Sas에서 proc cluster를 사용하는 방법(예제 포함)
클러스터링은 데이터 세트 내에서 관찰 그룹을 찾으려고 시도하는 기계 학습 기술입니다.
목표는 각 군집 내의 관측값이 서로 매우 유사한 반면, 다른 군집의 관측값은 서로 상당히 다른 군집을 찾는 것입니다.
SAS에서 클러스터링을 수행하는 가장 쉬운 방법은 PROC CLUSTER를 사용하는 것입니다.
다음 예에서는 실제로 PROC CLUSTER를 사용하는 방법을 보여줍니다.
예: SAS에서 PROC CLUSTER를 사용하는 방법
20명의 농구 선수에 대한 득점, 어시스트, 리바운드에 대한 정보가 포함된 다음 데이터 세트가 있다고 가정해 보겠습니다.
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
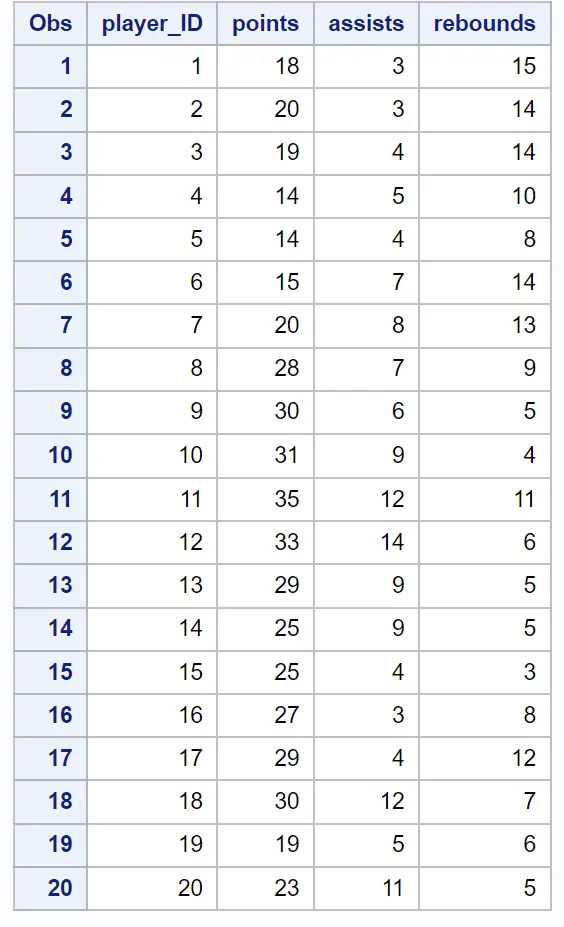
