R에서 랜덤 포레스트를 생성하는 방법(단계별)
일련의 예측 변수와 반응 변수 사이의 관계가 매우 복잡한 경우, 우리는 종종 비선형 방법을 사용하여 이들 사이의 관계를 모델링합니다.
그러한 방법 중 하나는 의사결정 트리를 구축하는 것입니다. 그러나 단일 의사결정 트리를 사용할 때의 단점은 높은 분산 으로 인해 어려움을 겪는 경향이 있다는 것입니다.
즉, 데이터세트를 두 부분으로 나누고 의사결정 트리를 두 부분 모두에 적용하면 결과가 매우 다를 수 있습니다.
단일 의사결정 트리의 분산을 줄이기 위해 사용할 수 있는 한 가지 방법은 다음과 같이 작동하는 랜덤 포레스트 모델을 구축하는 것입니다.
1. 원본 데이터 세트에서 b 부트스트랩 샘플을 가져옵니다.
2. 각 부트스트랩 샘플에 대한 의사결정 트리를 만듭니다.
- 트리를 구성할 때 분할이 고려될 때마다 m 예측 변수의 무작위 샘플만 p 예측 변수의 전체 집합에서 분할할 후보로 간주됩니다. 일반적으로 우리는 √p 와 동일한 m을 선택합니다.
3. 각 트리의 예측을 평균하여 최종 모델을 얻습니다.
랜덤 포레스트는 단일 의사결정 트리나 배깅 모델 보다 훨씬 더 정확한 모델을 생성하는 경향이 있는 것으로 나타났습니다.
이 튜토리얼에서는 R에서 데이터 세트에 대한 Random Forest 모델을 생성하는 방법에 대한 단계별 예를 제공합니다.
1단계: 필요한 패키지 로드
먼저 이 예제에 필요한 패키지를 로드하겠습니다. 이 간단한 예에서는 하나의 패키지만 필요합니다.
library (randomForest)
2단계: 랜덤 포레스트 모델 조정
이 예에서는 개별적으로 153일 동안 뉴욕시의 대기 질 측정값을 포함하는 Air Quality 라는 기본 제공 R 데이터 세트를 사용합니다.
#view structure of air quality dataset str(airquality) 'data.frame': 153 obs. of 6 variables: $ Ozone: int 41 36 12 18 NA 28 23 19 8 NA ... $Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ... $ Wind: num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ... $ Temp: int 67 72 74 62 56 66 65 59 61 69 ... $Month: int 5 5 5 5 5 5 5 5 5 5 ... $Day: int 1 2 3 4 5 6 7 8 9 10 ... #find number of rows with missing values sum(! complete . cases (airquality)) [1] 42
이 데이터 세트에는 누락된 값이 있는 42개의 행이 있습니다. 따라서 랜덤 포레스트 모델을 피팅하기 전에 각 열의 누락된 값을 열 중앙값으로 채울 것입니다.
#replace NAs with column medians for (i in 1: ncol (air quality)) { airquality[,i][ is . na (airquality[, i])] <- median (airquality[, i], na . rm = TRUE ) }
관련 항목: R에서 누락된 값을 대치하는 방법
다음 코드는 RandomForest 패키지의 RandomForest() 함수를 사용하여 R에서 Random Forest 모델을 맞추는 방법을 보여줍니다.
