R의 brown–forsythe 테스트: 단계별 예
일원 분산 분석은 3개 이상의 독립 그룹 평균 간에 유의미한 차이가 있는지 여부를 확인하는 데 사용됩니다.
일원 분산 분석의 가정 중 하나는 표본을 추출한 모집단의 분산이 동일하다는 것입니다.
이를 테스트하는 가장 일반적인 방법 중 하나는 다음 가정을 사용하는 통계 테스트인 Brown-Forsythe 테스트를 사용하는 것입니다.
- H 0 : 모집단 간의 분산이 동일합니다.
- H A : 인구 간의 차이가 동일하지 않습니다.
검정의 p-값이 특정 유의 수준(예: α = 0.05)보다 낮으면 귀무 가설을 기각하고 서로 다른 모집단 간에 분산이 동일하지 않다는 결론을 내립니다.
이 튜토리얼에서는 R에서 Brown-Forsythe 테스트를 수행하는 방법에 대한 단계별 예를 제공합니다.
1단계: 데이터 입력
세 가지 다른 운동 프로그램이 서로 다른 체중 감량 수준으로 이어지는지 여부를 알고 싶다고 가정해 보겠습니다.
이를 테스트하기 위해 우리는 90명을 모집하고 각 프로그램을 사용할 30명을 무작위로 할당합니다. 그런 다음 한 달 후에 각 사람의 체중 감소를 측정합니다.
다음 데이터 세트에는 각 프로그램을 통해 감량된 체중에 대한 정보가 포함되어 있습니다.
#make this example reproducible set.seed(0) #create data frame data <- data.frame(program = as . factor ( rep (c(" A ", " B ", " C "), each = 30)), weight_loss = c( runif (30, 0, 3), runif (30, 0, 5), runif (30, 1, 7))) #view first six rows of data frame head(data) # program weight_loss #1 A 2.6900916 #2 A 0.7965260 #3 A 1.1163717 #4 A 1.7185601 #5 A 2.7246234 #6 A 0.6050458
2단계: 데이터 요약 및 시각화
Brown-Forsythe 테스트를 수행하기 전에 상자 그림을 만들어 각 그룹의 체중 감량 차이를 시각화할 수 있습니다.
boxplot(weight_loss ~ program, data = data)
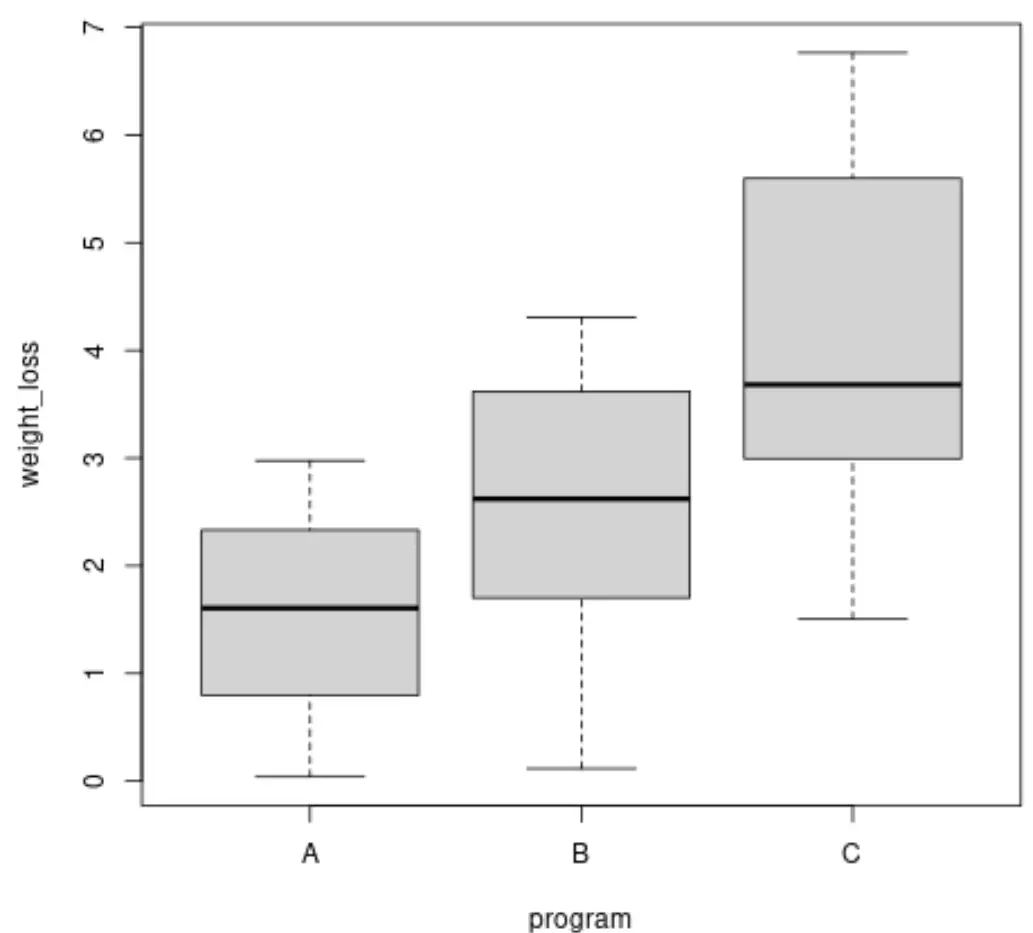
또한 각 그룹의 체중 감소 분산을 계산할 수도 있습니다.
#load dplyr package library (dplyr) #calculate variance of weight loss by group data %>% group_by (program) %>% summarize (var=var(weight_loss)) # A tibble: 3 x 2 program var 1 A 0.819 2 B 1.53 3 C 2.46
