Python에서 일변량 분석을 수행하는 방법: 예제 포함
단변량 분석이라는 용어는 하나의 변수에 대한 분석을 의미합니다. 접두사 “uni”가 “하나”를 의미하기 때문에 이것을 기억할 수 있습니다.
변수에 대한 일변량 분석을 수행하는 세 가지 일반적인 방법이 있습니다.
1. 요약 통계 – 값의 중심과 분포를 측정합니다.
2. 빈도표 – 서로 다른 값이 얼마나 자주 나타나는지 설명합니다.
3. 차트 – 값의 분포를 시각화하는 데 사용됩니다.
이 튜토리얼에서는 다음 Pandas DataFrame을 사용하여 단변량 분석을 수행하는 방법에 대한 예를 제공합니다.
import pandas as pd #createDataFrame df = pd. DataFrame ({' points ': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2], ' assists ': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6], ' rebounds ': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]}) #view first five rows of DataFrame df. head () points assists rebounds 0 1.0 5 11 1 1.0 7 8 2 2.0 7 10 3 3.5 9 6 4 4.0 12 6
1. 요약 통계 계산
다음 구문을 사용하여 DataFrame의 “points” 변수에 대한 다양한 요약 통계를 계산할 수 있습니다.
#calculate mean of 'points' df[' points ']. mean () 5.706666666666667 #calculate median of 'points' df[' points ']. median () 5.0 #calculate standard deviation of 'points' df[' points ']. std () 3.858287308169384
