확률 분포의 유형
이 문서에서는 통계의 다양한 유형의 확률 분포에 대해 설명합니다. 따라서 확률 분포에는 몇 가지 유형이 있으며, 이들 간의 차이점은 무엇인지 알아볼 것입니다.
확률 분포의 유형은 무엇입니까?
확률 분포의 유형은 다음과 같습니다.
- 이산 확률 분포 :
- 이산 균일 분포 .
- 베르누이 분포 .
- 이항 분포 .
- 생선 유통 .
- 다항 분포 .
- 기하학적 분포 .
- 음이항 분포 .
- 초기하 분포 .
- 연속 확률 분포 :
- 균일하고 연속적인 분포 .
- 정규 분포 .
- 대수정규분포 .
- 카이제곱 분포 .
- 스튜던트 t 분포 .
- 배급 스네데코 F.
- 지수 분포 .
- 베타 배포 .
- 감마 분포 .
- 와이블 분포 .
- 파레토 분포 .
각 유형의 확률 분포는 아래에 자세히 설명되어 있습니다.
이산 확률 분포
이산 확률 분포는 이산 확률 변수의 확률을 정의하는 분포입니다. 따라서 이산형 확률 분포는 유한한 수의 값(보통 정수 값)만 취할 수 있습니다.
이산 균일 분포
이산균등분포(Discrete 균등분포) 는 모든 값이 등확률을 갖는 이산확률분포, 즉 이산균일분포에서는 모든 값이 동일한 확률로 발생하는 분포를 말한다.
예를 들어, 주사위 굴림은 모든 가능한 결과(1, 2, 3, 4, 5 또는 6)가 동일한 발생 확률을 갖기 때문에 이산 균일 분포로 정의될 수 있습니다.
일반적으로 이산 균일 분포에는 분포가 취할 수 있는 가능한 값의 범위를 정의하는 두 가지 특성 매개변수 a 와 b 가 있습니다. 따라서 변수가 이산 균등분포로 정의되면 균일(a,b) 로 작성됩니다.

이산 균일 분포는 무작위 실험을 설명하는 데 사용될 수 있습니다. 왜냐하면 모든 결과가 동일한 확률을 갖는다면 실험에 무작위성이 있음을 의미하기 때문입니다.
베르누이 분포
이분 분포 라고도 알려진 베르누이 분포는 “성공” 또는 “실패”라는 두 가지 결과만 가질 수 있는 이산형 변수를 나타내는 확률 분포입니다.
베르누이 분포에서 “성공”은 우리가 기대하는 결과이고 값이 1인 반면, “실패”의 결과는 기대한 것과 다른 결과이며 값이 0입니다. 따라서 ” 성공”은 p 이고, “실패” 결과의 확률은 q=1-p 입니다.
![\begin{array}{c}X\sim \text{Bernoulli}(p)\\[2ex]\begin{array}{l} \text{\'Exito}\ \color{orange}\bm{\longrightarrow}\color{black} \ P[X=1]=p\\[2ex]\text{Fracaso}\ \color{orange}\bm{\longrightarrow}\color{black} \ P[X=0]=q=1-p\end{array}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-384fd7d96d4d6584739b04a6e331b251_l3.png "Rendered by QuickLaTeX.com")
베르누이 분포는 스위스 통계학자 Jacob Bernoulli의 이름을 따서 명명되었습니다.
통계에서 베르누이 분포는 주로 성공과 실패라는 두 가지 가능한 결과만 있는 실험의 확률을 정의하는 용도로 사용됩니다. 따라서 베르누이 분포를 사용하는 실험을 베르누이 테스트 또는 베르누이 실험이라고 합니다.
이항 분포
이항 분포 라고도 하는 이항 분포 는 일정한 성공 확률을 사용하여 일련의 독립적인 이분법적 실험을 수행할 때 성공 횟수를 계산하는 확률 분포입니다. 즉, 이항 분포는 일련의 베르누이 시행에서 성공적인 결과의 수를 설명하는 분포입니다.
예를 들어, 동전이 앞면이 25번 나오는 횟수는 이항 분포입니다.
일반적으로 수행된 총 실험 수는 매개변수 n 으로 정의되며, p 는 각 실험의 성공 확률입니다. 따라서 이항 분포를 따르는 확률 변수는 다음과 같이 작성됩니다.

