R에서 잔차 히스토그램을 만드는 방법
선형 회귀의 주요 가정 중 하나는 잔차가 정규 분포를 따른다는 것입니다.
이 가정을 시각적으로 검증하는 한 가지 방법은 잔차의 히스토그램을 만들고 분포가 정규 분포를 연상시키는 “종 모양”을 따르는지 관찰하는 것입니다.
이 튜토리얼에서는 R에서 회귀 모델에 대한 잔차 히스토그램을 만드는 방법에 대한 단계별 예를 제공합니다.
1단계: 데이터 생성
먼저 작업할 가짜 데이터를 만들어 보겠습니다.
#make this example reproducible set.seed(0) #createdata x1 <- rnorm(n=100, 2, 1) x2 <- rnorm(100, 4, 3) y <- rnorm(100, 2, 3) data <- data.frame(x1, x2, y) #view first six rows of data head(data) x1 x2 y 1 3.262954 6.3455776 -1.1371530 2 1.673767 1.6696701 -0.6886338 3 3.329799 2.1520303 5.8081615 4 3.272429 4.1397409 3.7815228 5 2.414641 0.6088427 4.3269030 6 0.460050 5.7301563 6.6721111
2단계: 회귀 모델 적합
다음으로 다중 선형 회귀 모델을 데이터에 적용하겠습니다.
#fit multiple linear regression model
model <- lm(y ~ x1 + x2, data=data)
3단계: 잔차 히스토그램 만들기
마지막으로 ggplot 시각화 패키지를 사용하여 모델 잔차의 히스토그램을 만듭니다.
#load ggplot2
library (ggplot2)
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
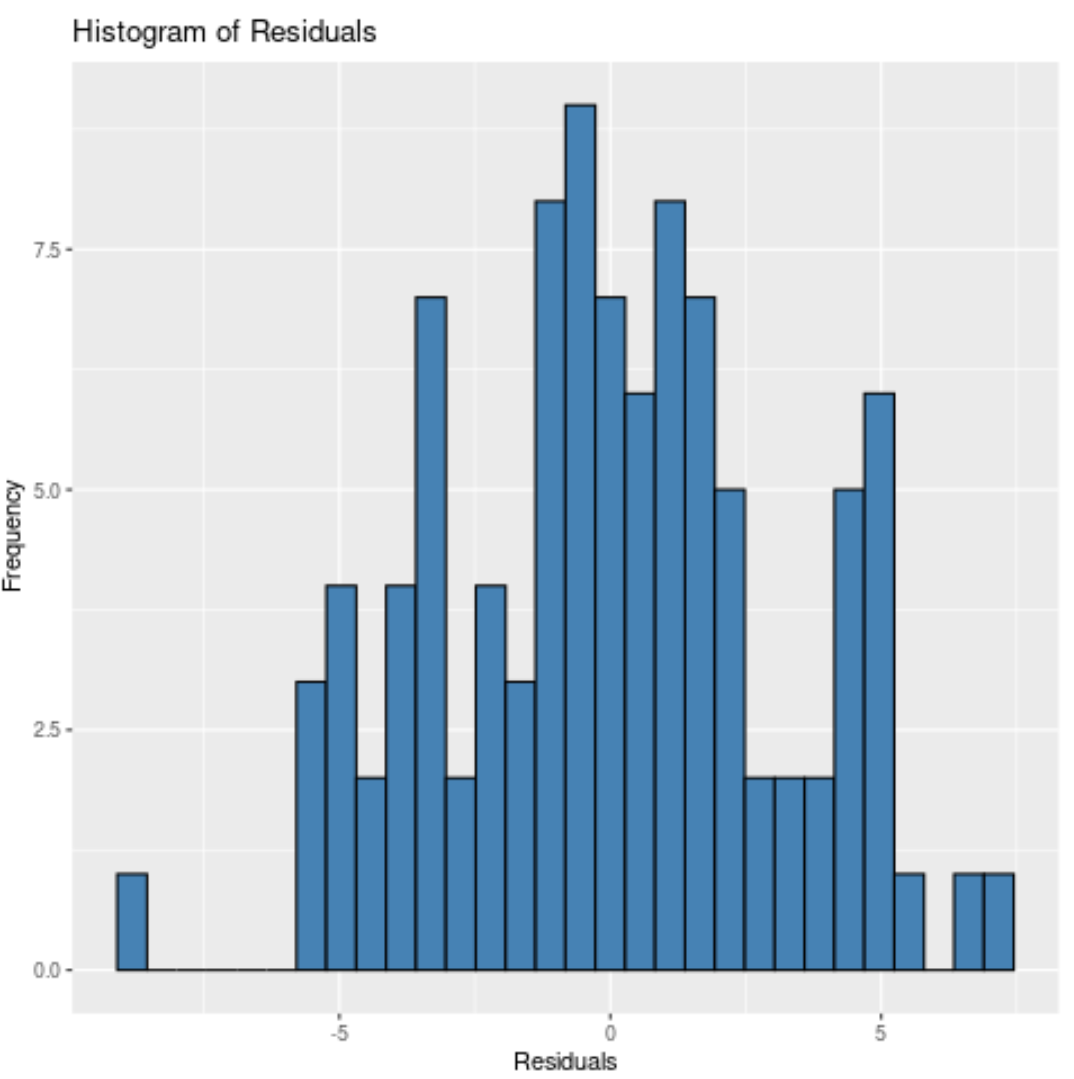
bin 인수를 사용하여 잔여물을 배치할 bin 수를 지정할 수도 있습니다.