2. 빈도표 만들기
다음 구문을 사용하여 변수 ‘포인트’에 대한 빈도 테이블을 만들 수 있습니다.
#create frequency table for 'points' df[' points ']. value_counts () 4.0 3 1.0 2 5.0 2 2.0 1 3.5 1 6.5 1 7.0 1 7.4 1 8.0 1 13.0 1 14.2 1 Name: points, dtype: int64
이는 다음을 알려줍니다.
- 값 4가 3번 나타납니다.
- 값 1 이 두 번 나타납니다.
- 값 5가 두 번 나타납니다.
- 값 2가 1번 나타납니다.
등등.
관련 항목: Python에서 빈도표를 만드는 방법
3. 차트 만들기
다음 구문을 사용하여 ‘points’ 변수에 대한상자 그림을 만들 수 있습니다.
import matplotlib. pyplot as plt df. boxplot (column=[' points '], grid= False , color=' black ')
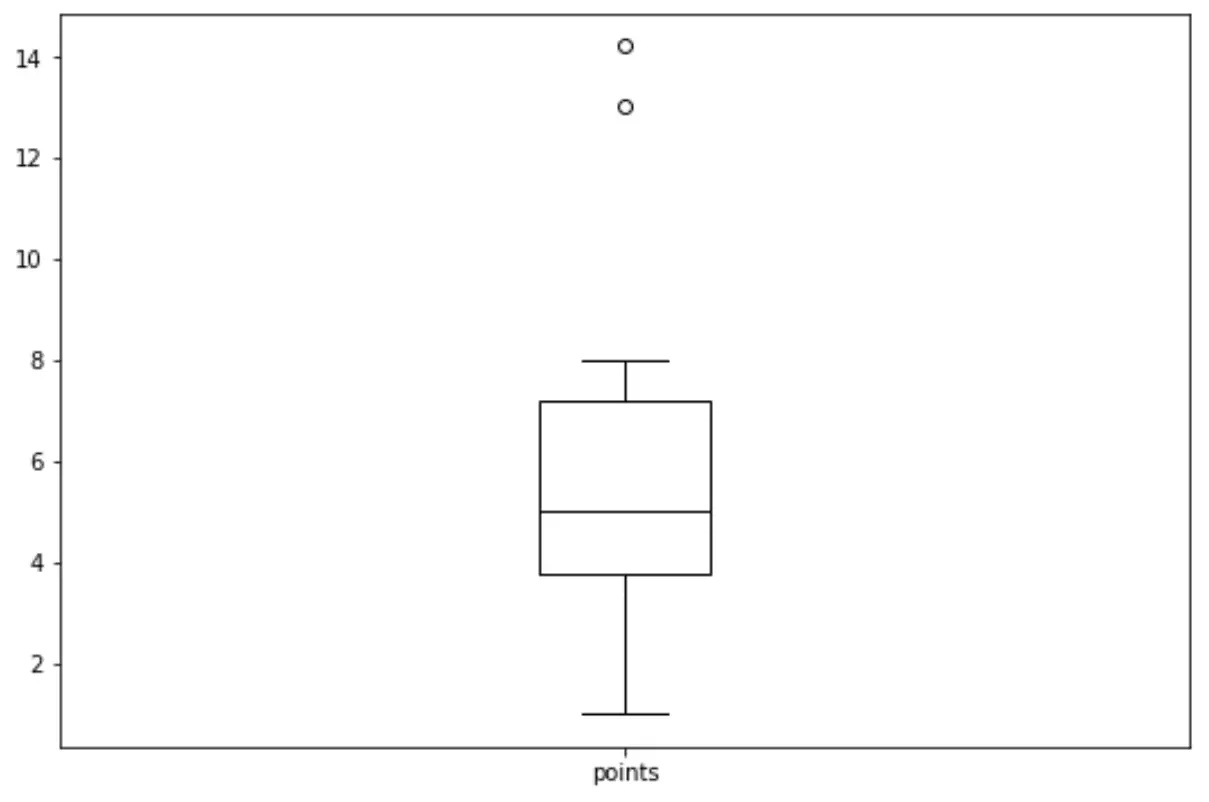
관련 항목: Pandas DataFrame에서 상자 그림을 만드는 방법
다음 구문을 사용하여 ‘points’ 변수에 대한 히스토그램을 만들 수 있습니다.
import matplotlib. pyplot as plt df. hist (column=' points ', grid= False , edgecolor=' black ')
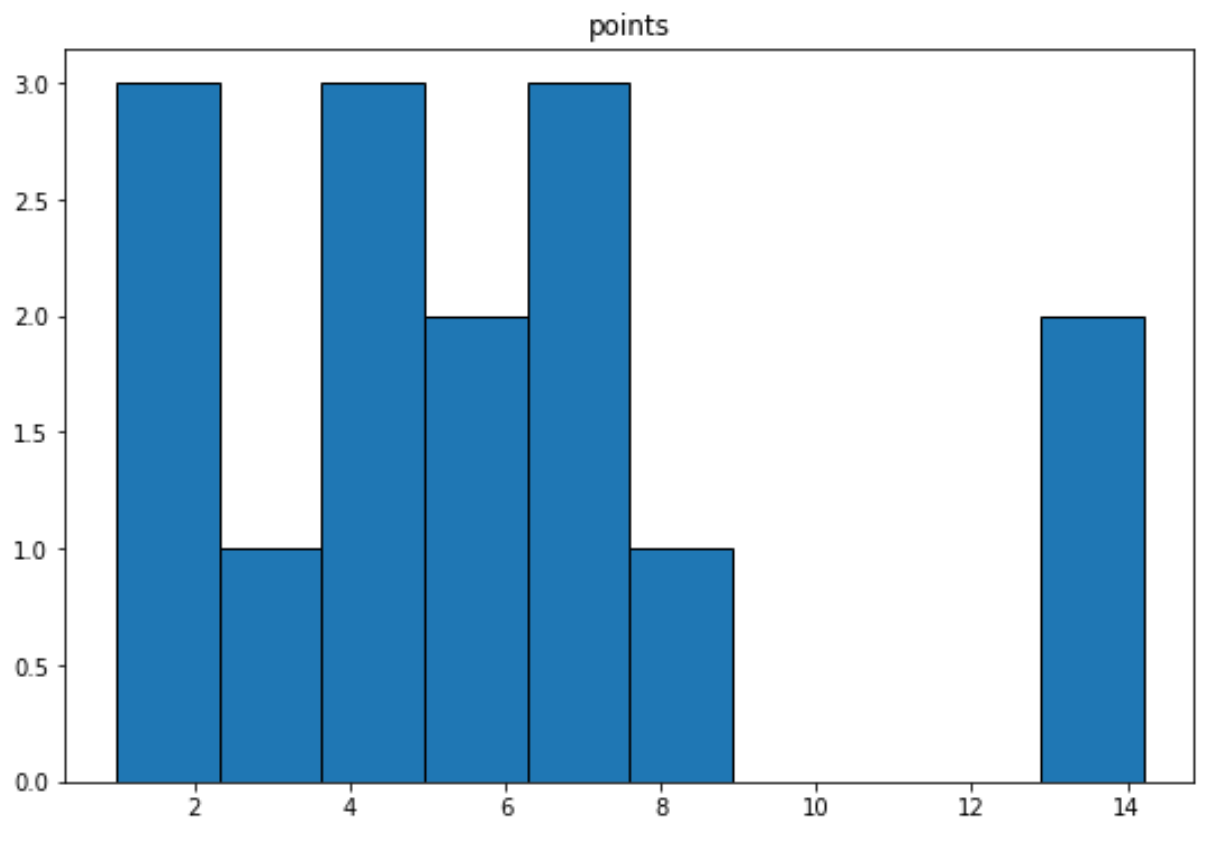
관련 항목: Pandas DataFrame에서 히스토그램을 만드는 방법
다음 구문을 사용하여 “점” 변수에 대한 밀도 곡선을 만들 수 있습니다.