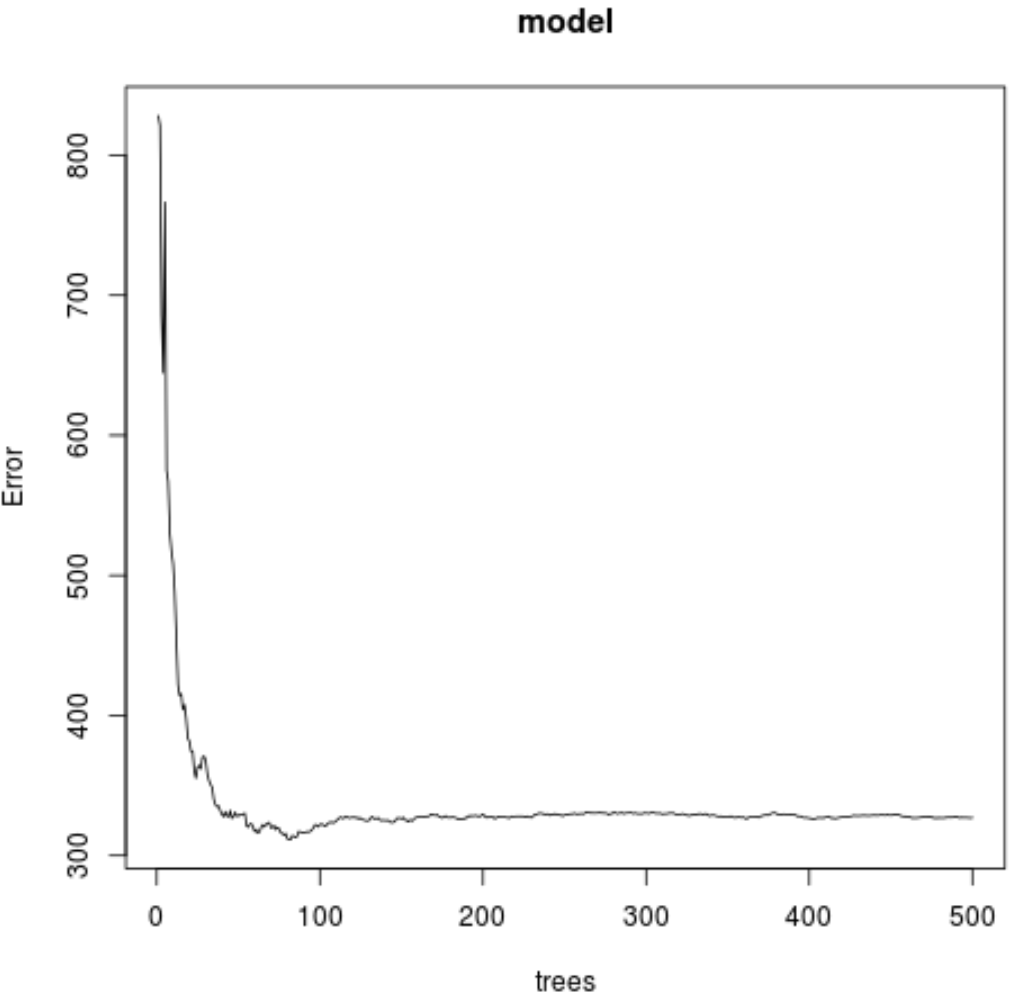
#make this example reproducible set.seed(1) #fit the random forest model model <- randomForest( formula = Ozone ~ ., data = airquality ) #display fitted model model Call: randomForest(formula = Ozone ~ ., data = airquality) Type of random forest: regression Number of trees: 500 No. of variables tried at each split: 1 Mean of squared residuals: 327.0914 % Var explained: 61 #find number of trees that produce lowest test MSE which.min(model$mse) [1] 82 #find RMSE of best model sqrt(model$mse[ which . min (model$mse)]) [1] 17.64392
결과에서 가장 낮은 테스트 평균 제곱 오차(MSE)를 생성한 모델이 82개의 트리를 사용했음을 알 수 있습니다.
또한 이 모델의 제곱 평균 제곱근 오차가 17.64392 임을 알 수 있습니다. 이것을 오존 예측값과 실제 관측값의 평균 차이라고 생각할 수 있습니다.
다음 코드를 사용하여 사용된 트리 수를 기반으로 MSE 테스트 플롯을 생성할 수도 있습니다.
#plot the MSE test by number of trees
plot(model)
그리고 varImpPlot() 함수를 사용하여 최종 모델에서 각 예측 변수의 중요성을 표시하는 플롯을 만들 수 있습니다.
