R에서 다차원 척도를 수행하는 방법(예제 포함)
통계에서 다차원 스케일링은 추상 데카르트 공간(보통 2D 공간)의 데이터 세트에서 관측치의 유사성을 시각화하는 방법입니다.
R에서 다차원 스케일링을 수행하는 가장 쉬운 방법은 다음 기본 구문을 사용하는 내장 cmdscale() 함수를 사용하는 것입니다.
cmdscale(d, eig = FALSE, k = 2, …)
금:
- d : 일반적으로 dist() 함수로 계산되는 거리 행렬.
- eig : 고유값을 반환할지 여부.
- k : 데이터를 볼 차원 수입니다. 기본값은 2 입니다.
다음 예에서는 이 기능을 실제로 사용하는 방법을 보여줍니다.
예: R의 다차원 척도화
다양한 농구 선수에 대한 정보를 포함하는 다음과 같은 데이터 프레임이 R에 있다고 가정합니다.
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
다음 코드를 사용하여 cmdscale() 함수로 다차원 스케일링을 수행하고 결과를 2D 공간에 시각화할 수 있습니다.
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
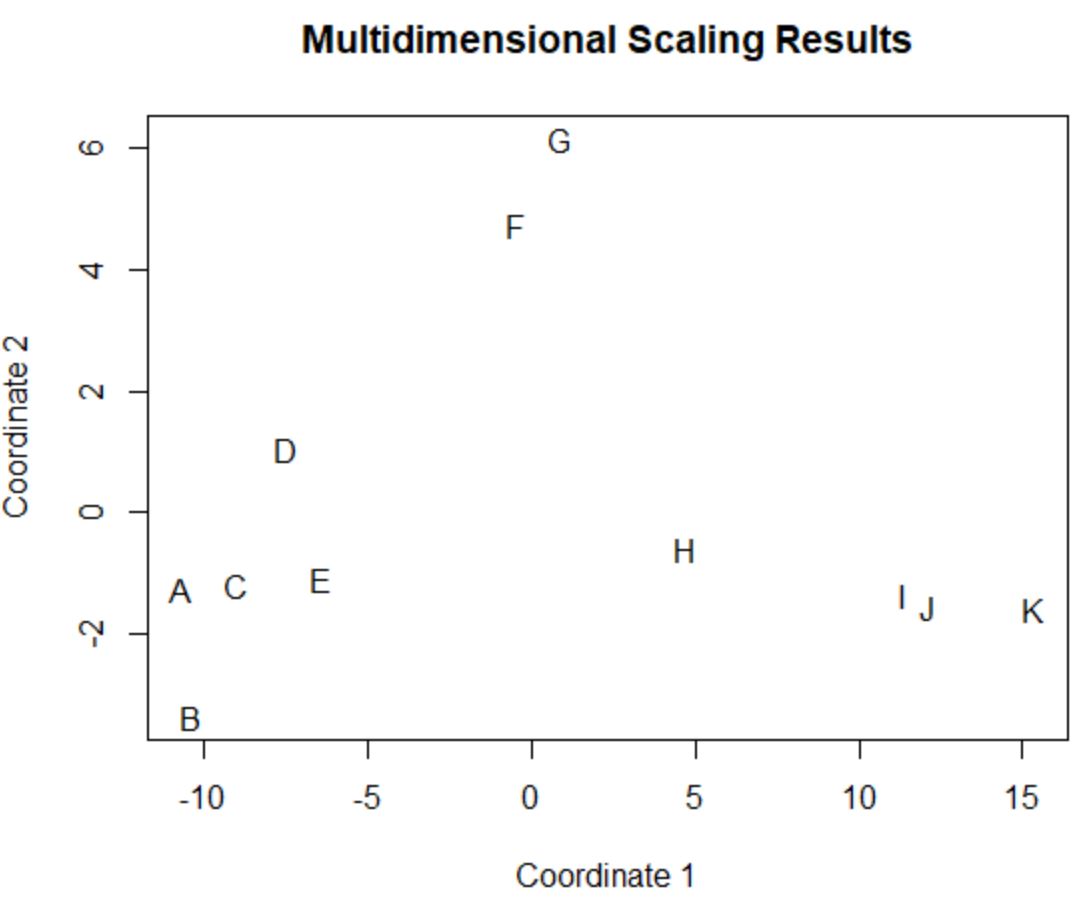
원래 4개의 열(포인트, 어시스트, 블록, 리바운드)에서 비슷한 값을 갖는 원본 데이터 프레임의 플레이어는 플롯에서 서로 가깝습니다.
예를 들어 플레이어 A 와 C 는 서로 가까이 있습니다. 원본 데이터 프레임의 값은 다음과 같습니다.
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
포인트, 어시스트, 블록, 리바운드에 대한 값은 모두 매우 유사하므로 2D 플롯에서 서로 너무 가까운 이유를 설명합니다.
대조적으로, 플롯에서 멀리 떨어져 있는 플레이어 B 와 K 를 생각해 보십시오.
원본 데이터의 값을 참조하면 상당히 다르다는 것을 알 수 있습니다.
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
따라서 2D 플롯은 데이터 프레임의 모든 변수에서 각 플레이어가 얼마나 유사한지 시각화하는 좋은 방법입니다.
비슷한 통계를 가진 플레이어는 서로 가깝게 그룹화되어 있지만 통계가 매우 다른 플레이어는 플롯에서 서로 멀리 떨어져 있습니다.
cmdscale() 함수의 결과를 저장한 변수의 이름인 fit 을 입력하여 플롯에서 각 플레이어의 정확한 좌표(x, y)를 추출할 수도 있습니다.
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
추가 리소스
다음 튜토리얼에서는 R에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기