R에서 강력한 회귀를 수행하는 방법(단계별)
강력한 회귀는 작업 중인 데이터 세트에 이상치나 영향력 있는 관측치가 있을 때 일반 최소 제곱 회귀의 대안으로 사용할 수 있는 방법입니다.
R에서 강력한 회귀를 수행하려면 다음 구문을 사용하는 MASS 패키지의 rlm() 함수를 사용할 수 있습니다.
다음 단계별 예는 주어진 데이터 세트에 대해 R에서 강력한 회귀를 수행하는 방법을 보여줍니다.
1단계: 데이터 생성
먼저 작업할 가짜 데이터세트를 만들어 보겠습니다.
#create data df <- data. frame (x1=c(1, 3, 3, 4, 4, 6, 6, 8, 9, 3, 11, 16, 16, 18, 19, 20, 23, 23, 24, 25), x2=c(7, 7, 4, 29, 13, 34, 17, 19, 20, 12, 25, 26, 26, 26, 27, 29, 30, 31, 31, 32), y=c(17, 170, 19, 194, 24, 2, 25, 29, 30, 32, 44, 60, 61, 63, 63, 64, 61, 67, 59, 70)) #view first six rows of data head(df) x1 x2 y 1 1 7 17 2 3 7 170 3 3 4 19 4 4 29 194 5 4 13 24 6 6 34 2
2단계: 일반 최소제곱 회귀 수행
다음으로, 일반 최소 제곱 회귀 모델을 피팅하고 표준화된 잔차 의 플롯을 만들어 보겠습니다.
실제로는 절댓값이 3보다 큰 표준화 잔차를 이상값으로 간주하는 경우가 많습니다.
#fit ordinary least squares regression model ols <- lm(y~x1+x2, data=df) #create plot of y-values vs. standardized residuals plot(df$y, rstandard(ols), ylab=' Standardized Residuals ', xlab=' y ') abline(h= 0 )
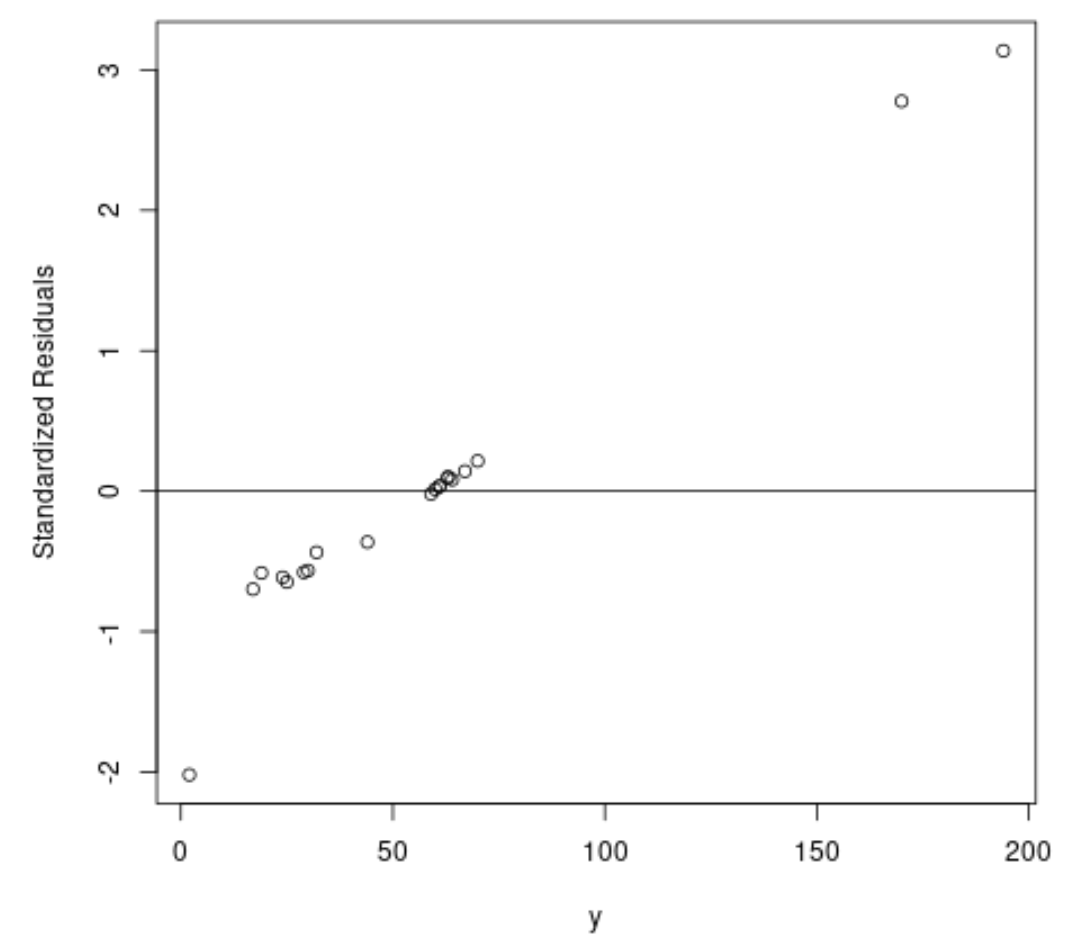
그래프에서 약 3의 표준화된 잔차를 갖는 두 개의 관측치가 있음을 알 수 있습니다.
이는 데이터 세트에 두 가지 잠재적 이상값이 있음을 의미하므로 대신 강력한 회귀 분석을 통해 이점을 얻을 수 있습니다.
3단계: 강력한 회귀 수행
다음으로 rlm() 함수를 사용하여 강력한 회귀 모델을 맞춰보겠습니다.
library (MASS)
#fit robust regression model
robust <- rlm(y~x1+x2, data=df)
이 강력한 회귀 모델이 OLS 모델과 비교하여 데이터에 더 잘 맞는지 여부를 확인하기 위해 각 모델의 잔차 표준 오차를 계산할 수 있습니다.
잔차 표준 오차(RSE)는 회귀 모델에서 잔차의 표준 편차를 측정하는 방법입니다. CSR 값이 낮을수록 모델이 데이터에 더 잘 적합할 수 있습니다.
다음 코드는 각 모델의 RSE를 계산하는 방법을 보여줍니다.
#find residual standard error of ols model summary(ols)$sigma [1] 49.41848 #find residual standard error of ols model summary(robust)$sigma [1] 9.369349
로버스트 회귀 모델의 RSE가 일반 최소 제곱 회귀 모델의 RSE보다 훨씬 낮다는 것을 알 수 있습니다. 이는 로버스트 회귀 모델이 데이터에 더 잘 맞는다는 것을 의미합니다.
추가 리소스
R에서 단순 선형 회귀를 수행하는 방법
R에서 다중 선형 회귀를 수행하는 방법
R에서 다항식 회귀를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기