Excel: linest를 사용하여 다중 선형 회귀를 수행하는 방법
Excel에서 LINEST 함수를 사용하여 다중 선형 회귀 모델을 데이터 집합에 맞출 수 있습니다.
이 함수는 다음 기본 구문을 사용합니다.
= LINEST ( known_y's, [known_x's], [const], [stats] )
금:
- Known_y’s : 알려진 y 값의 배열
- Known_x’s : 알려진 x 값의 배열
- const : 선택적 인수입니다. TRUE이면 상수 b가 정상적으로 처리됩니다. FALSE인 경우 상수 b는 1로 설정됩니다.
- stats : 선택적 인수입니다. TRUE이면 추가 회귀 통계가 반환됩니다. FALSE인 경우 추가 회귀 통계가 반환되지 않습니다.
다음 단계별 예에서는 이 기능을 실제로 사용하는 방법을 보여줍니다.
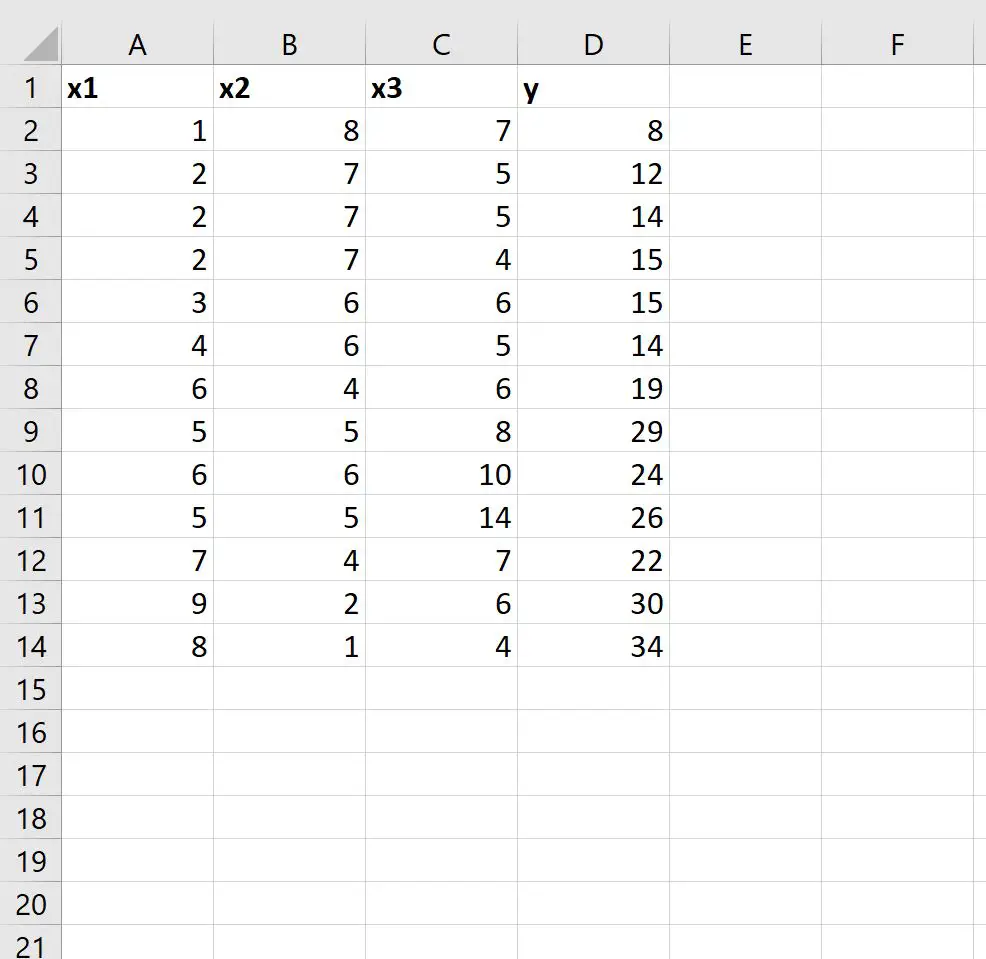
1단계: 데이터 입력
먼저 Excel에 다음 데이터 세트를 입력해 보겠습니다.
2단계: LINEST를 사용하여 다중 선형 회귀 모델 적합
예측 변수로 x1 , x2 , x3을 사용하고 응답 변수로 y 를 사용하여 다중 선형 회귀 모델을 적합화한다고 가정합니다.
이를 위해 다중 선형 회귀 모델에 맞게 모든 셀에 다음 수식을 입력할 수 있습니다.
