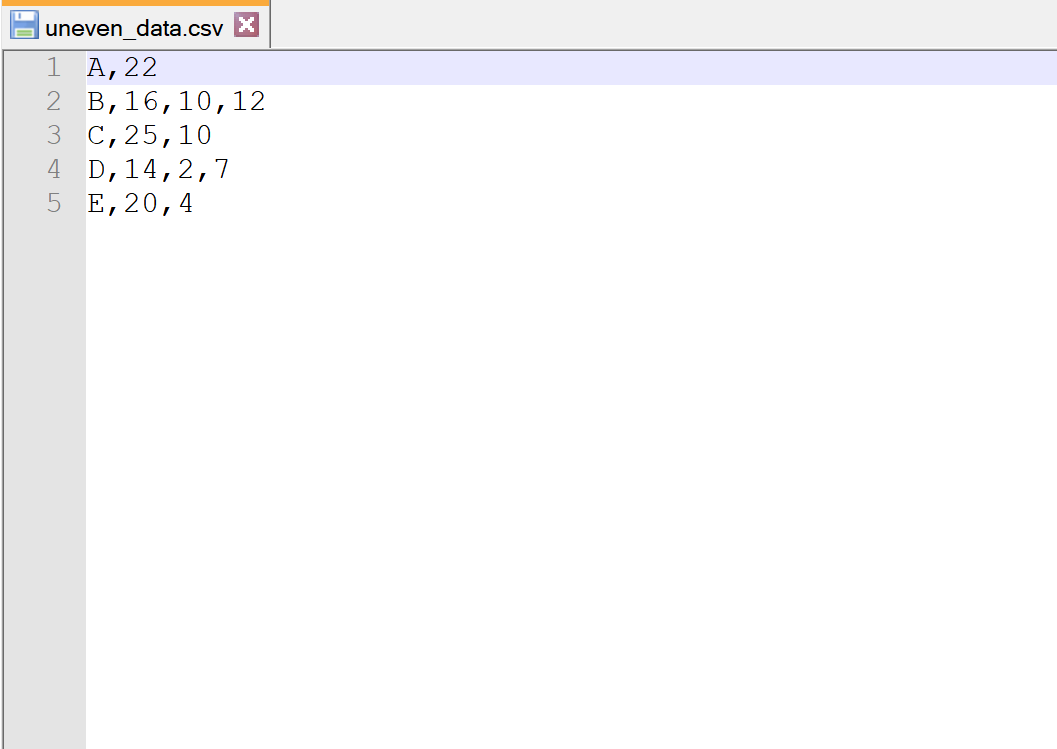
각 행의 열 개수는 동일하지 않습니다.
read_csv() 함수를 사용하여 이 CSV 파일을 pandas DataFrame으로 가져오려고 하면 오류가 발생합니다.
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
우리는 Pandas가 2개의 필드(첫 번째 행의 열 수이기 때문에)를 예상했지만 4개 를 확인했음을 알려주는 ParserError를 수신합니다.
이 오류는 주어진 행의 최대 열 수가 4 임을 알려줍니다.
따라서 CSV 파일을 가져오고 이름 인수에 range(4) 값을 제공할 수 있습니다.
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
pandas에 4개의 열이 필요하다고 명시적으로 지시했기 때문에 오류 없이 CSV 파일을 pandas DataFrame으로 성공적으로 가져올 수 있습니다.
기본적으로 pandas는 각 행의 모든 누락된 값을 NaN으로 채웁니다.
누락된 값을 0으로 표시하려면 다음과 같이 fillna() 함수를 사용하면 됩니다.
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
이제 DataFrame의 각 NaN 값이 0으로 대체되었습니다.
참고 : 여기에서 pandas read_csv() 함수에 대한 전체 문서를 찾을 수 있습니다.
추가 리소스
다음 튜토리얼에서는 Python에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
Pandas: CSV 파일을 읽을 때 줄을 건너뛰는 방법
Pandas: 기존 CSV 파일에 데이터를 추가하는 방법
Pandas: CSV 파일을 가져올 때 유형을 지정하는 방법
Pandas: CSV 파일을 가져올 때 열 이름 설정
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기