그룹 간 차이가 다르다는 것을 알 수 있지만 이러한 차이가 통계적으로 유의 한지 확인하기 위해 Brown-Forsythe 테스트를 수행할 수 있습니다.
3단계: Brown-Forsythe 테스트 수행
R에서 Brown-Forsythe 테스트를 수행하려면 onewaytests 패키지의 bf.test() 함수를 사용할 수 있습니다.
#load onewaytests package library (onewaytests) #perform Brown-Forsythe test bf.test(weight_loss ~ program, data = data) Brown-Forsythe Test (alpha = 0.05) -------------------------------------------------- ----------- data: weight_loss and program statistic: 30.83304 num df: 2 name df: 74.0272 p.value: 1.816529e-10 Result: Difference is statistically significant. -------------------------------------------------- -----------
테스트의 p-값은 0.000 미만으로 나타났으며, 결과에서 알 수 있듯이 세 그룹 간의 분산 차이는 통계적으로 유의미합니다.
다음 단계
Brown-Forsythe 검정의 귀무 가설을 기각할 수 없는 경우 데이터에 대해 일원 분산 분석을 수행할 수 있습니다.
그러나 귀무가설을 기각하면 등분산 가정이 위반된다는 뜻이다. 이 경우 두 가지 옵션이 있습니다.
1. 어쨌든 일원 분산 분석을 수행합니다.
일원 분산 분석은 실제로 가장 큰 분산이 가장 작은 분산의 4배를 넘지 않는 한 동일하지 않은 분산에 대해 견고하다는 것이 밝혀졌습니다.
위 예의 2단계에서 가장 작은 분산은 0.819이고 가장 큰 분산은 2.46임을 확인했습니다. 따라서 가장 큰 분산과 가장 작은 분산의 비율은 2.46 / 0.819 = 3.003 입니다.
이 값은 4보다 작으므로 간단히 일원 분산 분석을 수행할 수 있습니다.
2. 크루스칼-월리스 테스트 수행
가장 큰 분산과 가장 작은 분산의 비율이 4보다 큰 경우 대신 Kruskal-Wallis 테스트를 수행하도록 선택할 수 있습니다. 이는 일원 분산 분석과 비모수적으로 동등한 것으로 간주됩니다.
여기 에서 R의 Kruskal-Wallis 테스트에 대한 단계별 예를 찾을 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기