이항 분포에서는 완전히 동일한 실험이 n 번 반복되고 실험이 서로 독립적이므로 각 실험의 성공 확률은 동일합니다 (p) .
생선 유통
포아송 분포는 일정 기간 내에 특정 수의 사건이 발생할 확률을 정의하는 확률 분포입니다. 즉, 포아송 분포는 시간 간격에서 현상이 반복되는 횟수를 설명하는 확률 변수를 모델링하는 데 사용됩니다.
예를 들어, 전화 교환기에 의해 분당 수신된 전화 수는 포아송 분포를 사용하여 정의할 수 있는 이산 확률 변수입니다.
푸아송 분포에는 그리스 문자 λ로 표시되는 특성 매개변수가 있으며, 이는 연구된 사건이 주어진 간격 동안 발생할 것으로 예상되는 횟수를 나타냅니다.

다항 분포
다항 분포 (또는 다항 분포 )는 여러 번의 시행을 수행한 후 지정된 횟수만큼 여러 배타적 사건이 발생할 확률을 설명하는 확률 분포입니다.
즉, 무작위 실험에서 3개 이상의 배타적 사건이 발생할 수 있고 각 사건이 개별적으로 발생할 확률을 알고 있는 경우, 여러 실험을 수행할 때 특정 수의 사건이 발생할 확률을 계산하기 위해 다항 분포를 사용합니다. 각 이벤트의 횟수입니다.
따라서 다항 분포는 이항 분포를 일반화한 것입니다.
기하학적 분포
기하 분포는 첫 번째 성공적인 결과를 얻는 데 필요한 베르누이 시행 횟수를 정의하는 확률 분포입니다. 즉, 베르누이 실험 중 하나가 긍정적인 결과를 얻을 때까지 반복되는 기하학적 분포 모델 프로세스입니다.
예를 들어, 노란색 자동차를 볼 때까지 고속도로를 지나가는 자동차의 수는 기하학적 분포입니다.
베르누이 테스트는 “성공”과 “실패”라는 두 가지 결과를 얻을 수 있는 실험이라는 점을 기억하세요. 따라서 “성공” 확률이 p 라면 “실패” 확률은 q=1-p 입니다.
따라서 기하학적 분포는 수행된 모든 실험의 성공 확률인 매개변수 p 에 따라 달라집니다. 또한 확률 p는 모든 실험에서 동일합니다.

음이항 분포
음이항 분포는 주어진 양의 결과를 얻는 데 필요한 베르누이 시행 횟수를 설명하는 확률 분포입니다.
따라서 음이항 분포에는 두 가지 특성 매개변수가 있습니다. r 은 원하는 성공적인 결과 수이고 p 는 수행된 각 Bernoulli 실험의 성공 확률입니다.

따라서 음이항 분포는 긍정적인 결과를 얻기 위해 필요한 만큼 많은 베르누이 시행을 수행하는 과정을 정의합니다. 게다가 이러한 베르누이 시행은 모두 독립적이며 일정한 성공 확률을 갖습니다.
예를 들어, 음이항 분포를 따르는 확률 변수는 숫자 6이 3번이 될 때까지 주사위를 굴려야 하는 횟수입니다.
초기하 분포
초기하 분포는 모집단에서 n개의 요소를 대체하지 않고 무작위 추출에서 성공한 사례 수를 설명하는 확률 분포입니다.
즉, 초기하 분포는 모집단에서 n 개의 요소를 대체하지 않고 추출할 때 x개의 성공을 얻을 확률을 계산하는 데 사용됩니다.
따라서 초기하 분포에는 세 가지 매개변수가 있습니다.
- N : 모집단의 요소 수입니다(N = 0, 1, 2,…).
- K : 최대 성공 사례 수입니다(K = 0, 1, 2,…,N). 초기하 분포에서는 요소가 “성공” 또는 “실패”로만 간주될 수 있으므로 NK 는 최대 실패 사례 수입니다.
- n : 수행된 비대체 가져오기 횟수입니다.

