비대칭 및 평탄화
이 기사에서는 통계에서 왜도와 첨도가 무엇인지 설명합니다. 따라서 이 두 가지 개념의 정의, 왜도와 첨도를 계산하는 방법, 해당 공식은 물론 데이터 샘플의 왜도와 첨도를 계산하는 온라인 계산기를 찾을 수 있습니다.
왜도와 첨도란 무엇입니까?
왜도와 첨도는 그래프를 작성하지 않고도 분포의 모양을 설명하는 데 사용되는 두 가지 통계적 측정값입니다. 보다 구체적으로, 왜도는 분포의 대칭성(또는 왜도) 정도를 나타내고, 첨도는 분포가 평균 주위에 집중된 정도를 나타냅니다.
통계에서는 왜도와 첨도를 형상 측도 라고도 합니다.
👉 아래 온라인 계산기를 사용하여 모든 데이터세트의 왜도와 첨도를 계산할 수 있습니다.
어울리지 않음
통계에서 왜도는 평균을 기준으로 분포의 대칭성(또는 비대칭성) 정도를 나타내는 척도입니다. 간단히 말해서 왜도는 분포를 그래픽으로 표시할 필요 없이 분포의 대칭성(또는 비대칭성) 정도를 결정하는 데 사용되는 통계 매개변수입니다.
따라서 비대칭 분포는 평균의 왼쪽에 있는 값과 오른쪽에 있는 값의 수가 다른 분포입니다. 반면, 대칭 분포에서는 평균을 기준으로 왼쪽과 오른쪽에 같은 개수의 값이 있습니다.
따라서 우리는 세 가지 유형의 비대칭을 구별합니다.
- 양의 비대칭성 : 분포의 평균은 왼쪽보다 오른쪽에 더 많은 값이 있습니다.
- 대칭성(Symmetry) : 분포는 평균의 오른쪽과 평균의 왼쪽에 동일한 수의 값이 있습니다.
- 음의 왜도 : 분포는 평균의 오른쪽보다 왼쪽에 더 많은 값이 있습니다.
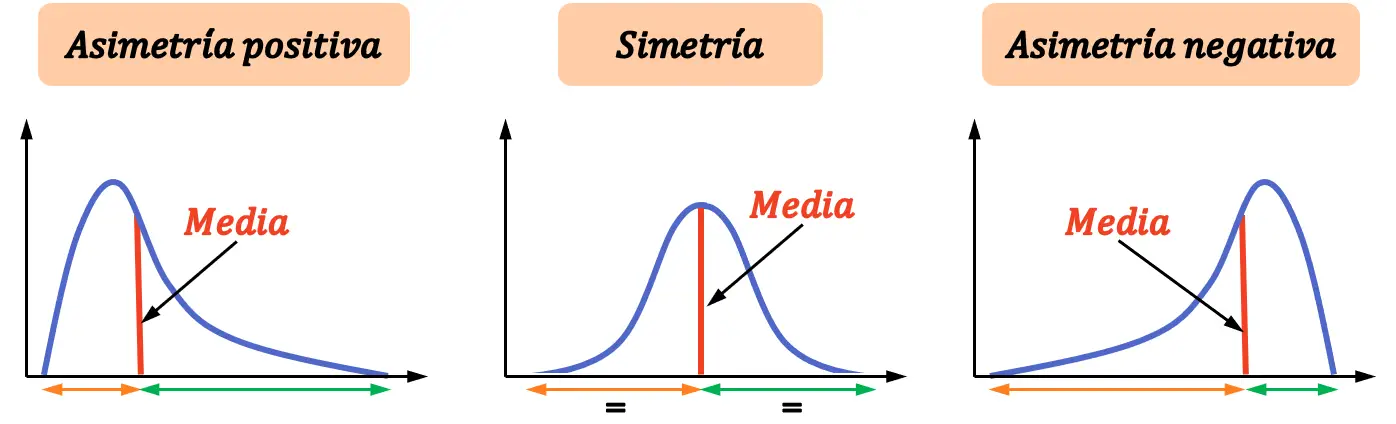
비대칭 계수
왜도 계수 또는 비대칭 지수는 분포의 비대칭성을 결정하는 데 도움이 되는 통계 계수입니다. 따라서 비대칭 계수를 계산하면 분포를 그래픽으로 나타내지 않고도 해당 분포가 어떤 유형의 비대칭성을 나타내는지 알 수 있습니다.
비대칭 계수를 계산하는 공식에는 여러 가지가 있으며 아래에서 모두 볼 수 있지만 사용된 공식에 관계없이 비대칭 계수의 해석은 항상 다음과 같이 수행됩니다.
- 왜도 계수가 양수이면 분포는 양수로 치우쳐 있습니다 .
- 비대칭 계수가 0이면 분포는 대칭 입니다.
- 왜도 계수가 음수이면 분포는 음수로 치우쳐 있습니다 .
피셔의 비대칭 계수
Fisher의 왜도 계수는 평균에 대한 세 번째 모멘트를 표본 표준 편차로 나눈 값과 같습니다. 따라서 Fisher의 비대칭 계수 공식은 다음과 같습니다.

