R에서 2차 회귀를 수행하는 방법
두 변수가 선형 관계를 갖는 경우 단순 선형 회귀를 사용하여 관계를 정량화할 수 있는 경우가 많습니다.
그러나 두 변수가 2차 관계를 갖는 경우 2차 회귀를 사용하여 관계를 정량화할 수 있습니다.
이 튜토리얼에서는 R에서 2차 회귀를 수행하는 방법을 설명합니다.
예: R의 2차 회귀
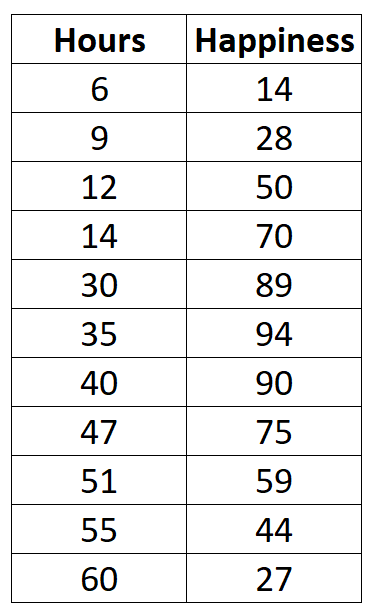
근무 시간과 보고된 행복 사이의 관계를 이해하고 싶다고 가정해 보겠습니다. 우리는 11명의 서로 다른 사람들에 대한 주당 근무 시간과 보고된 행복 수준(0~100점)에 대한 다음과 같은 데이터를 가지고 있습니다.
R에서 2차 회귀 모델을 맞추려면 다음 단계를 사용하세요.
1단계: 데이터를 입력합니다.
먼저 데이터가 포함된 데이터 프레임을 만듭니다.
#createdata data <- data.frame(hours=c(6, 9, 12, 14, 30, 35, 40, 47, 51, 55, 60), happiness=c(14, 28, 50, 70, 89, 94, 90, 75, 59, 44, 27)) #viewdata data hours happiness 1 6 14 2 9 28 3 12 50 4 14 70 5 30 89 6 35 94 7 40 90 8 47 75 9 51 59 10 55 44 11 60 27
2단계: 데이터를 시각화합니다.
다음으로, 데이터를 시각화하기 위해 간단한 산점도를 만들어 보겠습니다.
#create scatterplot
plot(data$hours, data$happiness, pch=16)
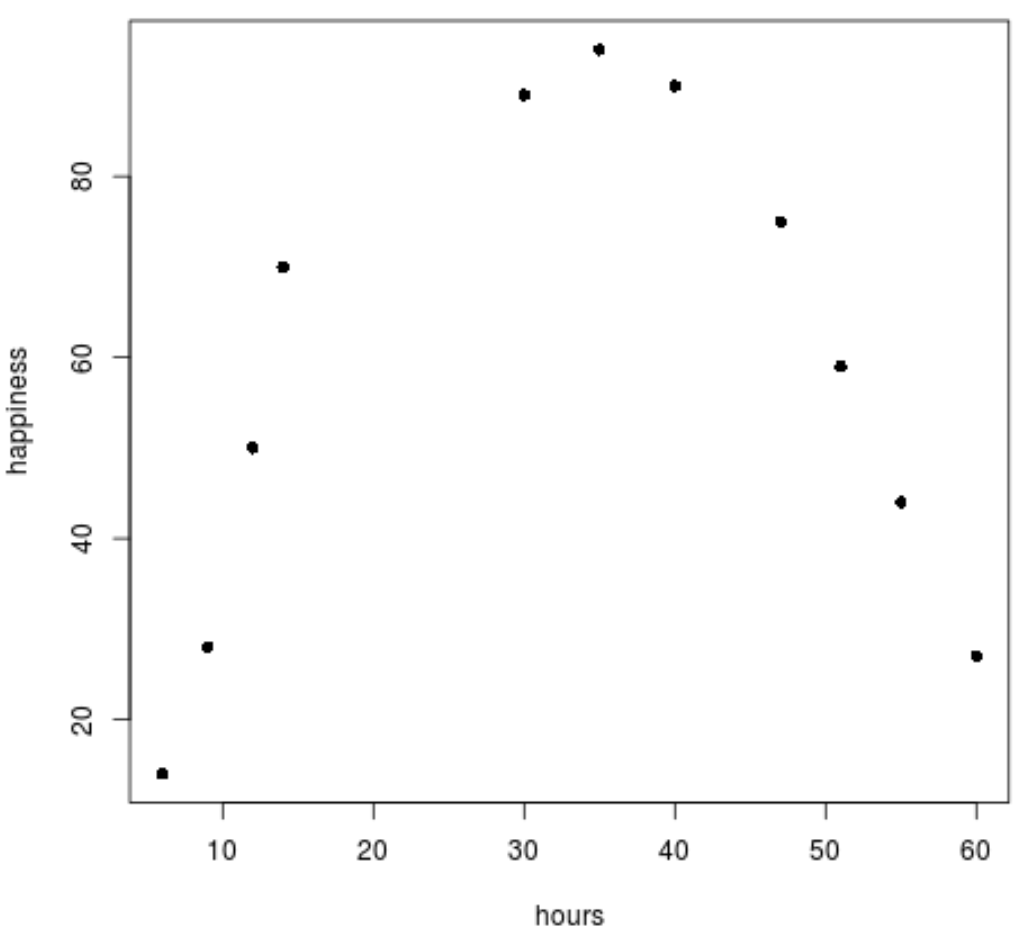
데이터가 선형 패턴을 따르지 않는다는 것을 분명히 알 수 있습니다.
3단계: 단순 선형 회귀 모델을 피팅합니다.
다음으로 간단한 선형 회귀 모델을 피팅하여 데이터에 얼마나 잘 맞는지 확인하겠습니다.
#fit linear model linearModel <- lm(happiness ~ hours, data=data) #view model summary summary(linearModel) Call: lm(formula = happiness ~ hours) Residuals: Min 1Q Median 3Q Max -39.34 -21.99 -2.03 23.50 35.11 