상자 수가 적을수록 히스토그램의 막대가 더 넓어집니다. 예를 들어, 20개의 bin을 지정할 수 있습니다.
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(bins = 20 , fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
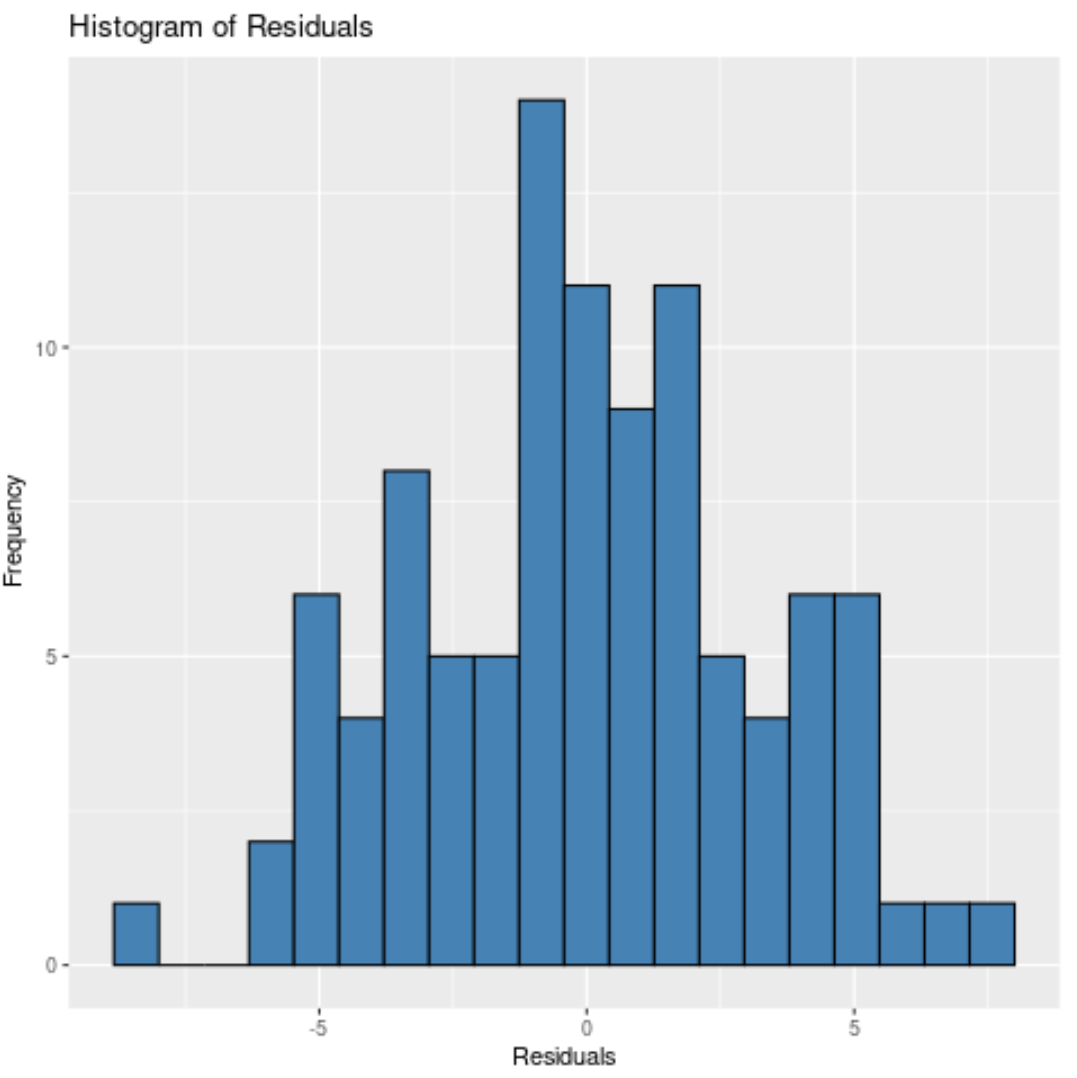
또는 10개의 bin을 지정할 수도 있습니다.
