Ggplot2에서 히스토그램의 빈 수를 설정하는 방법
bins 인수를 사용하여 ggplot2 의 히스토그램에 사용할 bin 수를 지정할 수 있습니다.
library (ggplot2) ggplot(df, aes (x=x)) + geom_histogram(bins= 10 )
다음 예에서는 이 인수를 실제로 사용하는 방법을 보여줍니다.
예: ggplot2에서 히스토그램의 bin 수 설정
다음 코드는 평균값이 2인 포아송 분포를 따르는 10,000개의 임의 값을 포함하는 R에서 데이터 세트를 생성하는 방법을 보여줍니다.
#make this example reproducible
set. seeds (0)
#create data frame with 10,000 random values that follow Poisson distribution
df <- data. frame (values=rpois(n= 10000 , lambda= 2 ))
#view first five rows of data frame
head(df)
values
1 4
2 1
3 1
4 2
5 4
6 1
다음 코드를 사용하여 ggplot2에서 히스토그램을 생성하여 데이터 프레임의 값 분포를 시각화할 수 있습니다.
library (ggplot2)
ggplot(df, aes (x=values)) +
geom_histogram(fill=' steelblue ', col=' black ')
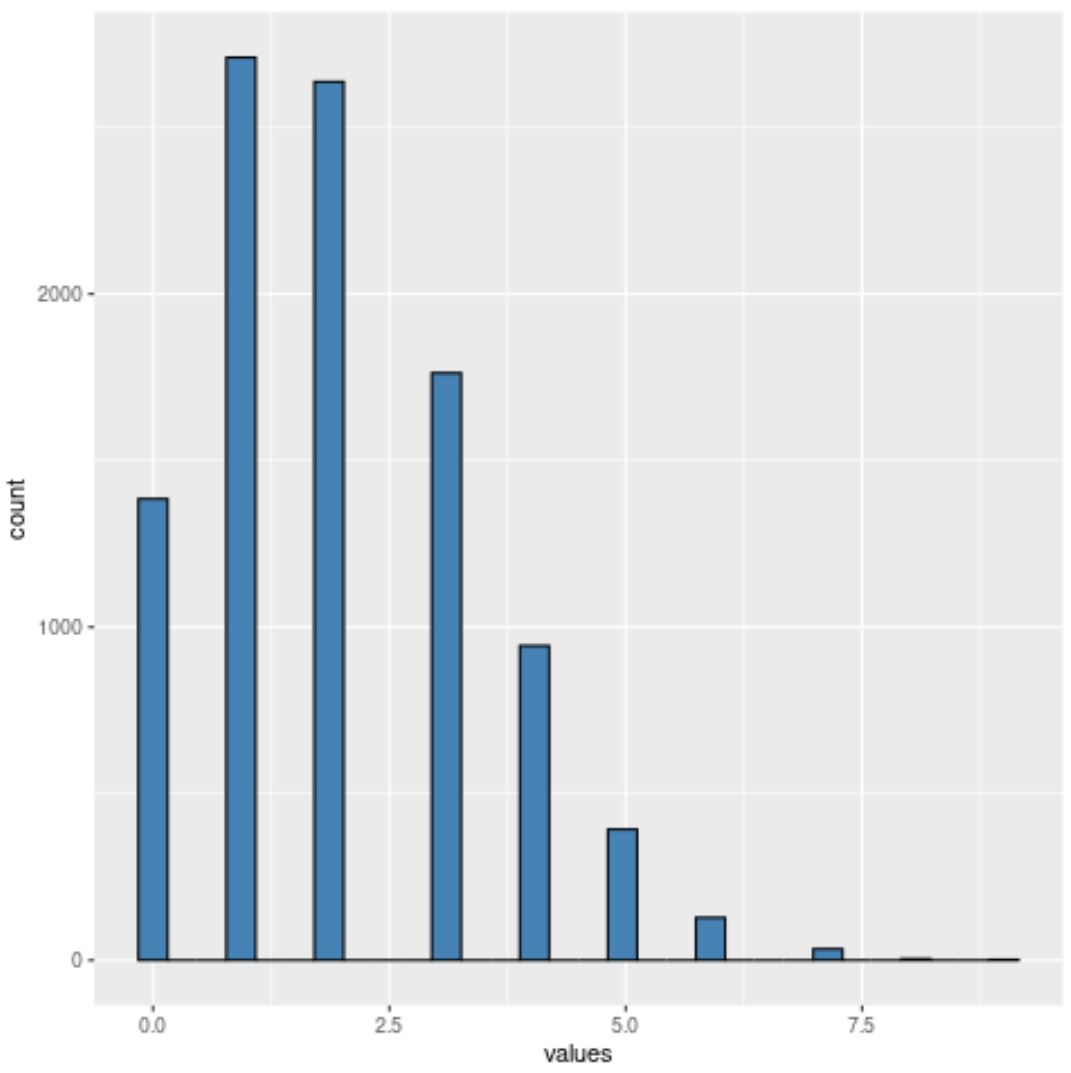
기본적으로 ggplot2는 히스토그램에 사용할 특정 수의 상자를 자동으로 선택합니다.