#produce variable importance plot
varImpPlot(model)
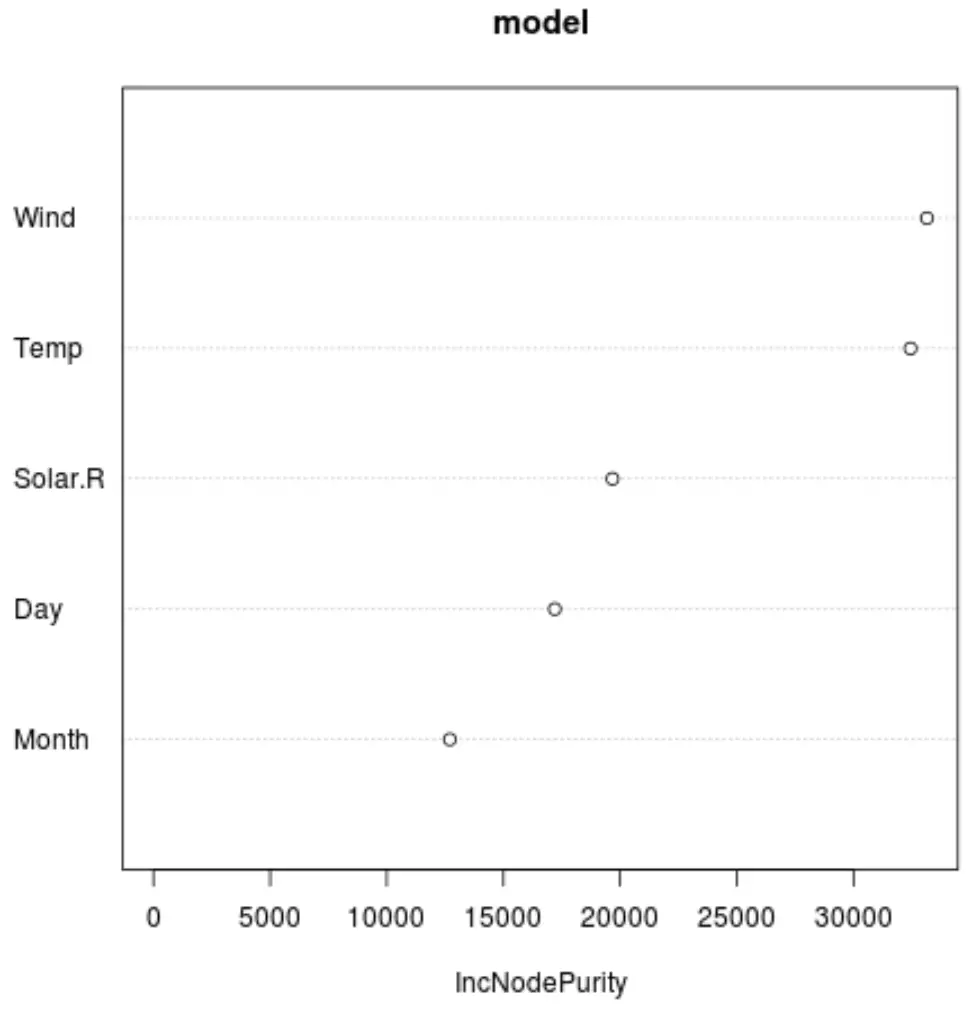
x축은 y축에 표시된 다양한 예측 변수에 대한 분할 함수로 회귀 트리 노드 순도의 평균 증가를 표시합니다.
그래프를 보면 바람이 가장 중요한 예측 변수이고 그 다음이 온도 라는 것을 알 수 있습니다.
3단계: 모델 조정
기본적으로 RandomForest() 함수는 500개의 트리와 (총 예측 변수/3) 무작위로 선택된 예측 변수를 각 분할의 잠재적 후보로 사용합니다. tuneRF() 함수를 사용하여 이러한 매개변수를 조정할 수 있습니다.
다음 코드는 다음 사양을 사용하여 최적의 모델을 찾는 방법을 보여줍니다.
- ntreeTry: 구축할 트리 수입니다.
- mtryStart: 각 분할에서 고려할 예측 변수의 초기 수입니다.
- stepFactor: 예상되는 Out-of-bag 오류가 특정 양만큼 개선되지 않을 때까지 증가하는 요소입니다.
- 개선: 단계 계수를 계속 증가시키기 위해 백 종료 오류를 개선해야 하는 양입니다.
model_tuned <- tuneRF(
x=airquality[,-1], #define predictor variables
y=airquality$Ozone, #define response variable
ntreeTry= 500 ,
mtryStart= 4 ,
stepFactor= 1.5 ,
improve= 0.01 ,
trace= FALSE #don't show real-time progress
)
이 함수는 x축에 트리를 구성할 때 각 분할에 사용된 예측 변수의 수를 표시하고 y축에 예상 Out-of-bag 오류를 표시하는 다음 플롯을 생성합니다.