import seaborn as sns sns. kdeplot (df[' points '])
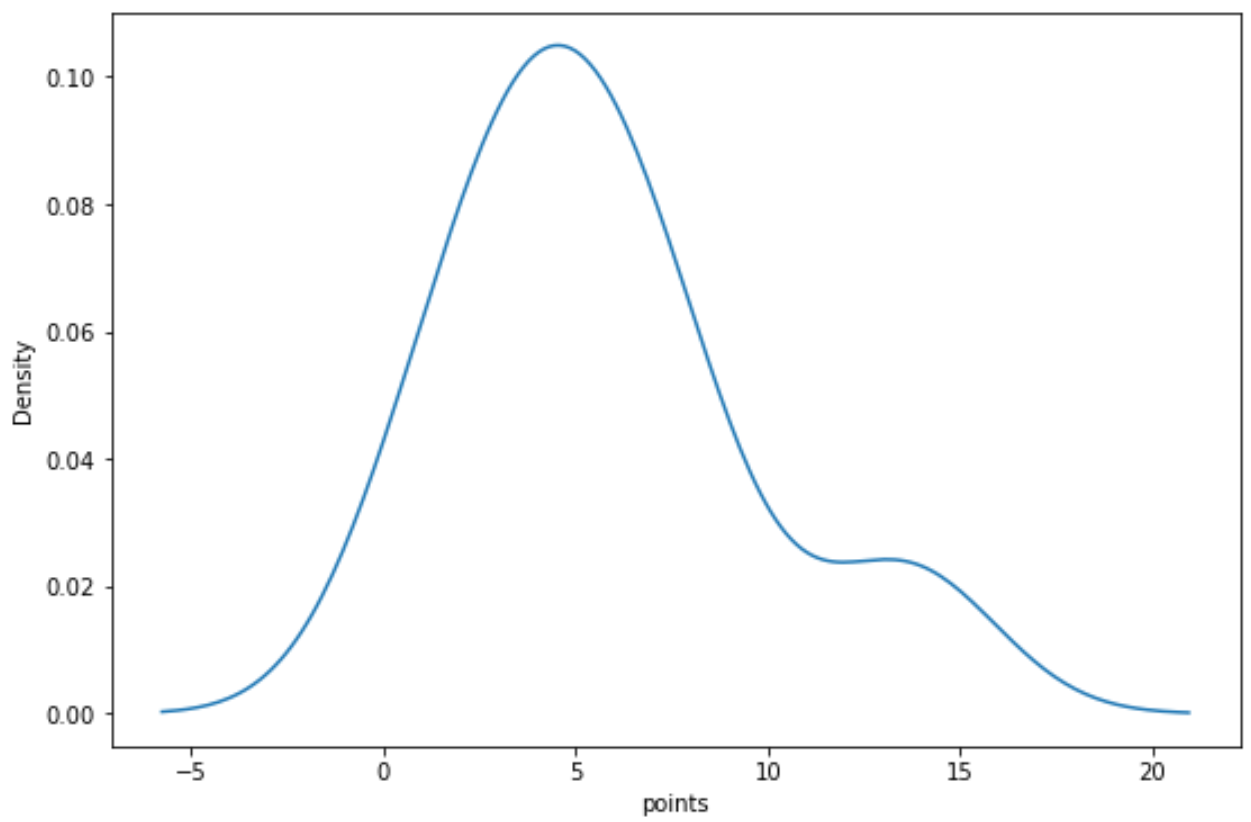
관련 항목: Matplotlib에서 밀도 플롯을 만드는 방법
이러한 각 그래프는 “포인트” 변수 값의 분포를 시각화하는 고유한 방법을 제공합니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기