R에서 csv 파일의 특정 줄을 읽는 방법
다음 방법을 사용하여 R의 CSV 파일에서 특정 줄을 읽을 수 있습니다.
방법 1: 특정 행에서 CSV 파일 가져오기
df <- read. csv (" my_data.csv ", skip= 2 )
이 특정 예에서는 CSV 파일의 처음 두 줄을 건너뛰고 세 번째 줄부터 시작하여 파일의 다른 모든 줄을 가져옵니다.
방법 2: 행이 조건을 충족하는 CSV 파일 가져오기
library (sqldf) df <- read. csv . sql (" my_data.csv ", sql = " select * from file where `points` > 90 ", eol = " \n ")
이 특정 예에서는 “포인트” 열의 값이 90보다 큰 CSV 파일의 행만 가져옵니다.
다음 예에서는 my_data.csv 라는 CSV 파일을 사용하여 실제로 이러한 각 방법을 사용하는 방법을 보여줍니다.
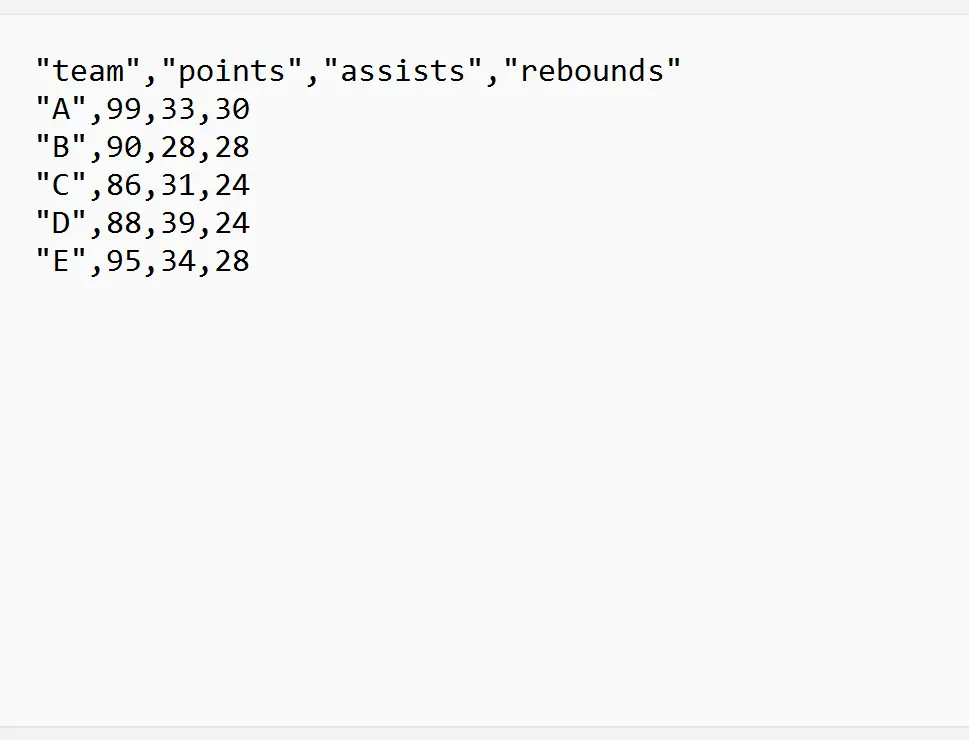
예시 1: 특정 행에서 CSV 파일 가져오기
다음 코드는 CSV 파일을 가져오고 파일의 처음 두 줄을 무시하는 방법을 보여줍니다.
#import data frame and skip first two rows
df <- read. csv (' my_data.csv ', skip= 2 )
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
CSV 파일을 가져올 때 처음 두 줄(팀 A 및 B 포함)은 무시되었습니다.
기본적으로 R은 사용 가능한 다음 행의 값을 열 이름으로 사용하려고 시도합니다.
열 이름을 바꾸려면 다음과 같이 names() 함수를 사용할 수 있습니다.
#rename columns
names(df) <- c(' team ', ' points ', ' assists ', ' rebounds ')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
예 2: 행이 조건을 충족하는 CSV 파일 가져오기
포인트 열의 값이 90보다 큰 CSV 파일의 행만 가져오려고 한다고 가정합니다.
이 작업을 수행하려면 sqldf 패키지의 read.csv.sql 함수를 사용할 수 있습니다.
library (sqldf)
#only import rows where points > 90
df <- read. csv . sql (" my_data.csv ",
sql = " select * from file where `points` > 90 ", eol = " \n ")
#view data frame
df
team points assists rebounds
1 “A” 99 33 30
2 “E” 95 34 28
‘포인트’ 열의 값이 90보다 큰 CSV 파일의 두 줄만 가져왔습니다.
참고 #1 : 이 예에서는 eol 인수를 사용하여 파일의 “줄 끝”이 개행을 나타내는 \n 으로 표시되도록 지정했습니다.
참고 #2: 이 예에서는 간단한 SQL 쿼리를 사용했지만 더 많은 조건으로 행을 필터링하기 위해 더 복잡한 쿼리를 작성할 수 있습니다.
추가 리소스
다음 튜토리얼에서는 R에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
R의 URL에서 CSV를 읽는 방법
R에서 여러 CSV 파일을 병합하는 방법
R에서 데이터 프레임을 CSV 파일로 내보내는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기