Python에서 로지스틱 회귀 곡선을 그리는 방법
Seaborn 데이터 시각화 라이브러리의 regplot() 함수를 사용하여 Python에서 로지스틱 회귀 곡선을 그릴 수 있습니다.
import seaborn as sns sns. regplot (x=x, y=y, data=df, logistic= True , ci= None )
다음 예에서는 실제로 이 구문을 사용하는 방법을 보여줍니다.
예: Python에서 로지스틱 회귀 곡선 그리기
이 예에서는 Introduction to Statistical Learning 책 의 기본 데이터세트를 사용합니다. 다음 코드를 사용하여 데이터세트 요약을 로드하고 표시할 수 있습니다.
#import dataset from CSV file on Github url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/default.csv" data = pd. read_csv (url) #view first six rows of dataset data[0:6] default student balance income 0 0 0 729.526495 44361.625074 1 0 1 817.180407 12106.134700 2 0 0 1073.549164 31767.138947 3 0 0 529.250605 35704.493935 4 0 0 785.655883 38463.495879 5 0 1 919.588530 7491.558572
이 데이터 세트에는 10,000명의 개인에 대한 다음 정보가 포함되어 있습니다.
- 기본값: 개인이 채무 불이행을 했는지 여부를 나타냅니다.
- 학생: 개인이 학생인지 여부를 나타냅니다.
- 잔액: 개인이 보유하고 있는 평균 잔액입니다.
- 소득: 개인의 소득.
특정 개인이 채무를 불이행할 확률을 예측하기 위해 “균형”을 사용하는 로지스틱 회귀 모델을 구축한다고 가정해 보겠습니다.
다음 코드를 사용하여 로지스틱 회귀 곡선을 그릴 수 있습니다.
#define the predictor variable and the response variable
x = data[' balance ']
y = data[' default ']
#plot logistic regression curve
sns. regplot (x=x, y=y, data=data, logistic= True , ci= None )
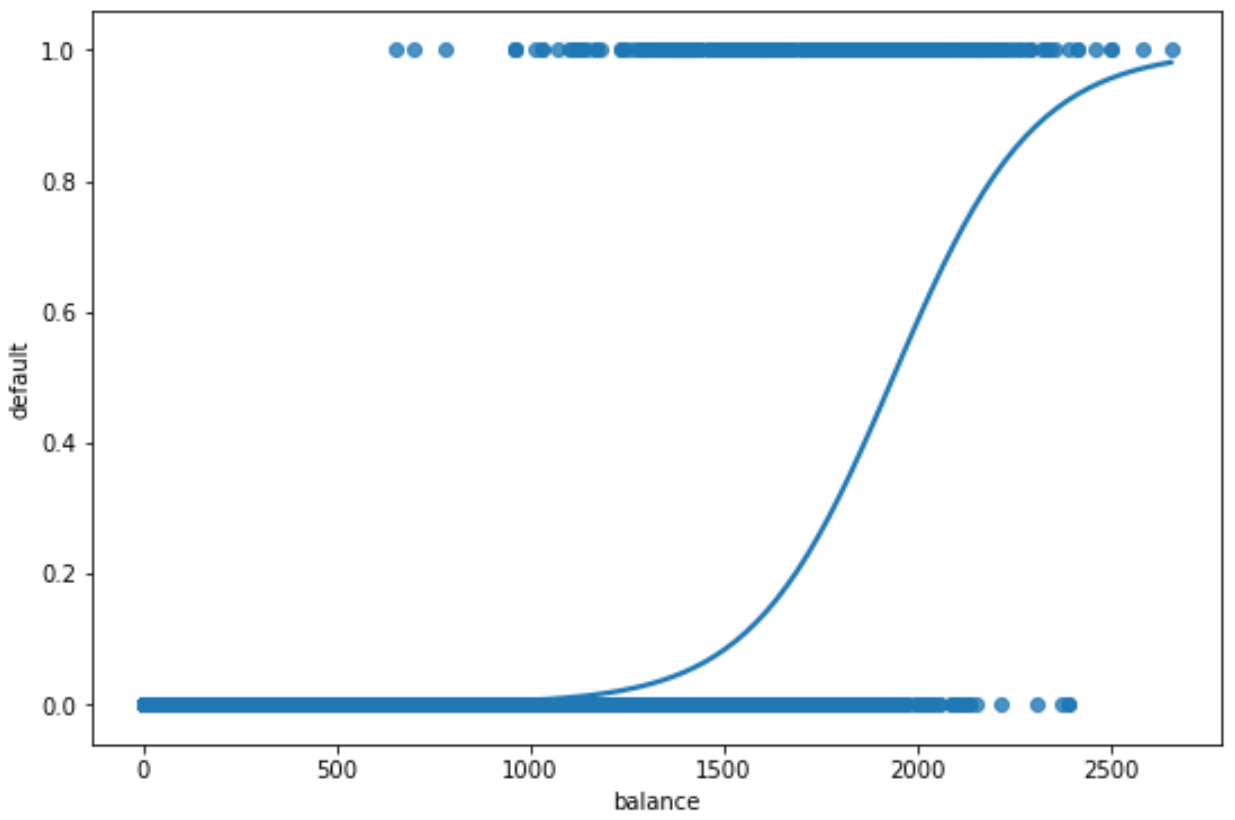
x축은 예측변수 ‘균형’의 값을 나타내고, y축은 예측된 부도확률을 나타낸다.
