집계 편향이란 무엇입니까? (설명 및 예시)
집계 편향은 집계된 데이터에서 관찰된 추세가 개별 데이터 포인트에도 적용되는 것으로 잘못 가정할 때 발생합니다.
이러한 유형의 편향을 이해하는 가장 쉬운 방법은 간단한 예를 드는 것입니다.
예: 집계 편향
연구자들이 특정 주의 평균 교육 기간과 평균 가계 소득 사이의 관계를 이해하고 싶어한다고 가정해 보겠습니다. 그들은 주의 4개 도시에 대해 집계된 데이터를 얻고 평균 교육과 평균 가계 소득 사이의 상관 관계를 계산합니다.
평균 교육기간과 평균 가계소득의 상관관계는 0.9632 인 것으로 나타났다. 이는 매우 양의 상관계수입니다.
연구원들은 평균 교육 기간과 평균 가계 소득 간의 관계를 시각화하기 위해 산점도도 만듭니다.
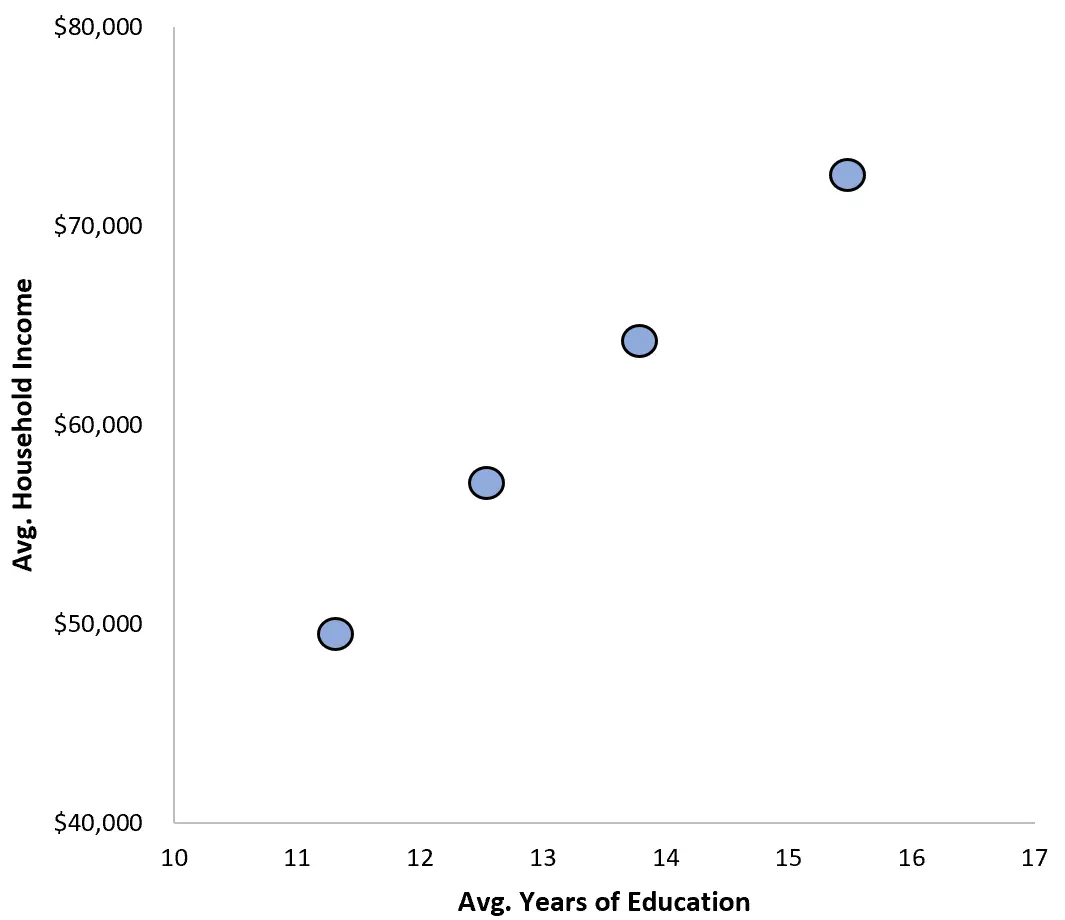
실제로 개인 데이터를 살펴보지 않고도 교육 기간이 길어질수록 가계 소득과 강한 양의 상관관계가 있다는 보고서를 발표할 수도 있습니다.
