Python에서 이변량 분석을 수행하는 방법: 예제 포함
이변량 분석이라는 용어는 두 변수에 대한 분석을 의미합니다. 접두사 “bi”가 “둘”을 의미하기 때문에 이것을 기억할 수 있습니다.
이변량 분석의 목표는 두 변수 간의 관계를 이해하는 것입니다.
이변량 분석을 수행하는 세 가지 일반적인 방법은 다음과 같습니다.
1. 포인트 클라우드
2. 상관계수
3. 단순 선형 회귀
다음 예에서는 두 가지 변수( (1) 공부에 소비한 시간 및 (2) 20명의 학생이 얻은 시험 점수)에 대한 정보가 포함된 다음 pandas DataFrame을 사용하여 Python에서 이러한 각 유형의 이변량 분석을 수행하는 방법을 보여줍니다.
import pandas as pd #createDataFrame df = pd. DataFrame ({' hours ': [1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 5, 5, 6, 6, 6, 7, 8], ' score ': [75, 66, 68, 74, 78, 72, 85, 82, 90, 82, 80, 88, 85, 90, 92, 94, 94, 88, 91, 96]}) #view first five rows of DataFrame df. head () hours score 0 1 75 1 1 66 2 1 68 3 2 74 4 2 78
1. 포인트 클라우드
다음 구문을 사용하여 공부한 시간과 시험 결과의 산점도를 만들 수 있습니다.
import matplotlib. pyplot as plt #create scatterplot of hours vs. score plt. scatter (df. hours , df. score ) plt. title (' Hours Studied vs. Exam Score ') plt. xlabel (' Hours Studied ') plt. ylabel (' Exam Score ')
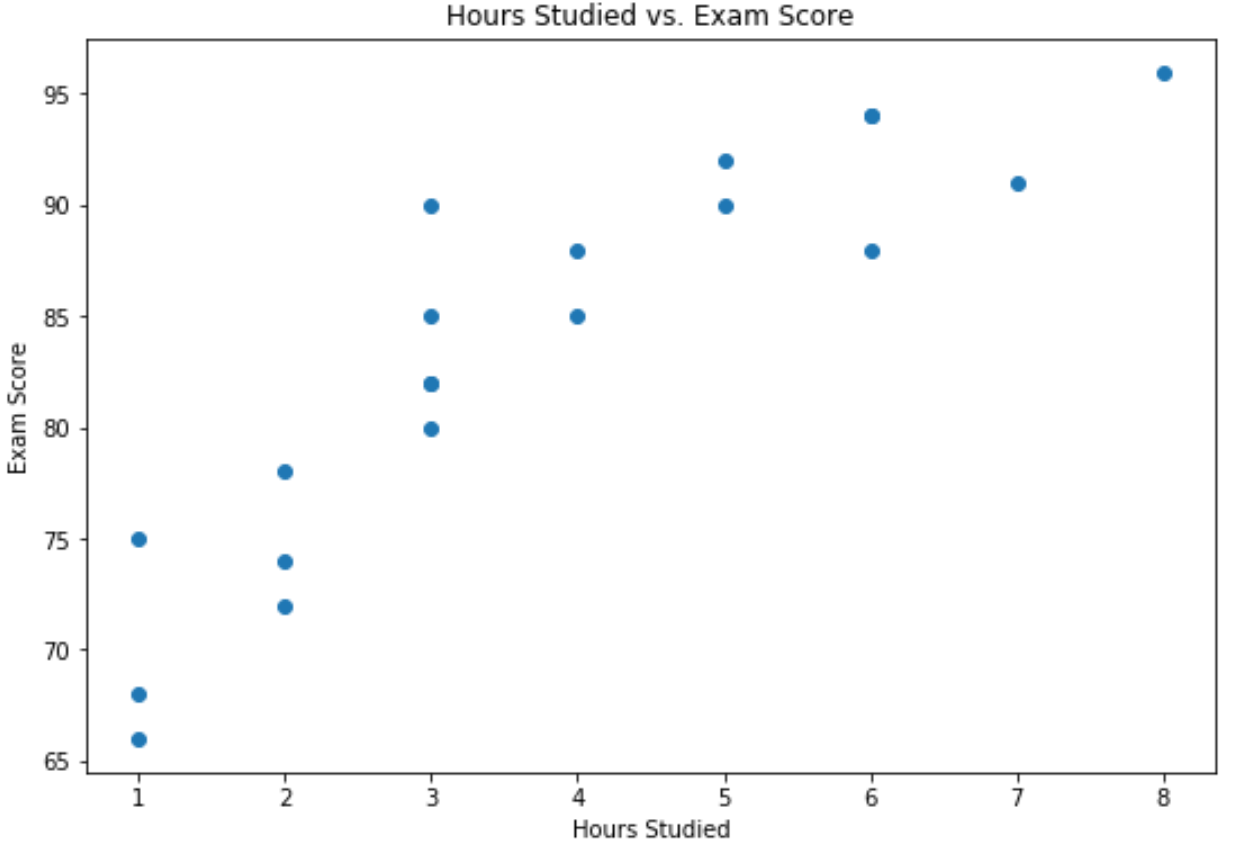
x축은 공부한 시간을 나타내고 y축은 시험에서 얻은 성적을 나타냅니다.
