R에서 레버리지 통계를 계산하는 방법
통계에서는 응답 변수의 값이 데이터 세트의 나머지 관측치보다 훨씬 큰 경우 관측치 를 이상 값으로 간주합니다.
마찬가지로, 데이터 세트의 나머지 관측치에 비해 훨씬 더 극단적인 예측 변수에 대한 값이 하나 이상 있으면 관측치가 높은 레버리지 로 간주됩니다.
모든 유형의 분석에서 첫 번째 단계 중 하나는 주어진 모델의 결과에 큰 영향을 미칠 수 있으므로 활용도가 높은 관측치를 자세히 살펴보는 것입니다.
이 튜토리얼에서는 R 모델의 각 관찰에 대한 레버리지를 계산하고 시각화하는 방법에 대한 단계별 예를 보여줍니다.
1단계: 회귀 모델 만들기
먼저 R에 내장된 mtcars 데이터 세트를 사용하여 다중 선형 회귀 모델을 만듭니다.
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2nd-16 *** available -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
2단계: 각 관찰에 대한 레버리지 계산
다음으로, hatvalues() 함수를 사용하여 모델의 각 관측값에 대한 레버리지를 계산합니다.
#calculate leverage for each observation in the model hats <- as . data . frame (hatvalues(model)) #display leverage stats for each observation hats hatvalues(model) Mazda RX4 0.04235795 Mazda RX4 Wag 0.04235795 Datsun 710 0.06287776 Hornet 4 Drive 0.07614472 Hornet Sportabout 0.08097817 Valiant 0.05945972 Duster 360 0.09828955 Merc 240D 0.08816960 Merc 230 0.05102253 Merc 280 0.03990060 Merc 280C 0.03990060 Merc 450SE 0.03890159 Merc 450SL 0.03890159 Merc 450SLC 0.03890159 Cadillac Fleetwood 0.19443875 Lincoln Continental 0.16042361 Chrysler Imperial 0.12447530 Fiat 128 0.08346304 Honda Civic 0.09493784 Toyota Corolla 0.08732818 Toyota Corona 0.05697867 Dodge Challenger 0.06954069 AMC Javelin 0.05767659 Camaro Z28 0.10011654 Pontiac Firebird 0.12979822 Fiat X1-9 0.08334018 Porsche 914-2 0.05785170 Lotus Europa 0.08193899 Ford Pantera L 0.13831817 Ferrari Dino 0.12608583 Maserati Bora 0.49663919 Volvo 142E 0.05848459
일반적으로 우리는 레버리지 값이 2보다 큰 관측치를 자세히 살펴봅니다.
이를 수행하는 간단한 방법은 레버리지 값을 기준으로 관측치를 내림차순으로 정렬하는 것입니다.
#sort observations by leverage, descending hats[ order (-hats[' hatvalues(model) ']), ] [1] 0.49663919 0.19443875 0.16042361 0.13831817 0.12979822 0.12608583 [7] 0.12447530 0.10011654 0.09828955 0.09493784 0.08816960 0.08732818 [13] 0.08346304 0.08334018 0.08193899 0.08097817 0.07614472 0.06954069 [19] 0.06287776 0.05945972 0.05848459 0.05785170 0.05767659 0.05697867 [25] 0.05102253 0.04235795 0.04235795 0.03990060 0.03990060 0.03890159 [31] 0.03890159 0.03890159
가장 높은 레버리지 값은 0.4966 임을 알 수 있습니다. 이 숫자는 2보다 크지 않기 때문에 데이터세트의 어떤 관측치도 높은 활용도를 갖지 않는다는 것을 알 수 있습니다.
3단계: 각 관찰에 대한 활용 시각화
마지막으로 각 관찰에 대한 활용을 시각화하는 빠른 차트를 만들 수 있습니다.
#plot leverage values for each observation plot(hatvalues(model), type = ' h ')
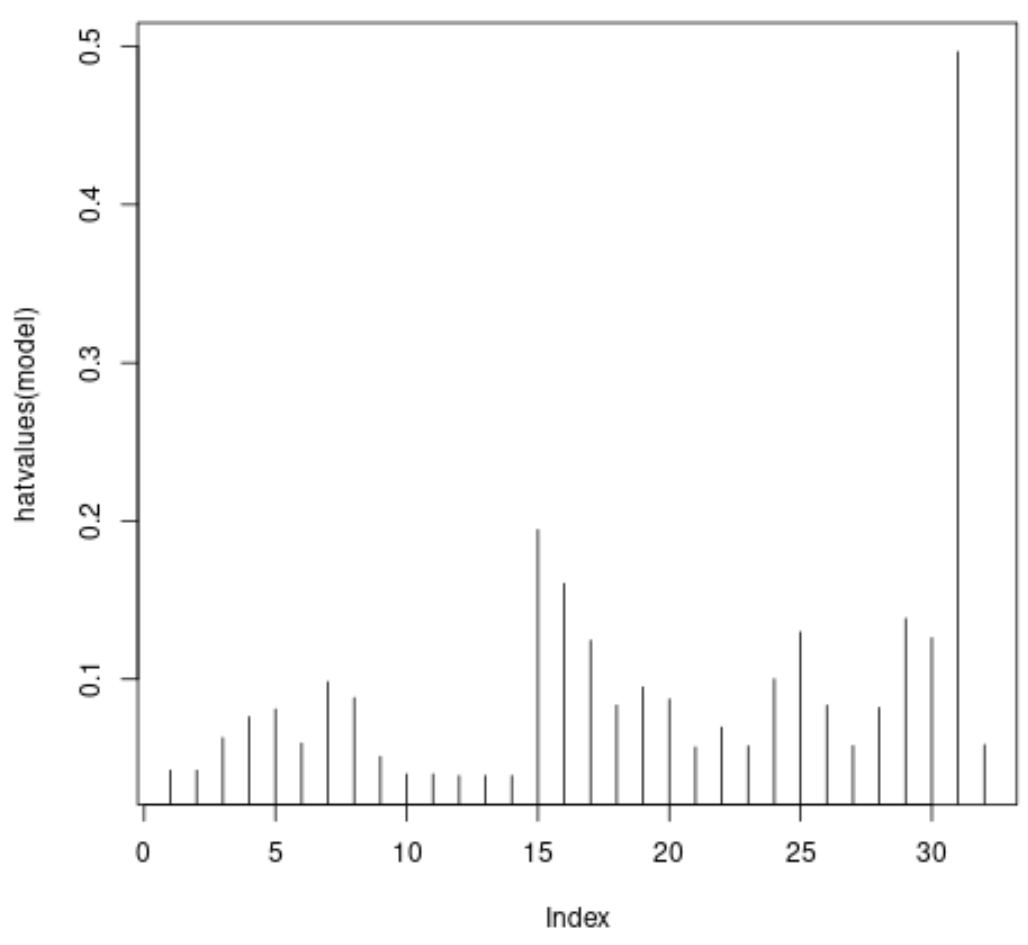
x축은 데이터 세트의 각 관측치 인덱스를 표시하고 y값은 각 관측치에 대한 해당 레버리지 통계를 표시합니다.
추가 리소스
R에서 단순 선형 회귀를 수행하는 방법
R에서 다중 선형 회귀를 수행하는 방법
R에서 잔차 플롯을 만드는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기