proc print data =my_data;
서로 비슷한 통계를 가진 플레이어의 “클러스터”를 식별하기 위해 그룹화를 수행한다고 가정해 보겠습니다.
다음 코드는 SAS에서 PROC CLUSTER를 사용하여 클러스터링을 수행하는 방법을 보여줍니다.
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
결과의 첫 번째 테이블은 클러스터링이 수행된 방법에 대한 정보를 제공합니다.
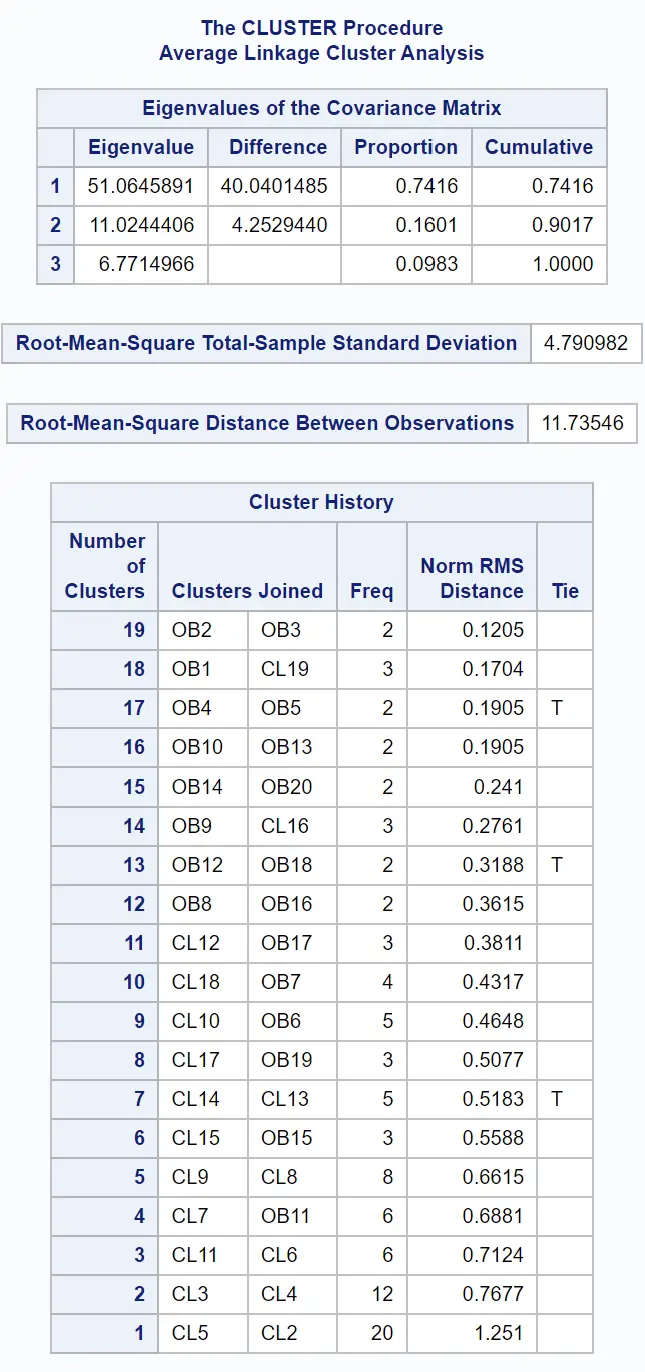
데이터 세트의 관측치 간의 유사성을 시각적으로 검사할 수 있도록 덴드로그램도 생성됩니다.
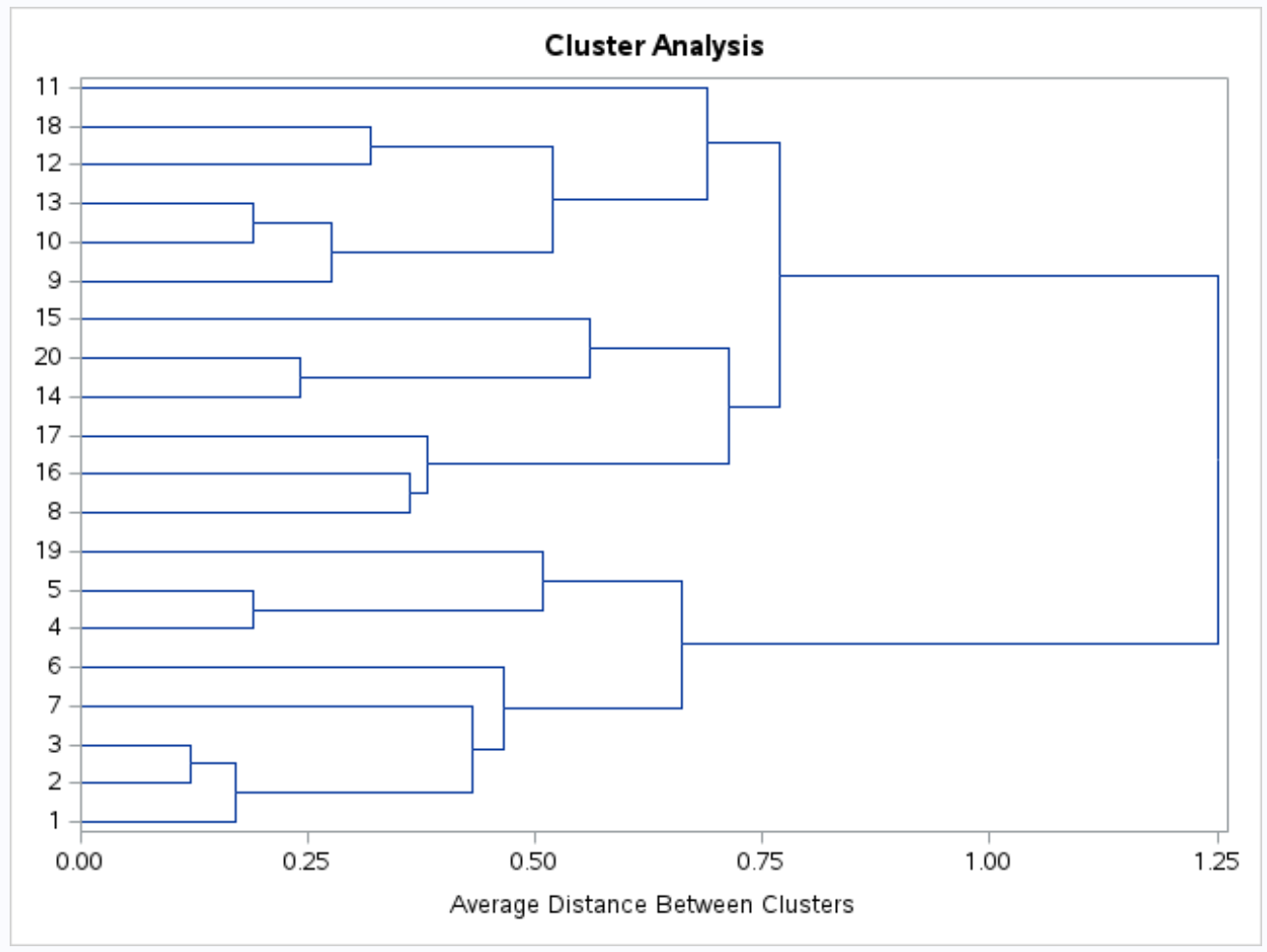
y축은 개별 관측치를 표시하고 x축은 클러스터 간의 평균 거리를 표시합니다.