연속 확률 분포
연속 확률 분포는 소수 값을 포함하여 구간에서 모든 값을 취할 수 있는 분포입니다. 따라서 연속 확률 분포는 연속 확률 변수의 확률을 정의합니다.
균일하고 연속적인 분포
직사각형 분포라고도 불리는 연속 균등 분포는 모든 값이 동일한 발생 확률을 갖는 연속 확률 분포의 한 유형입니다. 즉, 연속 균일 분포는 확률이 구간에 걸쳐 균일하게 분포되는 분포입니다.
연속 균일 분포는 일정한 확률을 갖는 연속 변수를 설명하는 데 사용됩니다. 마찬가지로, 연속 균일 분포는 무작위 프로세스를 정의하는 데 사용됩니다. 왜냐하면 모든 결과가 동일한 확률을 갖는다면 결과에 무작위성이 있음을 의미하기 때문입니다.
연속 균일 분포에는 등확률 구간을 정의하는 두 가지 특성 매개변수 a 와 b가 있습니다. 따라서 연속균등분포의 기호는 U(a,b) 이며, 여기서 a 와 b 는 분포의 특성값이다.

예를 들어, 무작위 실험의 결과가 5에서 9 사이의 값을 가질 수 있고 가능한 모든 결과가 동일한 발생 확률을 갖는 경우 실험은 연속 균일 분포 U(5.9)로 시뮬레이션될 수 있습니다.
정규 분포
정규 분포는 그래프가 종 모양이고 평균에 대해 대칭인 연속 확률 분포입니다. 통계에서 정규 분포는 매우 다른 특성을 가진 현상을 모델링하는 데 사용되므로 이 분포가 매우 중요합니다.
실제로 통계에서 정규분포는 모든 확률분포 중에서 단연 가장 중요한 분포로 간주됩니다. 정규분포를 사용하면 수많은 실제 현상을 모델링할 수 있을 뿐만 아니라 정규분포를 사용하여 다른 유형의 분포를 근사화할 수도 있기 때문입니다. 특정 조건에서.
정규분포의 기호는 대문자 N입니다. 따라서 변수가 정규분포를 따른다는 것을 나타내기 위해 N으로 표시하고 그 산술평균과 표준편차의 값을 괄호 안에 추가합니다.

정규 분포에는 가우스 분포 , 가우스 분포 , 라플라스-가우스 분포 등 다양한 이름이 있습니다.
대수정규분포
로그 정규 분포 또는 로그 정규 분포는 로그가 정규 분포를 따르는 확률 변수를 정의하는 확률 분포입니다.
따라서 변수 X가 정규 분포를 갖는 경우 지수 함수 e x는 로그 정규 분포를 갖습니다.