그러나 다음 구문을 사용하여 히스토그램이 10개의 빈을 사용하도록 지정할 수 있습니다.
library (ggplot2)
ggplot(df, aes (x=values)) +
geom_histogram(fill=' steelblue ', col=' black ', bins= 10 )
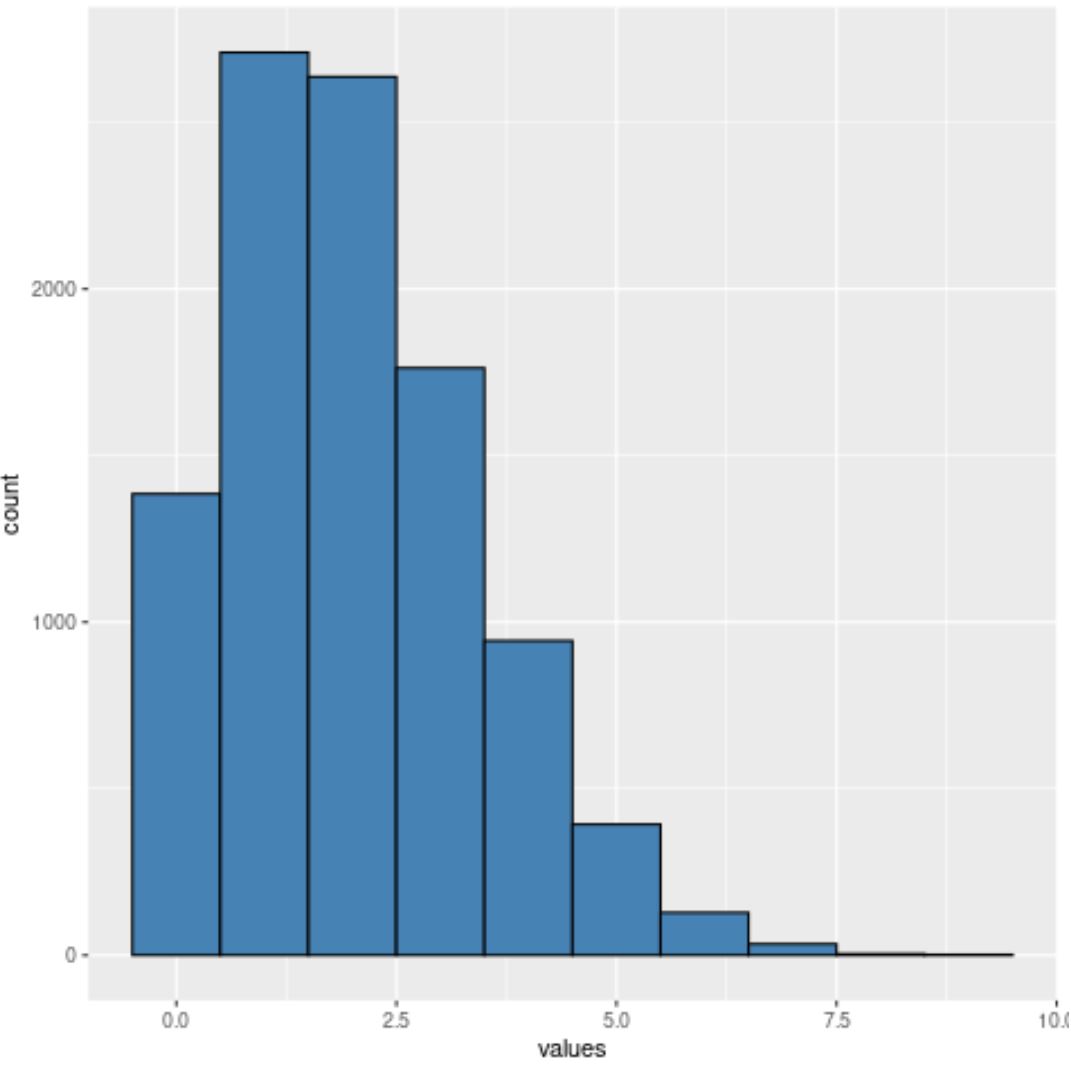
이제 히스토그램에는 정확히 10개의 상자가 있습니다.