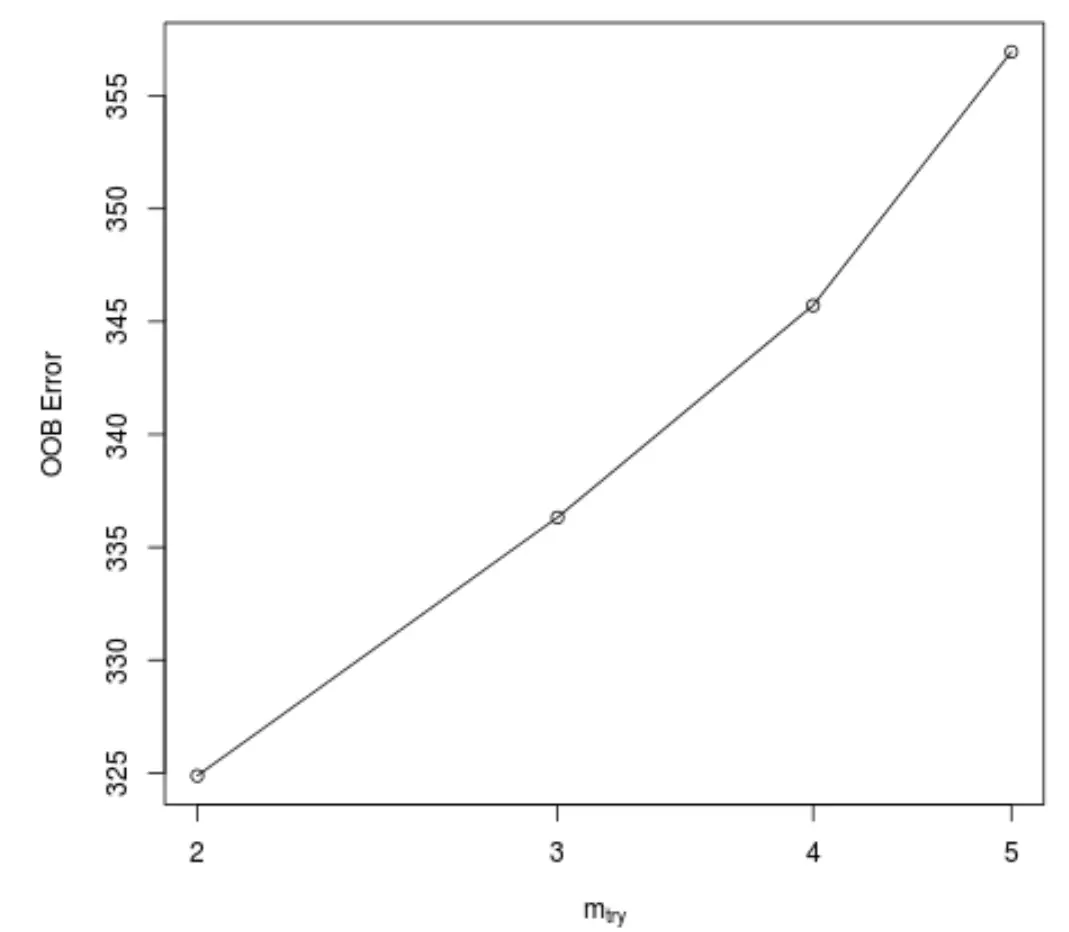
트리를 작성할 때 각 분할에서 무작위로 선택된 2개의 예측 변수를 사용하면 가장 낮은 OOB 오류가 얻어지는 것을 볼 수 있습니다.
이는 실제로 초기 RandomForest() 함수에서 사용된 기본 설정(총 예측자/3 = 6/3 = 2)에 해당합니다.
4단계: 최종 모델을 사용하여 예측
마지막으로, 조정된 랜덤 포레스트 모델을 사용하여 새로운 관측값에 대한 예측을 할 수 있습니다.
#define new observation new <- data.frame(Solar.R=150, Wind=8, Temp=70, Month=5, Day=5) #use fitted bagged model to predict Ozone value of new observation predict(model, newdata=new) 27.19442
예측 변수의 값을 기반으로 피팅된 랜덤 포레스트 모델은 특정 날짜의 오존 값이 27.19442 가 될 것이라고 예측합니다.
이 예제에 사용된 전체 R 코드는 여기에서 찾을 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기