이 덴드로그램을 보면 관측값이 자연스럽게 세 그룹으로 분류되는 것으로 보입니다.
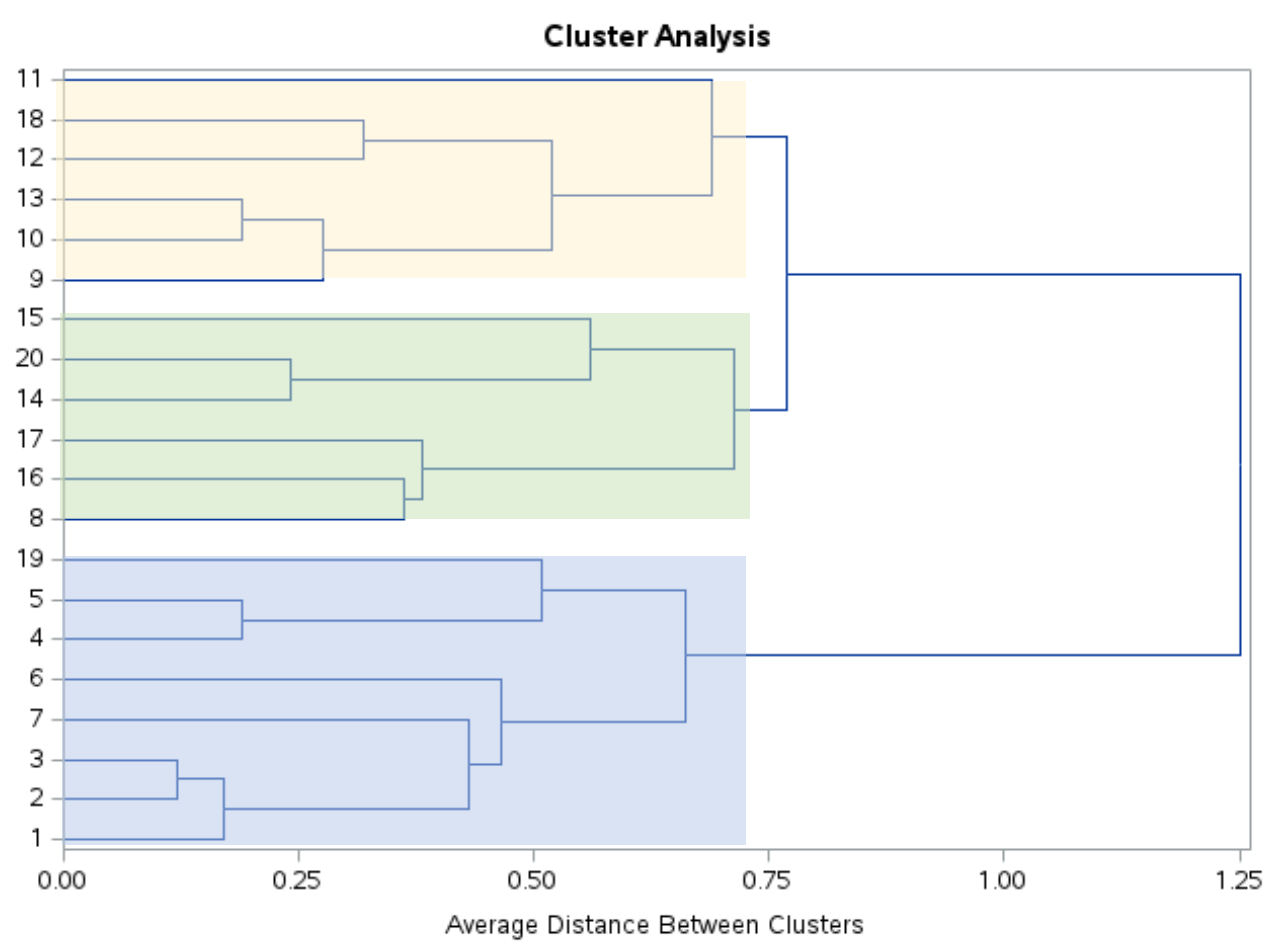
그런 다음 ncl=3 인 PROC TREE 문을 사용하여 SAS에 원본 데이터세트의 각 관측값을 세 클러스터 중 하나에 할당하도록 지시할 수 있습니다.
