Python에서 정밀 리콜 곡선을 만드는 방법
기계 학습에서 분류 모델을 사용할 때 모델 품질을 평가하기 위해 자주 사용하는 두 가지 지표는 정밀도와 재현율입니다.
정확도 : 전체 긍정적 예측을 기준으로 긍정적 예측을 수정합니다.
이는 다음과 같이 계산됩니다.
- 정확도 = 참양성 / (참양성 + 거짓양성)
알림 : 전체 실제 긍정에 대한 긍정적 예측 수정
이는 다음과 같이 계산됩니다.
- 미리 알림 = 참 긍정 / (참 긍정 + 거짓 부정)
특정 모델의 정밀도와 재현율을 시각화하기 위해 정밀도-재현율 곡선을 만들 수 있습니다. 이 곡선은 다양한 임계값에 대한 정밀도와 재현율 간의 균형을 보여줍니다.
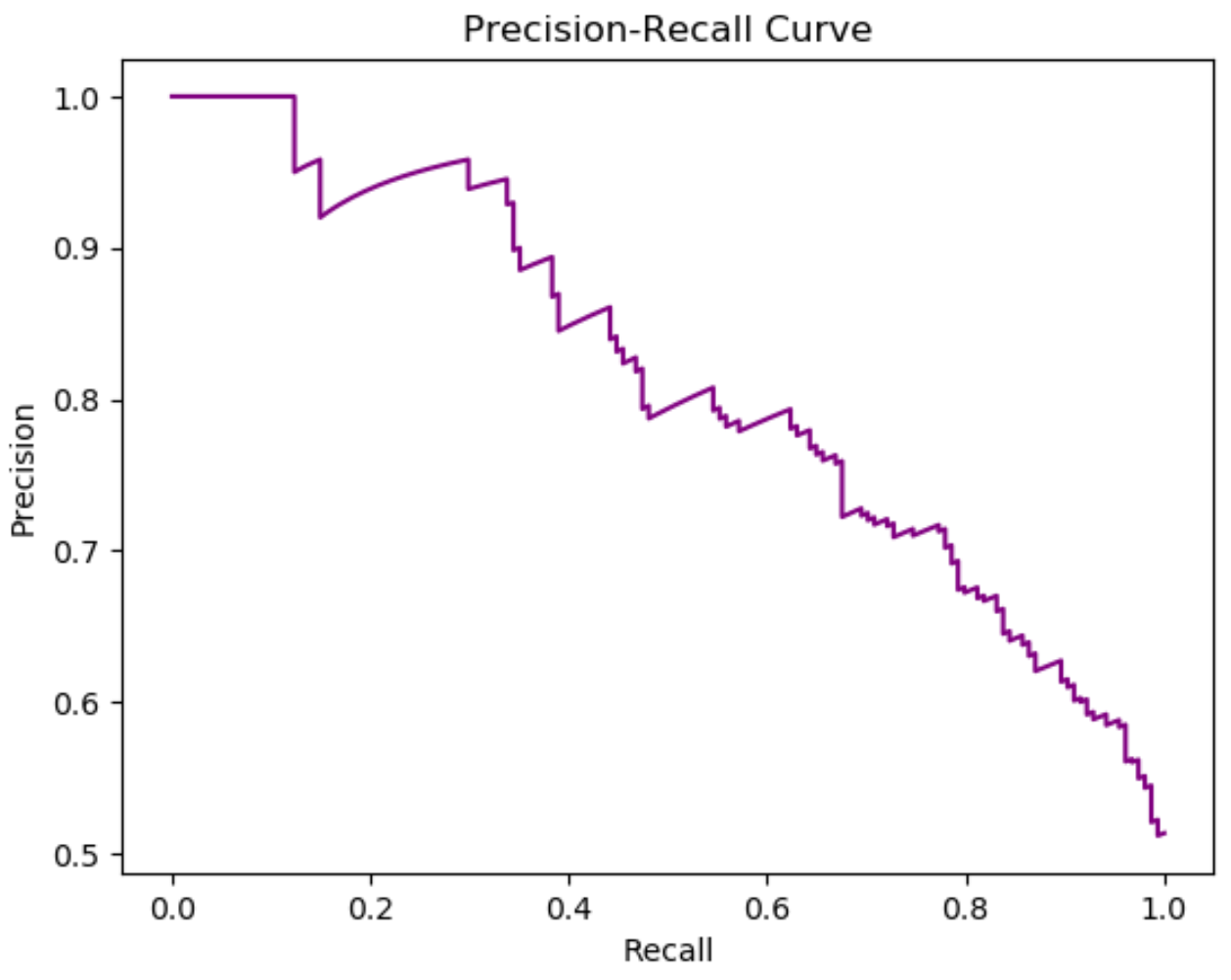
다음 단계별 예에서는 Python에서 로지스틱 회귀 모델에 대한 정밀 재현율 곡선을 만드는 방법을 보여줍니다.
1단계: 패키지 가져오기
먼저 필요한 패키지를 가져옵니다.
from sklearn import datasets from sklearn. model_selection import train_test_split from sklearn. linear_model import LogisticRegression from sklearn. metrics import precision_recall_curve import matplotlib. pyplot as plt
2단계: 로지스틱 회귀 모델 적합
다음으로 데이터세트를 생성하고 여기에 로지스틱 회귀 모델을 적용하겠습니다.
#create dataset with 5 predictor variables
X, y = datasets. make_classification (n_samples= 1000 ,
n_features= 4 ,
n_informative= 3 ,
n_redundant= 1 ,
random_state= 0 )
#split dataset into training and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= .3 , random_state= 0 )
#fit logistic regression model to dataset
classifier = LogisticRegression()
classify. fit (X_train, y_train)
#use logistic regression model to make predictions
y_score = classify. predict_proba (X_test)[:, 1 ]
3단계: 정밀도-재현율 곡선 만들기
다음으로 모델의 정밀도와 재현율을 계산하고 정밀도-재현율 곡선을 만듭니다.
#calculate precision and recall
precision, recall, thresholds = precision_recall_curve(y_test, y_score)
#create precision recall curve
fig, ax = plt. subplots ()
ax. plot (recall, precision, color=' purple ')
#add axis labels to plot
ax. set_title (' Precision-Recall Curve ')
ax. set_ylabel (' Precision ')
ax. set_xlabel (' Recall ')
#displayplot
plt. show ()
x축은 재현율을 나타내고 y축은 다양한 임계값에 대한 정밀도를 나타냅니다.
재현율이 증가하면 정밀도가 감소합니다.
이는 두 측정항목 간의 절충안을 나타냅니다. 모델의 재현율을 높이려면 정밀도가 감소해야 하며 그 반대의 경우도 마찬가지입니다.
추가 리소스
Python에서 로지스틱 회귀를 수행하는 방법
Python에서 혼동 행렬을 만드는 방법
ROC 곡선을 해석하는 방법(예제 포함)
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기