또는 다음 구문을 사용하여 히스토그램이 5개의 빈을 사용하도록 지정할 수 있습니다.
library (ggplot2)
ggplot(df, aes (x=values)) +
geom_histogram(fill=' steelblue ', col=' black ', bins= 5 )
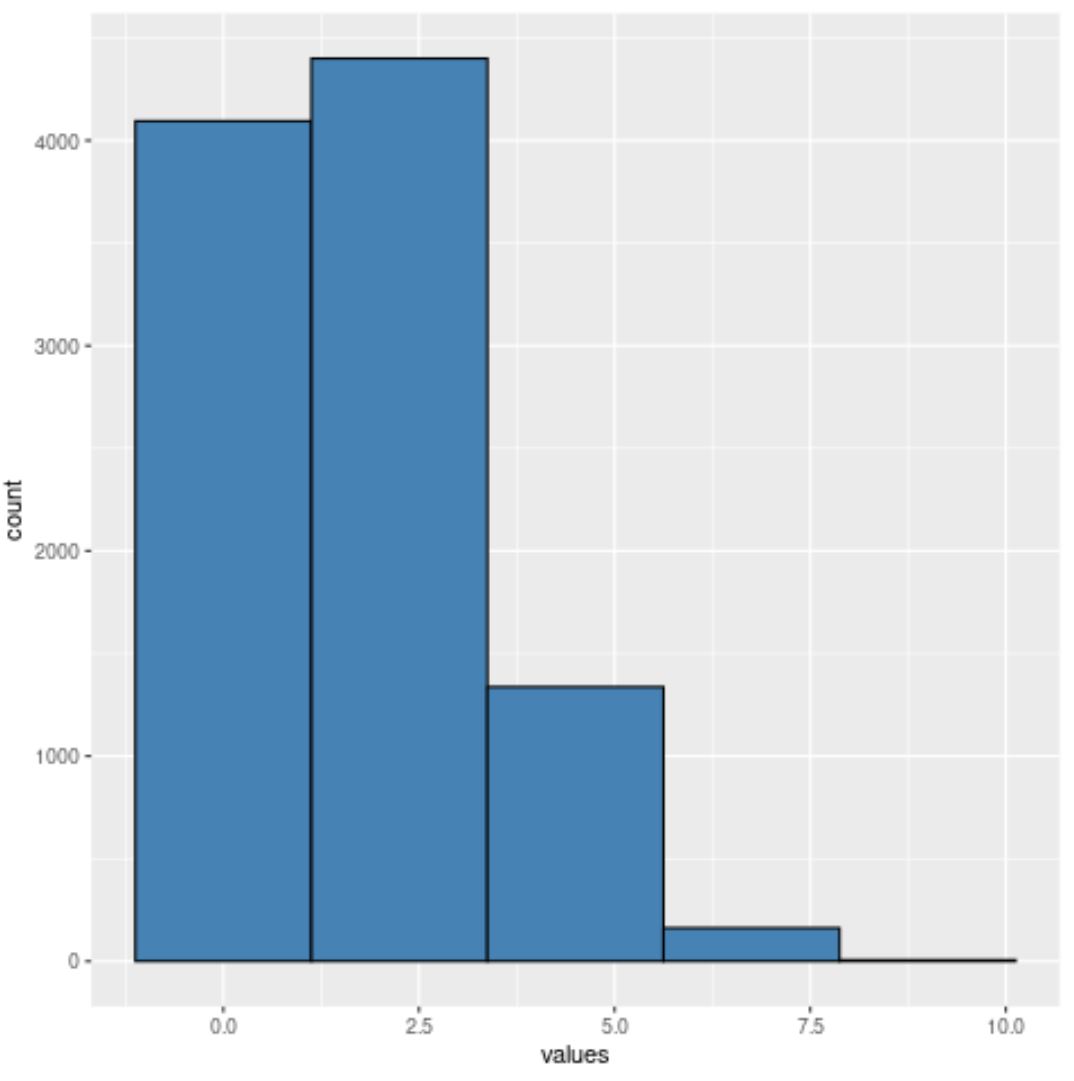
이제 히스토그램에는 정확히 5개의 상자가 있습니다.
사용하는 쓰레기통의 수가 적을수록 각 쓰레기통의 폭이 넓어진다는 것을 알게 될 것입니다.
일반적으로 너무 적은 수의 그룹을 사용하면 실제 기본 값 분포가 숨겨집니다.
그러나 너무 많은 그룹을 사용하면 데이터에 노이즈가 나타날 위험이 있습니다.
히스토그램에 사용할 최적의 Bin 수를 찾는 한 가지 방법은 Sturges의 법칙을 사용하는 것입니다. 여기에서 이 규칙에 대해 자세히 알아보세요.
참고 : geom_histogram 함수에 대한 전체 문서는 여기에서 찾을 수 있습니다.
추가 리소스
다음 튜토리얼에서는 R에서 다른 일반적인 그래프를 만드는 방법을 설명합니다.
R에서 상대 빈도 히스토그램을 만드는 방법
R의 단일 그래프에 여러 상자 그림을 그리는 방법
R의 그래프에 여러 선을 그리는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기