마찬가지로, 다음 두 공식 중 하나를 사용하여 Fisher 계수를 계산할 수 있습니다.

![\displaystyle\gamma_1=\frac{\operatorname{E}[X^3] - 3\mu\sigma^2 - \mu^3}{\sigma^3}](https://statorials.org/wp-content/ql-cache/quicklatex.com-92f7c8482d520258f24cc0166d898d1e_l3.png "Rendered by QuickLaTeX.com")
금

수학적 기대값입니다.

산술 평균,

표준편차

총 데이터 수입니다.
반면에 데이터가 그룹화되면 다음 공식을 사용할 수 있습니다.

이 경우 어디에

그것은 클래스의 표시이며

코스의 절대 빈도.
피어슨의 비대칭 계수
피어슨의 왜도 계수는 표본 평균과 모드 간의 차이를 표준 편차(또는 표준 편차)로 나눈 값과 같습니다. 따라서 Pearson 비대칭 계수의 공식은 다음과 같습니다.

금

피어슨 계수이고,
산술 평균,

패션과
표준편차.
Pearson 왜도 계수는 단봉 분포인 경우, 즉 데이터에 모드가 하나만 있는 경우에만 계산할 수 있습니다.
Bowley의 비대칭 계수
보울리의 왜도 계수는 3분위수 더하기 1분위수의 합에서 중앙값의 2배를 뺀 값을 3분위수와 1분위수 간의 차이로 나눈 값과 같습니다. 따라서 이 비대칭 계수의 공식은 다음과 같습니다.

금

그리고

이는 각각 1사분위수와 3사분위수이며,

분포의 중앙값입니다.
평탄화
왜도라고도 하는 첨도 는 분포가 평균 주위에 얼마나 집중되어 있는지를 나타냅니다. 즉, 첨도는 분포가 가파른지 평평한지 여부를 나타냅니다. 특히, 분포의 첨도가 클수록 분포의 기울기가 더 가파르거나 뾰족해집니다.
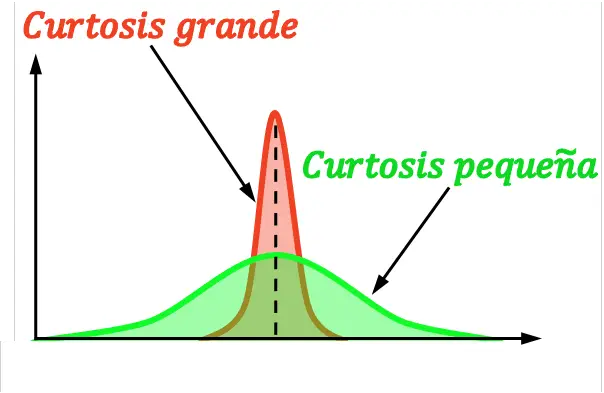
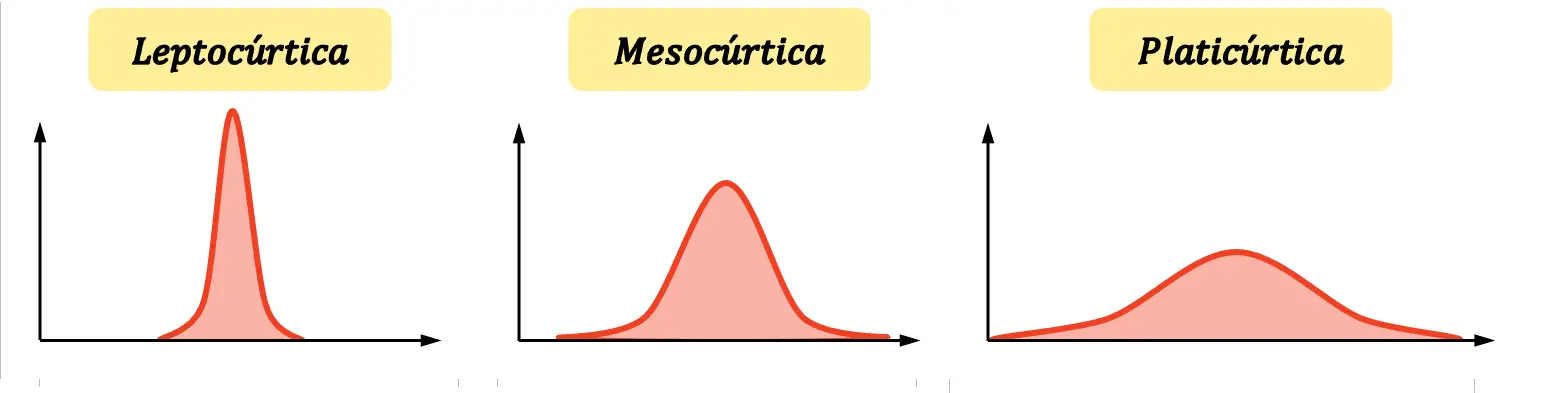
아첨에는 세 가지 유형이 있습니다.
- Leptokurtic : 분포가 매우 뾰족합니다. 즉, 데이터가 평균 주위에 강하게 집중되어 있음을 의미합니다. 보다 정확하게는 렙토쿠르틱 분포는 정규 분포보다 더 날카로운 분포로 정의됩니다.
- Mesokurtic : 분포의 첨도는 정규 분포의 첨도와 동일합니다. 그러므로 날카롭지도 돋보이지도 않습니다.
- Platykurtic : 분포가 매우 평평합니다. 즉, 평균 주변의 집중도가 낮습니다. 공식적으로, 플래티커틱 분포는 정규 분포보다 평평한 분포로 정의됩니다.
다양한 유형의 첨도는 정규 분포의 첨도를 기준으로 하여 정의됩니다.
첨도 계수
첨도 계수의 공식은 다음과 같습니다.

