R에서 fisher의 lsd(최소 유의차)를 사용하는 방법
일원 분산 분석은 3개 이상의 독립 그룹 평균 간에 통계적으로 유의한 차이가 있는지 여부를 확인하는 데 사용됩니다.
일원 분산 분석에 사용된 가정은 다음과 같습니다.
- H 0 : 각 그룹의 평균이 동일합니다.
- H A : 적어도 한 가지 방법은 다른 방법과 다릅니다.
ANOVA의 p-값이 특정 유의 수준(예: α = 0.05)보다 낮으면 귀무 가설을 기각하고 그룹 평균 중 하나 이상이 다른 평균과 다르다는 결론을 내릴 수 있습니다.
하지만 어떤 그룹이 서로 다른지 정확히 알기 위해서는 사후 테스트를 수행해야 합니다.
일반적으로 사용되는 사후 테스트는 Fisher의 LSD(최소 유의차) 테스트 입니다.
agricolae 패키지의 LSD.test() 함수를 사용하여 R에서 이 테스트를 수행할 수 있습니다.
다음 예에서는 이 기능을 실제로 사용하는 방법을 보여줍니다.
예: R에서 Fisher의 LSD 테스트
교수가 세 가지 서로 다른 학습 방법이 학생들 사이에서 서로 다른 시험 점수로 이어지는지 여부를 알고 싶어한다고 가정해 보겠습니다.
이를 테스트하기 위해 그녀는 각 학습 기술을 사용하도록 10명의 학생을 무작위로 할당하고 그들의 시험 결과를 기록합니다.
다음 표는 사용된 학습 기법에 따른 각 학생의 시험 결과를 보여줍니다.
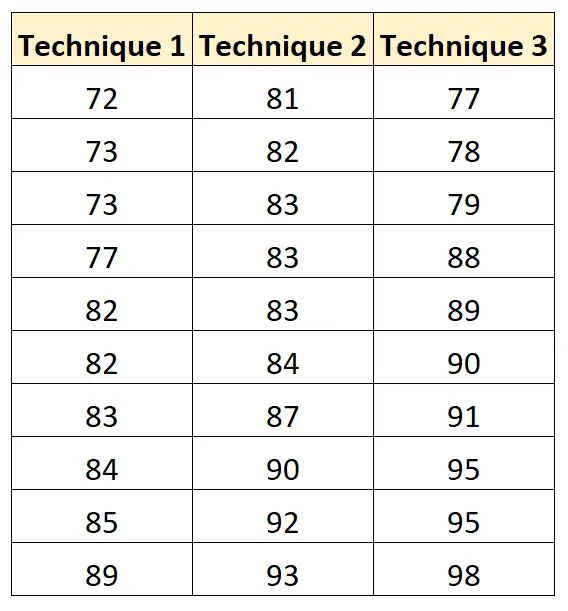
다음 코드를 사용하여 이 데이터 세트를 생성하고 R에서 이에 대한 단방향 ANOVA를 수행할 수 있습니다.
#create data frame
df <- data. frame (technique = rep(c("tech1", "tech2", "tech3"), each = 10 ),
score = c(72, 73, 73, 77, 82, 82, 83, 84, 85, 89,
81, 82, 83, 83, 83, 84, 87, 90, 92, 93,
77, 78, 79, 88, 89, 90, 91, 95, 95, 98))
#view first six rows of data frame
head(df)
technical score
1 tech1 72
2 tech1 73
3 tech1 73
4 tech1 77
5 tech1 82
6 tech1 82
#fit one-way ANOVA
model <- aov(score ~ technique, data = df)
#view summary of one-way ANOVA
summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
technical 2 341.6 170.80 4.623 0.0188 *
Residuals 27,997.6 36.95
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
ANOVA 테이블의 p-값(0.0188)이 0.05보다 작으므로 세 그룹 간의 모든 평균 시험 점수가 동일하지 않다는 결론을 내릴 수 있습니다.
따라서 Fisher의 LSD 테스트를 수행하여 어떤 그룹 평균이 다른지 확인할 수 있습니다.
다음 코드는 이를 수행하는 방법을 보여줍니다.
library (agricolae)
#perform Fisher's LSD
print( LSD.test (model," technic "))
$statistics
MSerror Df Mean CV t.value LSD
36.94815 27 84.6 7.184987 2.051831 5.57767
$parameters
test p.adjusted name.t ntr alpha
Fisher-LSD none technical 3 0.05
$means
std score r LCL UCL Min Max Q25 Q50 Q75
tech1 80.0 5.868939 10 76.05599 83.94401 72 89 74.00 82.0 83.75
tech2 85.8 4.391912 10 81.85599 89.74401 81 93 83.00 83.5 89.25
tech3 88.0 7.557189 10 84.05599 91.94401 77 98 81.25 89.5 94.00
$comparison
NULL
$groups
score groups
tech3 88.0 a
tech2 85.8a
tech1 80.0 b
attr(,"class")
[1] “group”
결과에서 가장 관심을 끄는 부분은 $groups 섹션입니다. 그룹 열에 다른 문자가 있는 기술은 매우 다릅니다.
결과에서 우리는 다음을 볼 수 있습니다:
- 기술 1과 기술 3의 평균 시험 점수는 상당히 다릅니다(tech1의 값은 “b”이고 tech3의 값은 “a”이므로).
- 기술 1과 기술 2의 평균 시험 점수는 상당히 다릅니다(tech1의 값은 “b”이고 tech2의 값은 “a”이므로).
- 기술 2와 기술 3은 평균 시험 점수가 크게 다르지 않습니다 (둘 다 “a” 값을 갖기 때문).
추가 리소스
다음 튜토리얼에서는 R에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
R에서 일원 분산 분석을 수행하는 방법
R에서 Bonferroni 사후 테스트를 수행하는 방법
R에서 Scheffe 사후 테스트를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기