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(bins = 10 , fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
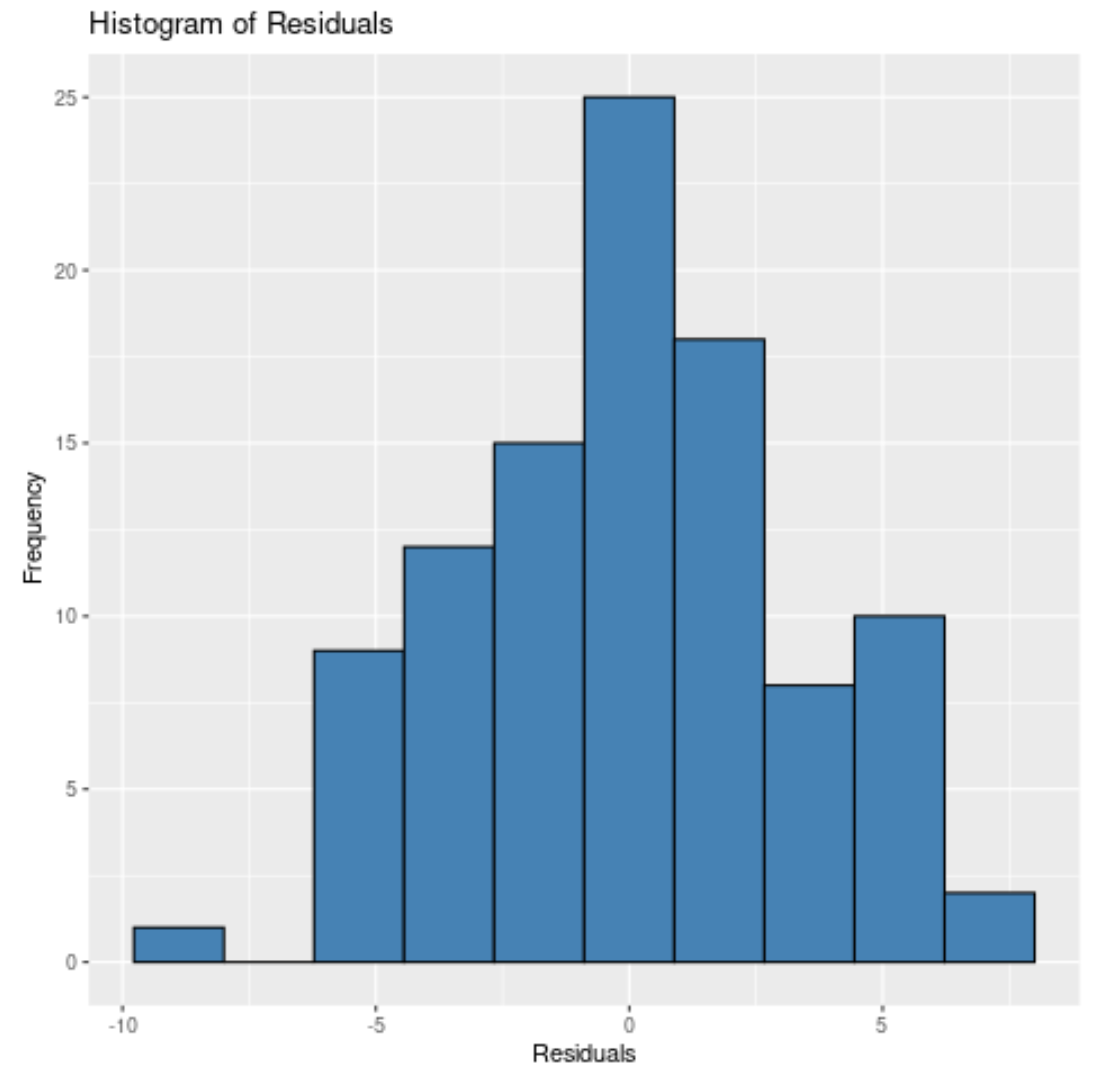
몇 개의 상자를 지정하더라도 잔차가 대략 정규 분포를 따르는 것을 볼 수 있습니다.
정규성을 테스트하기 위해 Shapiro-Wilk, Kolmogorov-Smirnov 또는 Jarque-Bera와 같은 공식적인 통계 테스트를 수행할 수도 있습니다.
그러나 이러한 검정은 표본 크기가 클 경우 민감합니다. 즉, 표본 크기가 클 경우 잔차가 정규 분포가 아니라는 결론을 내리는 경우가 많습니다.
이러한 이유로 잔차의 히스토그램을 만들어 정규성을 평가하는 것이 더 쉬운 경우가 많습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기