A: microbenchmark 패키지를 사용하여 실행 시간을 측정하는 방법
R의 microbenchmark 패키지를 사용하여 다양한 표현식의 실행 시간을 비교할 수 있습니다.
이를 수행하려면 다음 구문을 사용할 수 있습니다.
library (microbenchmark) #compare execution time of two different expressions microbenchmark( expression1, expression2) )
다음 예에서는 실제로 이 구문을 사용하는 방법을 보여줍니다.
예: R에서 microbenchmark() 사용
다양한 농구팀의 선수들이 득점한 점수에 대한 정보를 포함하는 다음과 같은 데이터 프레임이 R에 있다고 가정해 보겠습니다.
#make this example reproducible
set. seed ( 1 )
#create data frame
df <- data. frame (team=rep(c(' A ', ' B '), each= 500 ),
points=rnorm( 1000 , mean= 20 ))
#view data frame
head(df)
team points
1 A 19.37355
2 A 20.18364
3 A 19.16437
4 A 21.59528
5 A 20.32951
6 A 19.17953
이제 두 가지 다른 방법을 사용하여 각 팀의 플레이어가 득점한 평균 점수를 계산한다고 가정합니다.
- 방법 1 : Base R에서 Aggregate() 사용
- 방법 2 : dplyr의 group_by() 및 summarise_at() 사용
microbenchmark() 함수를 사용하여 이러한 각 표현식을 실행하는 데 걸리는 시간을 측정할 수 있습니다.
library (microbenchmark) library (dplyr) #time how long it takes to calculate mean value of points by team microbenchmark( aggregate(df$points, list(df$team), FUN=mean), df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) ) Unit: milliseconds express aggregate(df$points, list(df$team), FUN = mean) df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) min lq mean median uq max neval cld 1.307908 1.524078 1.852167 1.743568 2.093813 4.67408 100 a 6.788584 7.810932 9.946286 8.914692 10.239904 56.20928 100 b
microbenchmark() 함수는 각 표현식을 100번 실행하고 다음 측정항목을 측정합니다.
- min : 실행에 필요한 최소 시간
- lq : 완료하는 데 필요한 시간의 하위 사분위수(25번째 백분위수)
- 평균 : 실행에 소요되는 평균 시간
- median : 중앙값 실행 시간
- uq : 실행에 필요한 시간의 상위 사분위수(75번째 백분위수)
- max : 실행에 필요한 최대 시간
- neval : 각 표현식이 평가된 횟수
일반적으로 각 표현식을 실행하는 데 걸리는 평균 또는 중앙값 시간만 살펴봅니다.
결과에서 우리는 다음을 볼 수 있습니다:
- R 기반 방법을 사용하여 팀 포인트 평균을 계산하는 데 평균 1,852ms 의 시간이 걸렸습니다.
- dplyr 방식을 사용하여 팀당 평균 포인트를 계산하는 데 평균 9.946ms 의 시간이 걸렸습니다.
이러한 결과를 바탕으로 기본 R 방법이 훨씬 더 빠르다는 결론을 내렸습니다.
또한 boxplot() 함수를 사용하여 각 표현식을 실행하는 데 필요한 시간 분포를 시각화할 수 있습니다.
library (microbenchmark) library (dplyr) #time how long it takes to calculate mean value of points by team results <- microbenchmark( aggregate(df$points, list(df$team), FUN=mean), df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) ) #create boxplot to visualize results boxplot(results, names=c(' Base R ', ' dplyr '))
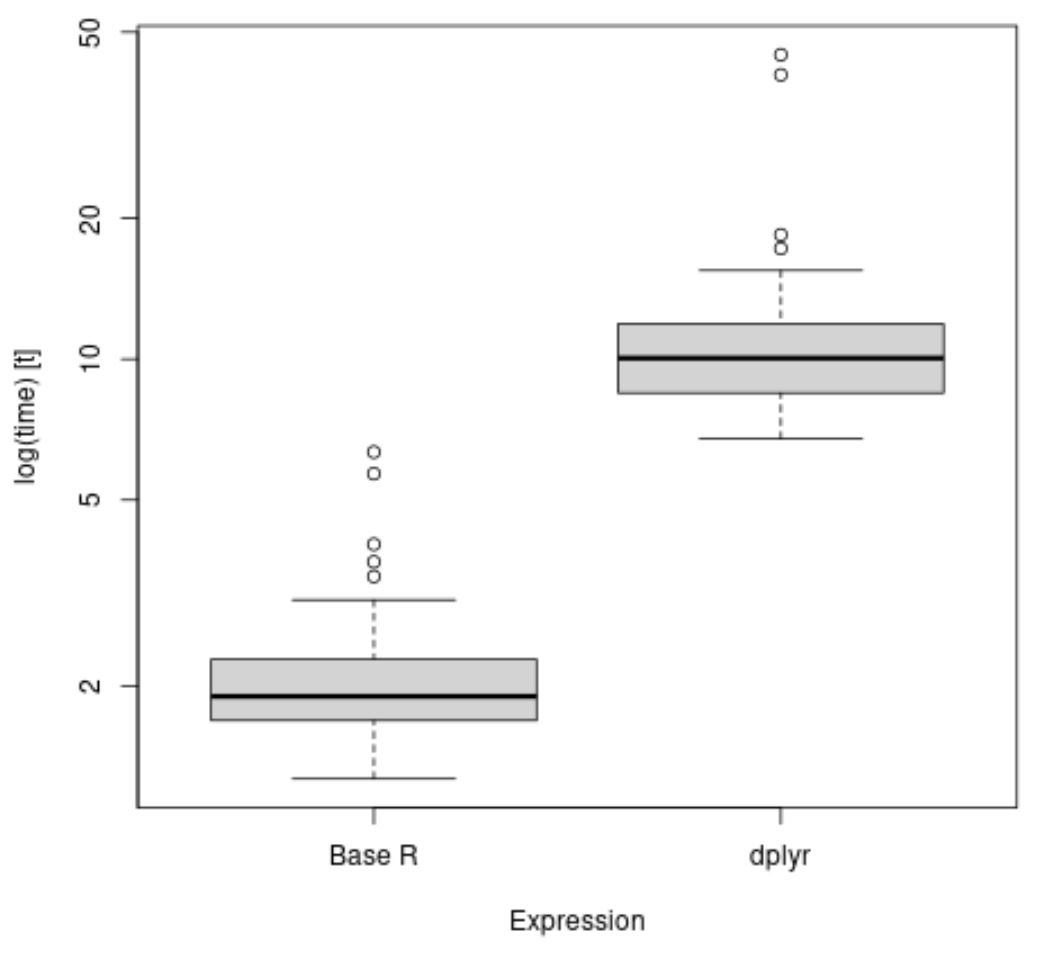
상자 그림에서 dplyr 방법이 팀당 평균 점수를 계산하는 데 평균적으로 더 오랜 시간이 걸리는 것을 확인할 수 있습니다.
참고 : 이 예에서는 microbenchmark() 함수를 사용하여 서로 다른 두 표현식의 실행 시간을 비교했지만 실제로는 원하는 만큼 많은 표현식을 비교할 수 있습니다.
추가 리소스
다음 튜토리얼에서는 R에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기