그러나 1년 후에 새로운 연구원이 들어와 동일한 도시에 있는 개별 가구에 대한 데이터를 얻는다고 가정해 보겠습니다. 그녀가 다음과 같은 데이터 산점도를 생성한다고 가정합니다.
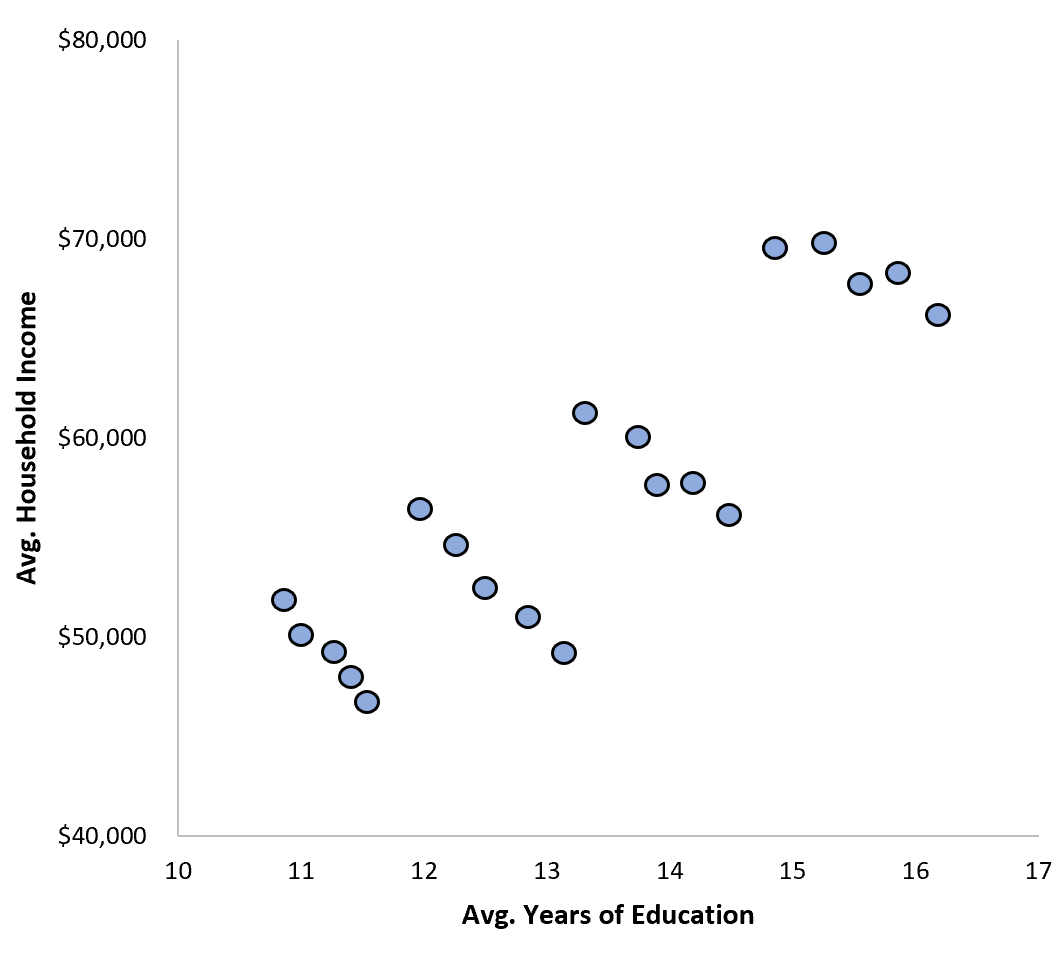
그녀는 두 변수 사이의 상관관계를 계산하고 실제로는 0.1788에 불과하다는 사실을 발견했습니다. 이는 여전히 양의 상관관계이지만 이전 연구자들이 발견한 상관 관계만큼 강력하지는 않습니다 .
그 결과, 데이터를 종합해 보면 개인 차원에서 발생하는 교육과 소득 간의 실제 추세를 다루고 있는 것으로 나타났습니다.
실제로 산점도에서 도시별로 살펴보면 교육과 소득의 관계가 실제로 음수입니다!