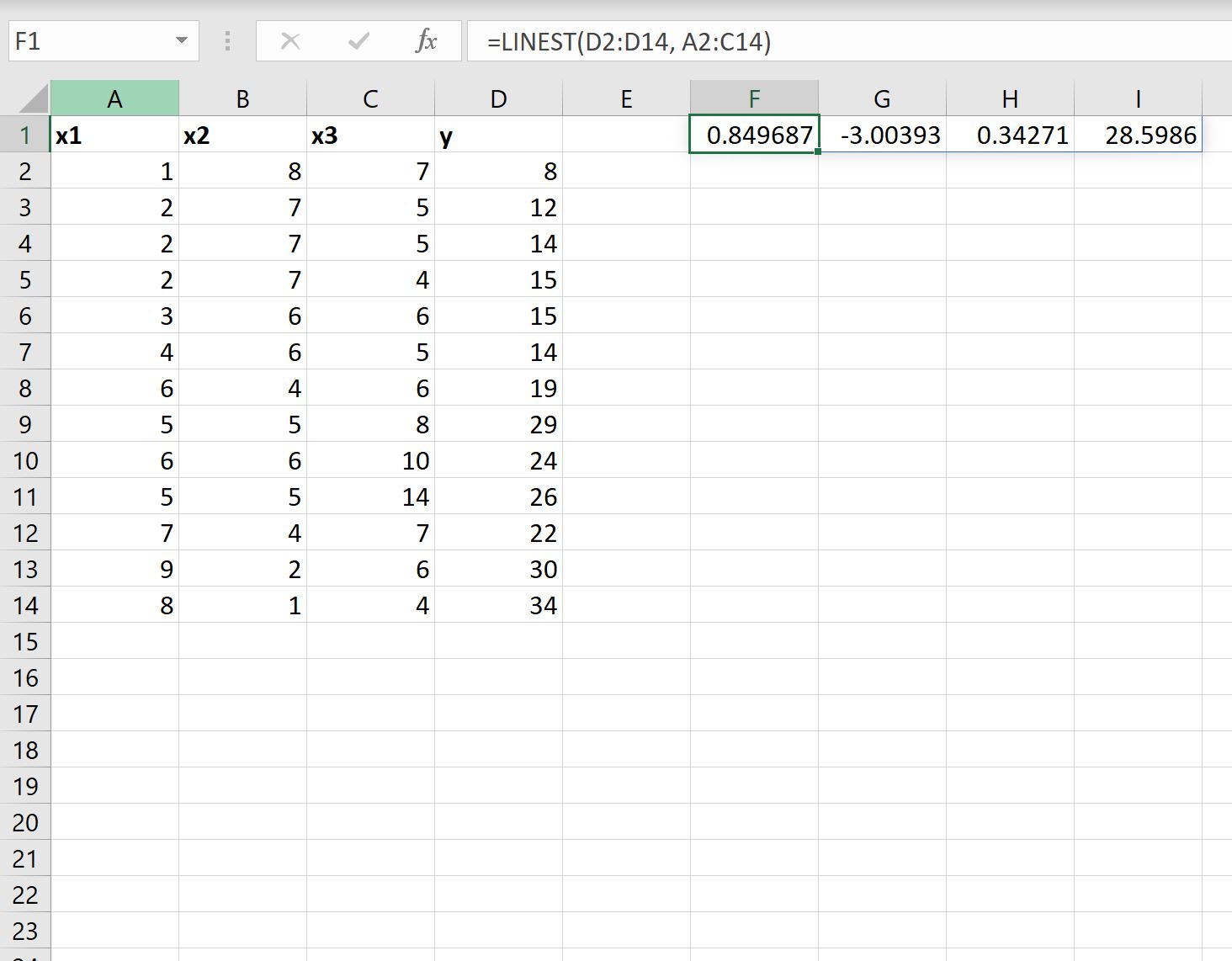
=LINEST( D2:D14 , A2:C14 )
다음 스크린샷은 실제로 이 수식을 사용하는 방법을 보여줍니다.
결과를 해석하는 방법은 다음과 같습니다.
- 절편의 계수는 28.5986 입니다.
- x1의 계수는 0.34271 입니다.
- x2의 계수는 -3.00393 입니다.
- x3의 계수는 0.849687 입니다.
이러한 계수를 사용하여 다음과 같이 적합 회귀 방정식을 작성할 수 있습니다.
y = 28.5986 + 0.34271(x1) – 3.00393(x2) + 0.849687(x3)
3단계(선택 사항): 추가 회귀 통계 보기
또한 LINEST 함수의 stats 인수 값을 TRUE 로 설정하여 적합 회귀 방정식에 대한 추가 회귀 통계를 표시할 수도 있습니다.