우리는 더 높은 균형 가치가 개인이 채무를 불이행할 확률이 더 높다는 것을 분명히 볼 수 있습니다.
Scatter_kws 및 line_kws를 사용하여 플롯의 점과 곡선의 색상을 변경할 수도 있습니다.
#define the predictor variable and the response variable
x = data[' balance ']
y = data[' default ']
#plot logistic regression curve with black points and red line
sns. regplot (x=x, y=y, data=data, logistic= True , ci= None ),
scatter_kws={' color ': ' black '}, line_kws={' color ': ' red '})
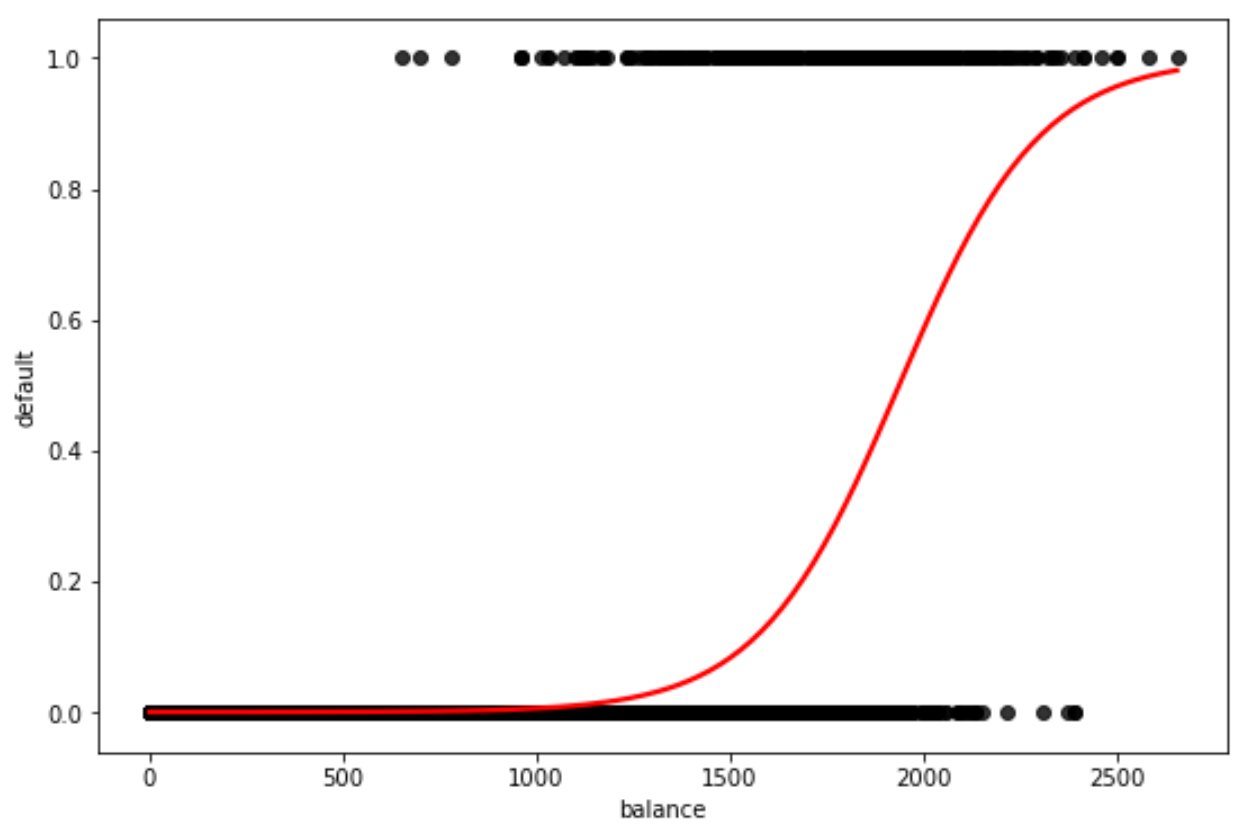
플롯에서 원하는 색상을 자유롭게 선택하십시오.
추가 리소스
다음 자습서에서는 로지스틱 회귀에 대한 추가 정보를 제공합니다.
로지스틱 회귀 소개
로지스틱 회귀 결과를 보고하는 방법
Python에서 로지스틱 회귀를 수행하는 방법(단계별)
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기