로그 정규분포는 변수 값이 양수인 경우에만 사용할 수 있다는 점에 유의하세요. 로그는 양수 인수를 하나만 취하는 함수이기 때문입니다.
통계에서 로그 정규 분포를 다양하게 적용하는 것 중에서 금융 투자를 분석하고 신뢰도 분석을 수행하기 위해 이 분포를 사용하는 것을 구별합니다.
로그 정규 분포는 Tinaut 분포 라고도 하며 때로는 로그 정규 분포 또는 로그 정규 분포 라고도 작성됩니다.
카이제곱 분포
카이제곱 분포는 기호가 χ²인 확률 분포입니다. 보다 정확하게는 카이제곱 분포는 k개의 독립 확률 변수의 제곱을 정규 분포와 합한 것입니다.
따라서 카이제곱 분포는 k 개의 자유도를 갖습니다. 따라서 카이제곱 분포는 그것이 나타내는 정규 분포 변수의 제곱의 합만큼 많은 자유도를 갖습니다.
![\displaystyle X\sim\chi^2_k \ \color{orange}\bm{\longrightarrow}\color{black}\ \begin{array}{l}\text{Distribuci\'on chi-cuadrado}\\[2ex]\text{con k grados de libertad}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9ea0bf7a87071883ceae5e419bae9e71_l3.png "Rendered by QuickLaTeX.com")
카이제곱 분포는 피어슨 분포 라고도 합니다.
카이제곱 분포는 가설 검정 및 신뢰 구간과 같은 통계적 추론에 널리 사용됩니다. 이러한 유형의 확률 분포가 어떻게 적용되는지 아래에서 살펴보겠습니다.
스튜던트 t 분포
스튜던트 t 분포는 통계학에서 널리 사용되는 확률 분포입니다. 특히 스튜던트 t 분포는 스튜던트 t 검정에서 두 표본 평균 간의 차이를 확인하고 신뢰 구간을 설정하는 데 사용됩니다.
스튜던트 t 분포는 1908년 통계학자인 William Sealy Gosset이 “Student”라는 가명으로 개발했습니다.
스튜던트 t 분포는 총 관측치 수에서 1단위를 빼서 얻은 자유도 수로 정의됩니다. 따라서 스튜던트 t 분포의 자유도를 결정하는 공식은 ν=n-1 입니다.
![\begin{array}{c}\nu=n-1\\[2ex]X\sim t_\nu\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1c805dc2d6ca050feb70dad99de53402_l3.png "Rendered by QuickLaTeX.com")
스네데코 F 유통
피셔-스네데코 F 분포 또는 간단히 F 분포 라고도 하는 스네데코 F 분포는 통계적 추론, 특히 분산 분석에 사용되는 연속 확률 분포입니다.
Snedecor F 분포의 속성 중 하나는 자유도를 나타내는 두 개의 실수 매개변수 m 과 n 의 값으로 정의된다는 것입니다. 따라서 Snedecor 분포 F의 기호는 F m,n 입니다. 여기서 m 과 n 은 분포를 정의하는 매개변수입니다.
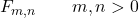
![\left.\begin{array}{c} X\sim \chi_m^2\\[2ex] Y\sim \chi_n^2\end{array}\right\}\color{orange}\bm{\longrightarrow}\color{black}\ F_{m,n}= \cfrac{X/m}{Y/n}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d407869e61ca4357ffbcb40df3bd83ab_l3.png "Rendered by QuickLaTeX.com")
Fisher-Snedecor F 분포는 영국 통계학자 Ronald Fisher와 미국 통계학자 George Snedecor의 이름을 따서 명명되었습니다.
통계에서 Fisher-Snedecor F 분포는 다양한 용도로 사용됩니다. 예를 들어, Fisher-Snedecor F 분포는 다양한 선형 회귀 모델을 비교하는 데 사용되며 이 확률 분포는 분산 분석(ANOVA)에 사용됩니다.
지수분포
지수 분포는 무작위 현상이 발생할 때까지의 대기 시간을 모델링하는 데 사용되는 연속 확률 분포입니다.
보다 정확하게는 지수 분포를 통해 포아송 분포를 따르는 두 사건 간의 대기 시간을 설명할 수 있습니다. 따라서 지수 분포는 포아송 분포와 밀접한 관련이 있습니다.
지수 분포는 그리스 문자 λ로 표시되는 특성 매개변수를 가지며, 연구된 사건이 주어진 기간 동안 발생할 것으로 예상되는 횟수를 나타냅니다.