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 48.4531 17.3288 2.796 0.0208 * hours 0.2981 0.4599 0.648 0.5331 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 28.72 on 9 degrees of freedom Multiple R-squared: 0.0446, Adjusted R-squared: -0.06156 F-statistic: 0.4201 on 1 and 9 DF, p-value: 0.5331
다중 R-제곱 값으로 표시되는 것처럼 모델이 설명하는 행복의 총 분산은 4.46% 에 불과합니다.
4단계: 2차 회귀 모델을 피팅합니다.
다음으로 2차 회귀 모델을 피팅하겠습니다.
#create a new variable for hours 2 data$hours2 <- data$hours^2 #fit quadratic regression model quadraticModel <- lm(happiness ~ hours + hours2, data=data) #view model summary summary(quadraticModel) Call: lm(formula = happiness ~ hours + hours2, data = data) Residuals: Min 1Q Median 3Q Max -6.2484 -3.7429 -0.1812 1.1464 13.6678 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -18.25364 6.18507 -2.951 0.0184 * hours 6.74436 0.48551 13.891 6.98e-07 *** hours2 -0.10120 0.00746 -13.565 8.38e-07 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 6.218 on 8 degrees of freedom Multiple R-squared: 0.9602, Adjusted R-squared: 0.9502 F-statistic: 96.49 on 2 and 8 DF, p-value: 2.51e-06
모델이 설명하는 행복의 총 분산은 96.02% 로 증가했습니다.
다음 코드를 사용하여 모델이 데이터에 얼마나 잘 맞는지 시각화할 수 있습니다.