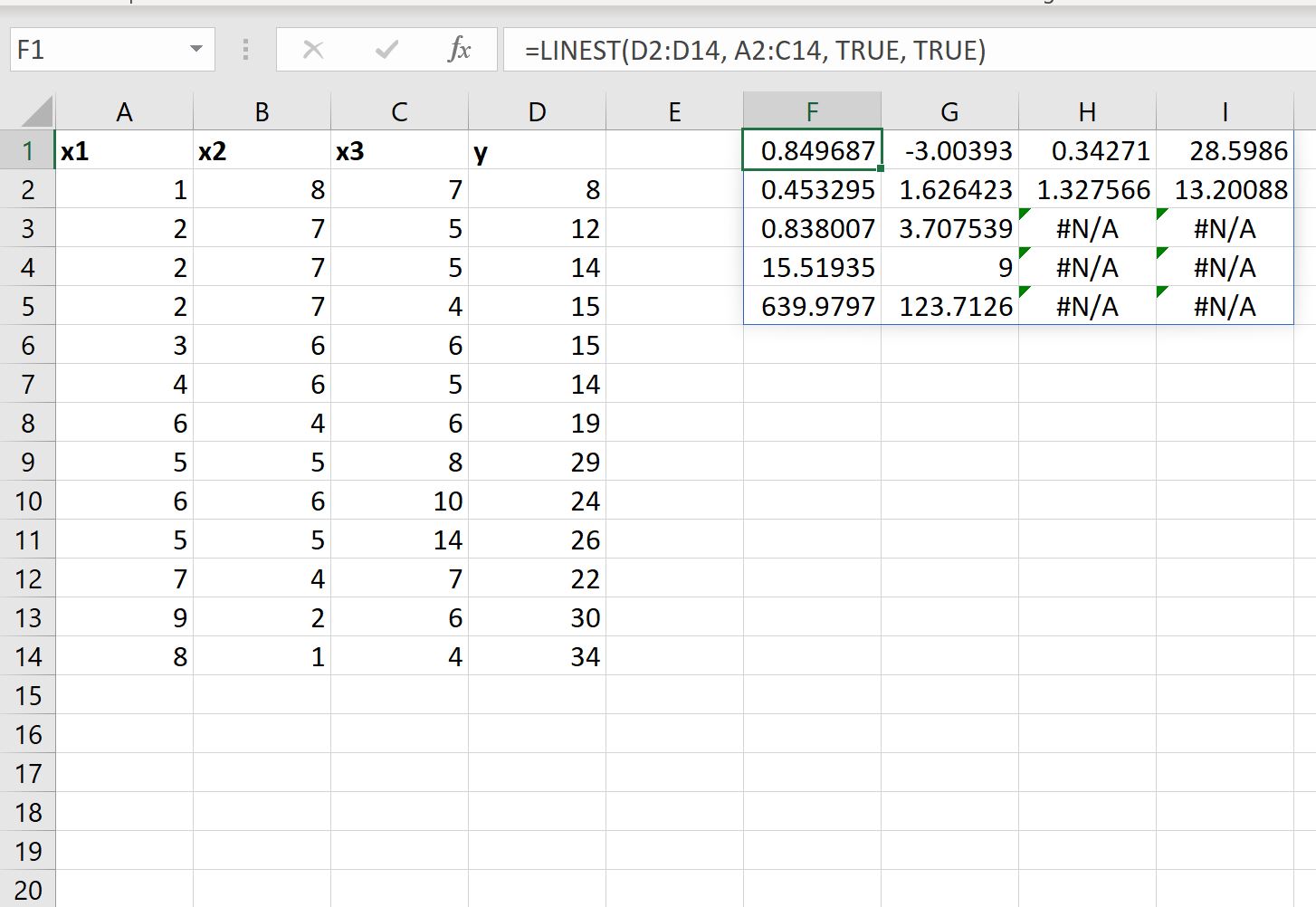
적합 회귀 방정식은 여전히 동일합니다.
y = 28.5986 + 0.34271(x1) – 3.00393(x2) + 0.849687(x3)
결과의 다른 값을 해석하는 방법은 다음과 같습니다.
- x3의 표준 오류는 0.453295 입니다.
- x2의 표준 오류는 1.626423 입니다.
- x1의 표준 오류는 1.327566 입니다.
- 절편의 표준 오류는 13.20088 입니다.
- 모델의 R 2 는 .838007 입니다.
- y의 잔차 표준 오차는 3.707539 입니다.
- 전체 F 통계량은 15.51925 입니다.
- 자유도는 9 입니다.
- 회귀 제곱합은 639.9797 입니다.
- 잔차 제곱합은 123.7126 입니다.
일반적으로 이러한 추가 통계에서 가장 관심 있는 측도는 예측 변수로 설명할 수 있는 반응 변수의 분산 비율을 나타내는 R 2 값입니다.
R2 의 값은 0에서 1까지 다양합니다.
이 특정 모델의 R 2 는 0.838 이므로 예측 변수가 응답 변수 y의 값을 잘 예측하고 있음을 알 수 있습니다.
관련 항목: 좋은 R 제곱 값이란 무엇입니까?
추가 리소스
다음 자습서에서는 Excel에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
Excel에서 LOGEST 함수를 사용하는 방법
Excel에서 비선형 회귀를 수행하는 방법
Excel에서 3차 회귀를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기