빈도표로 그룹화된 데이터 의 첨도 계수 공식은 다음과 같습니다.

마지막으로 간격으로 그룹화된 데이터 의 첨도 계수 공식은 다음과 같습니다.

금:
-

첨도 계수입니다.
-
총 데이터 개수입니다.
-
시리즈의 i번째 데이터 포인트입니다.
-
분포의 산술 평균입니다.
-
분포의 표준편차(또는 일반편차)입니다.
-
it 데이터 세트의 절대 빈도입니다.
-

는 i번째 그룹의 클래스 마크입니다.
모든 첨도 계수 공식에서 3은 정규 분포의 첨도 값이므로 뺍니다. 따라서 첨도 계수의 계산은 정규 분포의 첨도를 기준으로 수행됩니다. 통계에서 가끔 첨도가 과도하게 계산된다는 말이 나오는 이유도 바로 이 때문이다.
첨도 계수가 계산되면 다음과 같이 해석하여 첨도의 유형을 식별해야 합니다.
- 첨도 계수가 양수이면 분포가 leptokurtic 함을 의미합니다.
- 첨도 계수가 0이면 분포가 메소쿠르틱 하다는 의미입니다.
- 첨도 계수가 음수이면 분포가 평면형 임을 의미합니다.
왜도 및 첨도 계산기
다음 계산기에 데이터 세트를 입력하여 왜도와 첨도 계수를 계산하고 분포 유형을 결정합니다. 데이터는 공백으로 구분해야 하며 소수점 구분 기호로 마침표를 사용하여 입력해야 합니다.
비대칭성과 첨도는 무엇에 사용되나요?
마지막으로 통계에서 왜도와 첨도가 어떤 용도로 사용되는지, 그리고 이 두 가지 유형의 통계 매개변수가 어떻게 해석되는지 살펴보겠습니다.
왜도와 첨도는 그래픽으로 표현할 필요 없이 확률 분포의 모양을 정의하는 데 사용됩니다. 즉, 일반적으로 많은 시간과 노력이 소요되는 그래프를 작성할 필요 없이 왜도와 첨도를 계산하여 어떤 분포인지 판단하는 것입니다.
또한 왜도와 첨도 값은 분포 곡선을 정규 분포와 비교하는 데 사용됩니다. 유사하다면 이는 연구할 분포가 정규 분포에 근접할 수 있음을 의미하므로 여러 가지 통계 정리를 적용할 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기