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
결과 데이터 세트는 원래 관측치 각각과 해당 관측치가 속한 클러스터를 보여줍니다.
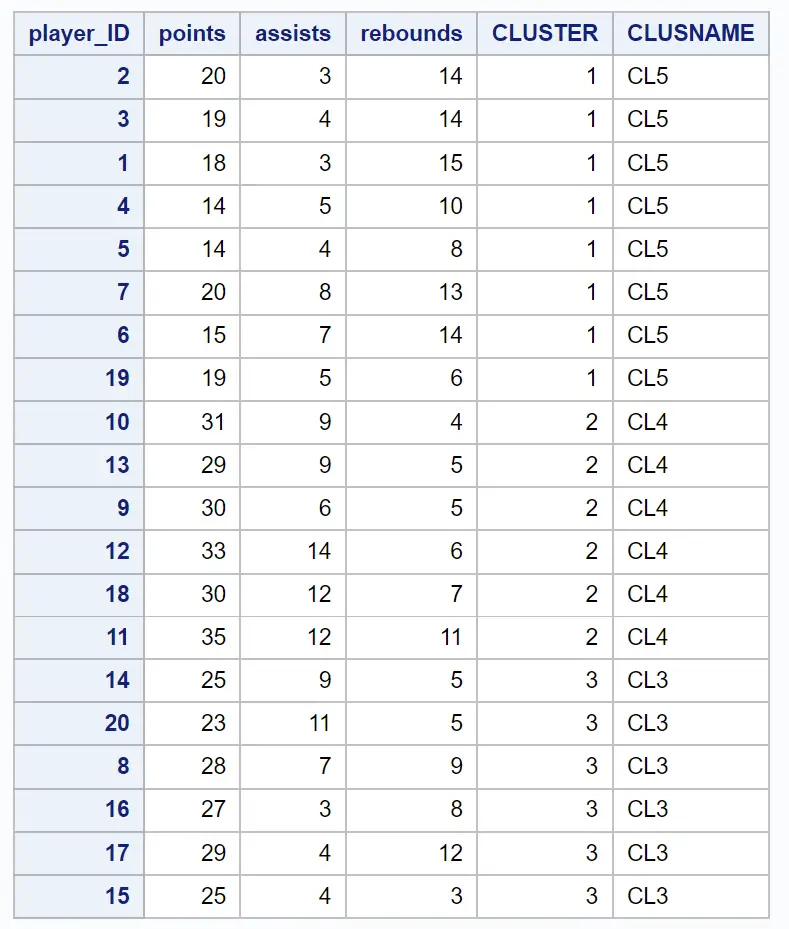
예를 들어 ID가 2, 3, 1, 4, 5, 7, 6 및 19 인 플레이어가 모두 클러스터 1에 속한다는 것을 확인할 수 있습니다 .
이는 이 8명의 선수가 득점, 어시스트, 리바운드 변수 측면에서 ‘유사’하다는 것을 말해줍니다.
참고 : 이 예에서는 클러스터링을 위한 연결 방법으로 평균화를 사용하기로 선택했습니다. 사용할 수 있는 다른 바인딩 방법의 전체 목록은 SAS 설명서를 참조하세요.
추가 리소스
다음 튜토리얼에서는 SAS에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
SAS에서 주성분 분석을 수행하는 방법
SAS에서 다중 선형 회귀를 수행하는 방법
SAS에서 로지스틱 회귀를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기