#create sequence of hour values hourValues <- seq(0, 60, 0.1) #create list of predicted happiness levels using quadratic model happinessPredict <- predict(quadraticModel, list(hours=hourValues, hours2=hourValues^2)) #create scatterplot of original data values plot(data$hours, data$happiness, pch=16) #add predicted lines based on quadratic regression model lines(hourValues, happinessPredict, col='blue')
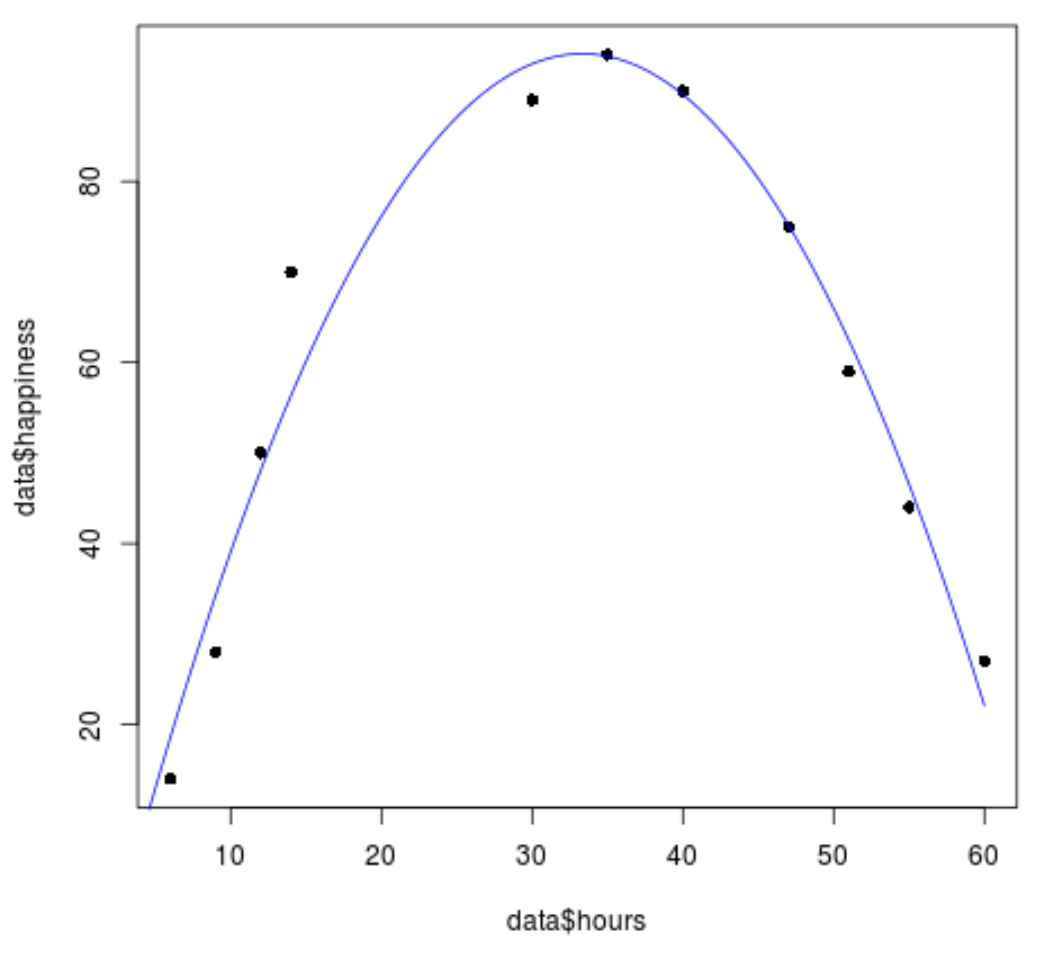
2차 회귀선이 데이터 값과 꽤 잘 맞는 것을 확인할 수 있습니다.
5단계: 2차 회귀 모델을 해석합니다.
이전 단계에서 2차 회귀 모델의 결과는 다음과 같습니다.
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -18.25364 6.18507 -2.951 0.0184 *
hours 6.74436 0.48551 13.891 6.98e-07 ***
hours2 -0.10120 0.00746 -13.565 8.38e-07 ***
여기에 제시된 계수를 기반으로 조정된 2차 회귀는 다음과 같습니다.
행복 = -0.1012(시간) 2 + 6.7444(시간) – 18.2536
우리는 이 방정식을 사용하여 개인의 주당 근무 시간을 바탕으로 개인의 예상 행복을 찾을 수 있습니다.
예를 들어, 주당 60시간 일하는 사람의 행복 수준은 22.09 입니다.
행복 = -0.1012(60) 2 + 6.7444(60) – 18.2536 = 22.09
반대로 주당 30시간 일하는 사람의 행복지수는 92.99 이다.
행복 = -0.1012(30) 2 + 6.7444(30) – 18.2536 = 92.99
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기