R의 선형 판별 분석(단계별)
선형 판별 분석은 일련의 예측 변수가 있고 응답 변수를 두 개 이상의 클래스로 분류하려는 경우 사용할 수 있는 방법입니다.
이 튜토리얼에서는 R에서 선형 판별 분석을 수행하는 방법에 대한 단계별 예를 제공합니다.
1단계: 필요한 라이브러리 로드
먼저 이 예제에 필요한 라이브러리를 로드합니다.
library (MASS)
library (ggplot2)
2단계: 데이터 로드
이 예에서는 R에 내장된 붓꽃 데이터 세트를 사용합니다. 다음 코드는 이 데이터 세트를 로드하고 표시하는 방법을 보여줍니다.
#attach iris dataset to make it easy to work with attach(iris) #view structure of dataset str(iris) 'data.frame': 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width: num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... $Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $Petal.Width: num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species: Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 ...
데이터 세트에는 총 5개의 변수와 150개의 관측치가 포함되어 있는 것을 볼 수 있습니다.
이 예에서는 특정 꽃이 어떤 종에 속하는지 분류하기 위해 선형 판별 분석 모델을 구축합니다.
모델에서 다음 예측 변수를 사용합니다.
- 꽃받침 길이
- 꽃받침.폭
- 꽃잎.길이
- 꽃잎.폭
그리고 이를 사용하여 다음 세 가지 잠재적 클래스를 지원하는 종 응답 변수를 예측합니다.
- 세토사
- 베르시컬러
- 여자 이름
3단계: 데이터 크기 조정
선형 판별 분석의 주요 가정 중 하나는 각 예측 변수의 분산이 동일하다는 것입니다. 이 가정이 충족되는지 확인하는 간단한 방법은 평균이 0이고 표준편차가 1이 되도록 각 변수의 크기를 조정하는 것입니다.
scale() 함수를 사용하여 R에서 이 작업을 빠르게 수행할 수 있습니다.
#scale each predictor variable (ie first 4 columns)
iris[1:4] <- scale(iris[1:4])
apply() 함수를 사용하여 각 예측 변수의 평균이 0이고 표준 편차가 1인지 확인할 수 있습니다.
#find mean of each predictor variable apply(iris[1:4], 2, mean) Sepal.Length Sepal.Width Petal.Length Petal.Width -4.484318e-16 2.034094e-16 -2.895326e-17 -3.663049e-17 #find standard deviation of each predictor variable apply(iris[1:4], 2, sd) Sepal.Length Sepal.Width Petal.Length Petal.Width 1 1 1 1
4단계: 훈련 및 테스트 샘플 생성
다음으로 데이터 세트를 모델을 훈련하기 위한 훈련 세트와 모델을 테스트하기 위한 테스트 세트로 분할합니다.
#make this example reproducible set.seed(1) #Use 70% of dataset as training set and remaining 30% as testing set sample <- sample(c( TRUE , FALSE ), nrow (iris), replace = TRUE , prob =c(0.7,0.3)) train <- iris[sample, ] test <- iris[!sample, ]
5단계: LDA 모델 조정
다음으로 MASS 패키지의 lda() 함수를 사용하여 LDA 모델을 데이터에 적용합니다.
#fit LDA model model <- lda(Species~., data=train) #view model output model Call: lda(Species ~ ., data = train) Prior probabilities of groups: setosa versicolor virginica 0.3207547 0.3207547 0.3584906 Group means: Sepal.Length Sepal.Width Petal.Length Petal.Width setosa -1.0397484 0.8131654 -1.2891006 -1.2570316 versicolor 0.1820921 -0.6038909 0.3403524 0.2208153 virginica 0.9582674 -0.1919146 1.0389776 1.1229172 Coefficients of linear discriminants: LD1 LD2 Sepal.Length 0.7922820 0.5294210 Sepal.Width 0.5710586 0.7130743 Petal.Length -4.0762061 -2.7305131 Petal.Width -2.0602181 2.6326229 Proportion of traces: LD1 LD2 0.9921 0.0079
모델 결과를 해석하는 방법은 다음과 같습니다.
그룹 사전 확률: 훈련 세트에 있는 각 종의 비율을 나타냅니다. 예를 들어 훈련 세트의 모든 관측치 중 35.8%는 virginica 종에 대한 것입니다.
그룹 평균: 각 종에 대한 각 예측 변수의 평균 값을 표시합니다.
선형 판별 계수: LDA 모델 결정 규칙을 훈련하는 데 사용되는 예측 변수의 선형 조합을 표시합니다. 예를 들어:
- LD1: 0.792 * 꽃받침 길이 + 0.571 * 꽃받침 너비 – 4.076 * 꽃잎 길이 – 2.06 * 꽃잎 너비
- LD2: 0.529 * 꽃받침 길이 + 0.713 * 꽃받침 너비 – 2.731 * 꽃잎 길이 + 2.63 * 꽃잎 너비
추적 비율: 각 선형 판별 함수에 의해 달성된 분리 비율을 표시합니다.
6단계: 모델을 사용하여 예측하기
훈련 데이터를 사용하여 모델을 맞춘 후에는 이를 사용하여 테스트 데이터에 대한 예측을 할 수 있습니다.
#use LDA model to make predictions on test data predicted <- predict (model, test) names(predicted) [1] "class" "posterior" "x"
그러면 세 가지 변수가 포함된 목록이 반환됩니다.
- 클래스: 예측된 클래스
- 사후: 관측치가 각 클래스에 속할 사후 확률
- x: 선형 판별
테스트 데이터 세트의 처음 6개 관찰에 대한 각 결과를 빠르게 시각화할 수 있습니다.