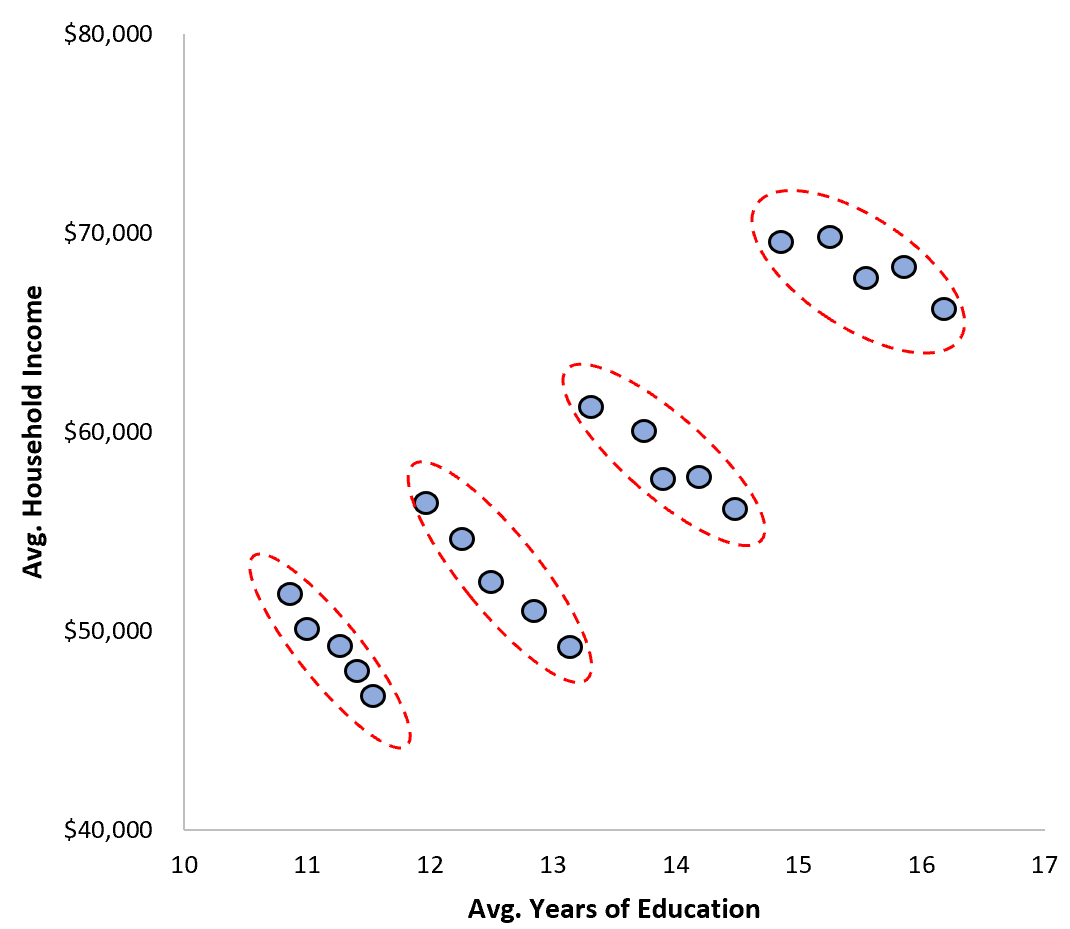
집계 편향의 영향
집계 편향은 연구에서 매우 자주 발생합니다. 단순히 집계 수준에서 나타나는 추세가 개인 수준에서도 나타나야 한다는 잘못된 가정이 종종 있기 때문입니다. 불행하게도 이전 예에서 볼 수 있듯이 항상 그런 것은 아닙니다.
집계 편향으로 인해 연구 결과가 잘못된 결론을 도출하고 오해를 불러일으킬 수 있습니다. 이러한 유형의 편향은 변수 간의 상관관계와 관련될 때 특히 해롭습니다.
두 변수의 집계 데이터 간의 상관 관계가 양수인 경우에도 개별 관찰 수준에서 두 변수 간의 기본 상관 관계는 실제로 다음과 같을 수 있습니다.
- 음의 상관관계
- 상관관계 없음
- 양의 상관관계
이러한 유형의 편향을 피하는 방법은 두 변수 사이의 실제 관계를 발견할 수 있도록 데이터 포인트를 집계하는 대신 개별 데이터 포인트를 사용하여 연구를 수행하는 것입니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기