R에서 수정하는 방법: 중복된 'row.names'는 허용되지 않습니다.
R에서 발생할 수 있는 오류는 다음과 같습니다.
Error in read.table(file = file, header = header, sep = sep, quote = quote, : duplicate 'row.names' are not allowed
이 오류는 일반적으로 헤더 줄을 제외한 파일의 모든 줄 끝에 쉼표가 포함된 CSV 파일을 R로 읽으려고 할 때 발생합니다.
이 튜토리얼에서는 이 오류를 수정하는 방법을 정확하게 설명합니다.
오류를 재현하는 방법
my_data.csv 라는 다음과 같은 CSV 파일이 있다고 가정해 보겠습니다.
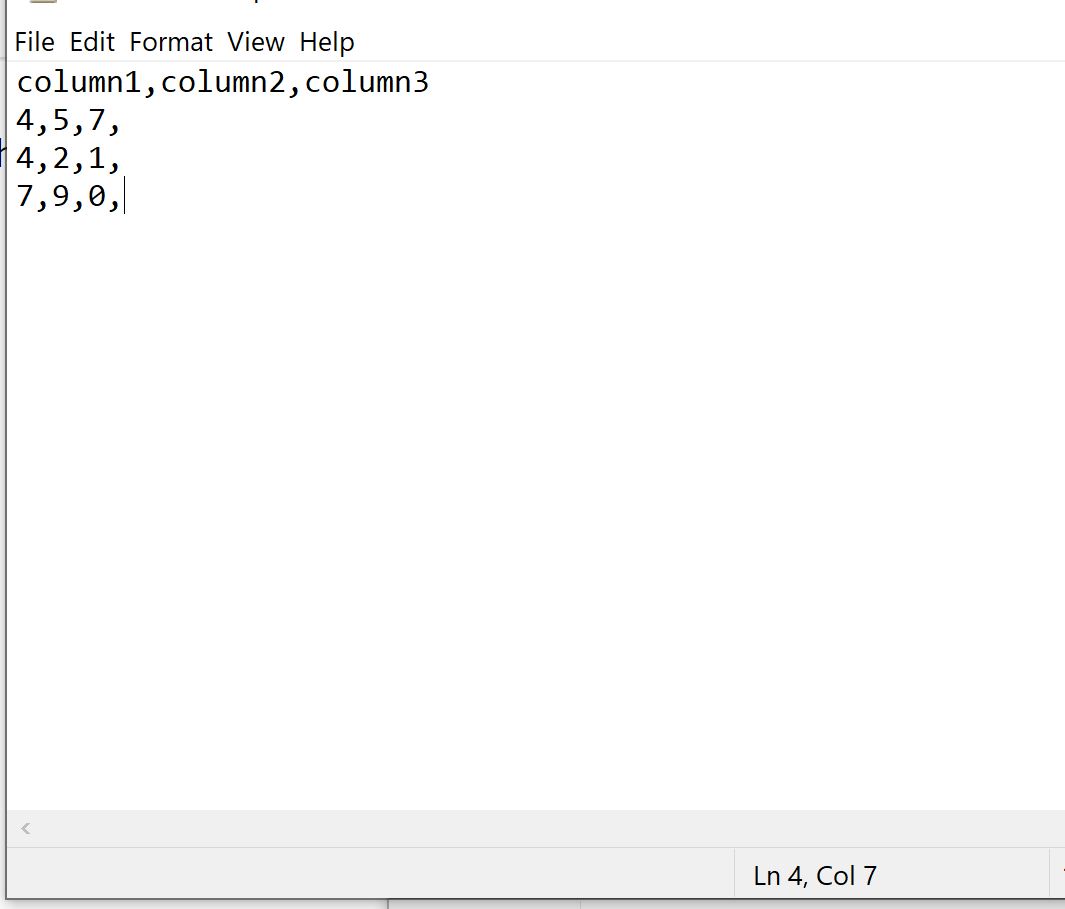
헤더 줄을 제외한 파일의 모든 줄 끝에는 쉼표가 있습니다.
이제 이 파일을 R로 가져오려고 한다고 가정해 보겠습니다.
#attempt to import CSV into data frame
df <- read. csv (' my_data.csv ')
Error in read.table(file = file, header = header, sep = sep, quote = quote, :
duplicate 'row.names' are not allowed
헤더 줄을 제외한 파일의 모든 줄 끝에 쉼표가 있기 때문에 오류가 발생합니다. 이로 인해 R은 값의 첫 번째 열이 줄 이름이라고 생각하게 됩니다.
두 행의 시드 값(4)이 동일하므로 R은 중복된 행 이름이 있다고 생각합니다.
오류를 수정하는 방법
이 오류를 해결하는 방법은 파일을 가져올 때 row.names=NULL을 사용하는 것입니다.
#import CSV file into data frame
df <- read. csv (' my_data.csv ', row.names =NULL)
#view data frame
df
row.names column1 column2 column3
1 4 5 7 NA
2 4 2 1 NA
3 7 9 0 NA
CSV 파일을 성공적으로 가져올 수 있지만 열 이름이 잘못되었습니다.
이 문제를 해결하려면 열 이름을 변경한 다음 마지막 열을 삭제하면 됩니다.
#modify column names
colnames(df) <- colnames(df)[2: ncol (df)]
#drop last column
df <- df[1:( ncol (df)-1)]
#view updated data frame
df
column1 column2 column3
1 4 5 7
2 4 2 1
3 7 9 0
이제 데이터 프레임이 올바른 형식으로 되어 있습니다.
관련 항목: R에서 ncol 함수를 사용하는 방법
추가 리소스
다음 튜토리얼에서는 R의 다른 일반적인 오류를 해결하는 방법을 설명합니다.
R에서 수정하는 방법: 이름이 이전 이름과 일치하지 않습니다.
R에서 수정하는 방법: 긴 물체의 길이가 더 짧은 물체 길이의 배수가 아닙니다.
R에서 수정하는 방법: 대비는 수준이 2개 이상인 요인에만 적용할 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기