#view predicted class for first six observations in test set head(predicted$class) [1] setosa setosa setosa setosa setosa setosa Levels: setosa versicolor virginica #view posterior probabilities for first six observations in test set head(predicted$posterior) setosa versicolor virginica 4 1 2.425563e-17 1.341984e-35 6 1 1.400976e-21 4.482684e-40 7 1 3.345770e-19 1.511748e-37 15 1 6.389105e-31 7.361660e-53 17 1 1.193282e-25 2.238696e-45 18 1 6.445594e-22 4.894053e-41 #view linear discriminants for first six observations in test set head(predicted$x) LD1 LD2 4 7.150360 -0.7177382 6 7.961538 1.4839408 7 7.504033 0.2731178 15 10.170378 1.9859027 17 8.885168 2.1026494 18 8.113443 0.7563902
다음 코드를 사용하여 LDA 모델이 종을 올바르게 예측한 관측치의 비율을 확인할 수 있습니다.
#find accuracy of model
mean(predicted$class==test$Species)
[1] 1
모델은 테스트 데이터 세트의 관측치 중 100% 에 대해 종을 정확하게 예측한 것으로 나타났습니다.
실제 세계에서 LDA 모델은 각 클래스의 결과를 정확하게 예측하는 경우가 거의 없지만, 이 붓꽃 데이터세트는 기계 학습 알고리즘이 매우 잘 수행되는 경향이 있는 방식으로 간단히 구성되었습니다.
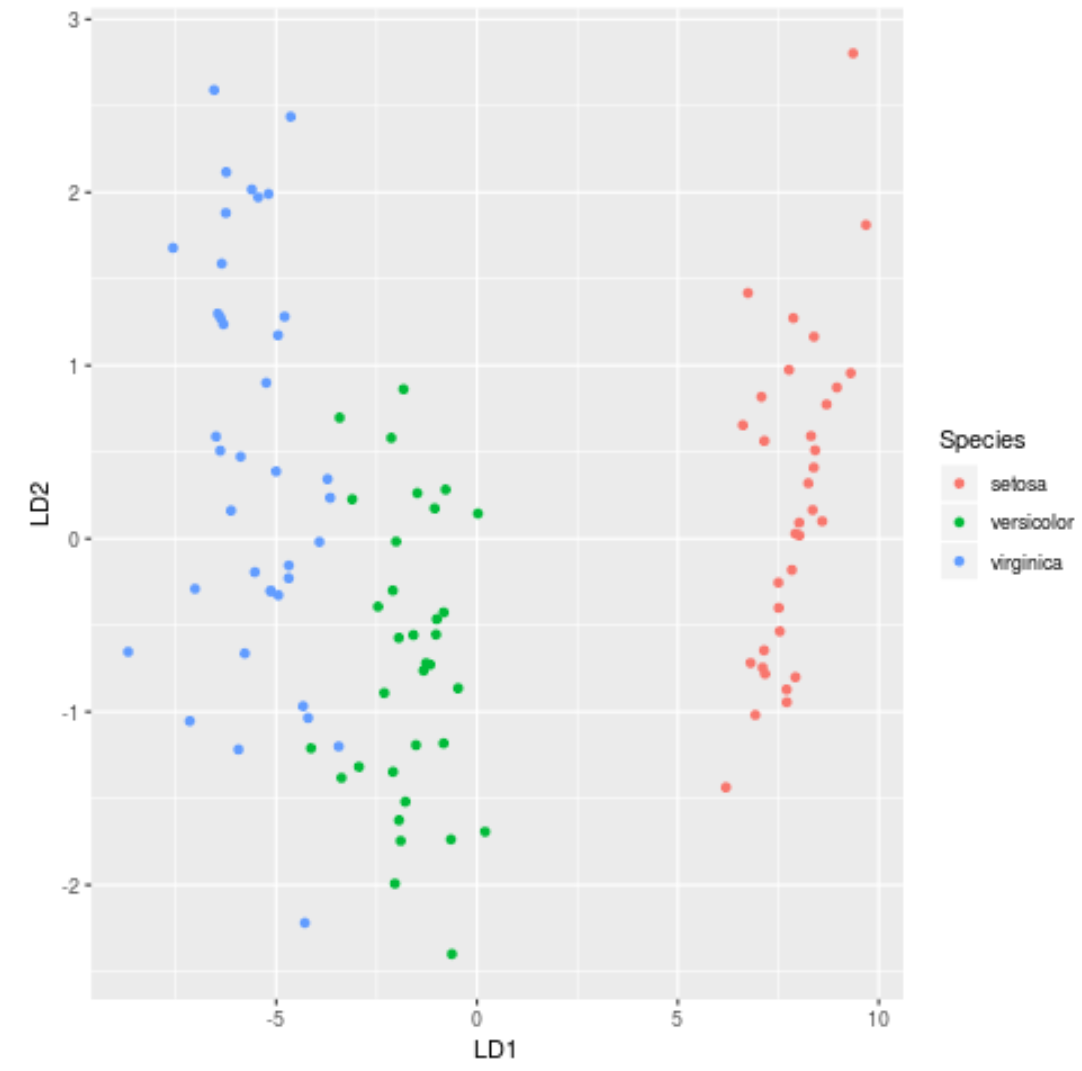
7단계: 결과 시각화
마지막으로 LDA 플롯을 생성하여 모델의 선형 판별을 시각화하고 데이터 세트에서 세 가지 다른 종을 얼마나 잘 분리하는지 시각화할 수 있습니다.
#define data to plot lda_plot <- cbind(train, predict(model)$x) #createplot ggplot(lda_plot, aes (LD1, LD2)) + geom_point( aes (color=Species))
이 튜토리얼에서 사용된 전체 R 코드는 여기에서 찾을 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기