그래프는 두 변수 사이에 긍정적인 관계가 있음을 보여줍니다. 학습 시간이 증가할수록 시험 점수도 증가하는 경향이 있습니다.
2. 상관계수
피어슨 상관 계수는 두 변수 간의 선형 관계를 수량화하는 방법입니다.
Pandas에서 corr() 함수를 사용하여 상관 행렬을 만들 수 있습니다.
#create correlation matrix df. corr () hours score hours 1.000000 0.891306 score 0.891306 1.000000
상관계수는 0.891 로 나타났다. 이는 공부한 시간과 시험 성적 사이에 강한 양의 상관관계가 있음을 나타냅니다.
3. 단순 선형 회귀
단순 선형 회귀는 두 변수 간의 관계를 수량화하는 데 사용할 수 있는 통계 방법입니다.
statsmodels 패키지의 OLS() 함수를 사용하여 공부한 시간과 받은 시험 결과에 대한 간단한 선형 회귀 모델을 빠르게 맞출 수 있습니다.
import statsmodels. api as sm #define response variable y = df[' score '] #define explanatory variable x = df[[' hours ']] #add constant to predictor variables x = sm. add_constant (x) #fit linear regression model model = sm. OLS (y,x). fit () #view model summary print ( model.summary ()) OLS Regression Results ==================================================== ============================ Dept. Variable: R-squared score: 0.794 Model: OLS Adj. R-squared: 0.783 Method: Least Squares F-statistic: 69.56 Date: Mon, 22 Nov 2021 Prob (F-statistic): 1.35e-07 Time: 16:15:52 Log-Likelihood: -55,886 No. Observations: 20 AIC: 115.8 Df Residuals: 18 BIC: 117.8 Model: 1 Covariance Type: non-robust ==================================================== ============================ coef std err t P>|t| [0.025 0.975] -------------------------------------------------- ---------------------------- const 69.0734 1.965 35.149 0.000 64.945 73.202 hours 3.8471 0.461 8.340 0.000 2.878 4.816 ==================================================== ============================ Omnibus: 0.171 Durbin-Watson: 1.404 Prob(Omnibus): 0.918 Jarque-Bera (JB): 0.177 Skew: 0.165 Prob(JB): 0.915 Kurtosis: 2.679 Cond. No. 9.37 ==================================================== ============================
적합 회귀 방정식은 다음과 같습니다.
시험 점수 = 69.0734 + 3.8471*(공부한 시간)
이는 공부한 시간이 추가될 때마다 시험 점수가 평균 3.8471 증가하는 것과 관련이 있음을 알려줍니다.
또한 적합 회귀 방정식을 사용하여 총 공부 시간을 기준으로 학생이 받게 될 점수를 예측할 수 있습니다.
예를 들어, 3시간 동안 공부한 학생은 81.6147 점을 받아야 합니다.
- 시험 점수 = 69.0734 + 3.8471*(공부한 시간)
- 시험 점수 = 69.0734 + 3.8471*(3)
- 시험 결과 = 81.6147
추가 리소스
다음 자습서에서는 이변량 분석에 대한 추가 정보를 제공합니다.
이변량 분석 소개
실생활에서 사용되는 이변량 데이터의 5가지 예
단순 선형 회귀 소개
피어슨 상관 계수 소개
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기