마찬가지로, 지수 분포는 고장이 발생할 때까지의 시간을 모델링하는 데에도 사용됩니다. 따라서 지수 분포는 신뢰성 및 생존 이론에서 여러 가지 응용 프로그램을 갖습니다.
베타 배포
베타 분포는 구간 (0,1)에서 정의되고 두 개의 양수 매개변수인 α와 β로 매개변수화되는 확률 분포입니다. 즉, 베타 분포의 값은 매개변수 α와 β에 따라 달라집니다.
따라서 베타 분포는 값이 0에서 1 사이인 연속 확률 변수를 정의하는 데 사용됩니다.
연속 확률 변수가 베타 분포의 영향을 받는다는 것을 나타내는 몇 가지 표기법이 있으며, 가장 일반적인 표기법은 다음과 같습니다.
![\begin{array}{c}X\sim B(\alpha,\beta)\\[2ex]X\sim Beta(\alpha,\beta)\\[2ex]X\sim \beta_{\alpha,\beta}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-ee1d0d8a1624a017b8ef9ce8a67c694e_l3.png "Rendered by QuickLaTeX.com")
통계에서 베타 배포판은 매우 다양한 용도로 사용됩니다. 예를 들어, 베타 분포는 다양한 표본의 백분율 변화를 연구하는 데 사용됩니다. 마찬가지로 프로젝트 관리에서는 베타 배포를 사용하여 Pert 분석을 수행합니다.
감마 분포
감마 분포는 두 가지 특성 매개변수 α와 λ로 정의되는 연속 확률 분포입니다. 즉, 감마 분포는 두 매개변수의 값에 따라 달라집니다. α는 모양 매개변수이고 λ는 척도 매개변수입니다.
감마 분포의 기호는 그리스 대문자 Γ입니다. 따라서 확률 변수가 감마 분포를 따르는 경우 다음과 같이 작성됩니다.

감마 분포는 형상 매개변수 k = α 및 역 스케일 매개변수 θ = 1/λ를 사용하여 매개변수화할 수도 있습니다. 모든 경우에 감마 분포를 정의하는 두 매개변수는 양의 실수입니다.
일반적으로 감마 분포는 오른쪽으로 치우친 데이터 세트를 모델링하는 데 사용되므로 그래프 왼쪽에 데이터가 더 많이 집중됩니다. 예를 들어, 감마 분포는 전기 부품의 신뢰성을 모델링하는 데 사용됩니다.
와이블 분포
Weibull 분포는 형상 매개변수 α와 척도 매개변수 λ라는 두 가지 특성 매개변수로 정의되는 연속 확률 분포입니다.
통계에서는 생존분석을 위해 주로 Weibull 분포를 사용합니다. 마찬가지로 Weibull 분포는 다양한 분야에 많이 적용됩니다.

저자에 따르면 Weibull 분포는 세 가지 매개변수를 사용하여 매개변수화할 수도 있습니다. 그런 다음 분포 그래프가 시작되는 가로좌표를 나타내는 임계값이라는 세 번째 매개변수가 추가됩니다.
Weibull 분포는 1951년에 이를 자세히 설명한 스웨덴 Waloddi Weibull의 이름을 따서 명명되었습니다. 그러나 Weibull 분포는 1927년 Maurice Fréchet에 의해 발견되었고 1933년 Rosin과 Rammler에 의해 처음 적용되었습니다.
파레토 분포
파레토 분포는 통계에서 파레토 원리를 모형화하는 데 사용되는 연속 확률 분포입니다. 따라서 파레토 분포는 나머지 값보다 발생 확률이 훨씬 높은 몇 가지 값을 갖는 확률 분포입니다.
80-20 법칙이라고도 불리는 파레토의 법칙은 현상의 대부분 원인이 소수의 인구에 기인한다는 통계적 원리라는 것을 기억하세요.
파레토 분포에는 척도 매개변수 x m 과 모양 매개변수 α라는 두 가지 특성 매개변수가 있습니다.

원래 파레토 분포는 인구 내 부의 분포를 설명하는 데 사용되었습니다. 그 이유는 부의 대부분이 인구의 작은 부분에 기인하기 때문입니다. 그러나 현재 파레토 분포는 품질 관리, 경제, 과학, 사회 분야 등 다양한 분야에 적용됩니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기