R에 분류 및 회귀 트리를 맞추는 방법
일련의 예측 변수와 반응 변수 간의 관계가 선형인 경우 다중 선형 회귀 와 같은 방법을 사용하면 정확한 예측 모델을 생성할 수 있습니다.
그러나 일련의 예측 변수와 반응 간의 관계가 더 복잡하면 비선형 방법을 사용하여 더 정확한 모델을 생성할 수 있는 경우가 많습니다.
그러한 방법 중 하나는 분류 및 회귀 트리 (CART)로, 예측 변수 세트를 사용하여 응답 변수의 값을 예측하는 의사결정 트리를 생성합니다.
반응 변수가 연속형이면 회귀 트리를 만들 수 있고, 반응 변수가 범주형이면 분류 트리를 만들 수 있습니다.
이 튜토리얼에서는 R에서 회귀 및 분류 트리를 만드는 방법을 설명합니다.
예제 1: R에서 회귀 트리 구축
이 예에서는 263명의 프로 야구 선수에 대한 다양한 정보가 포함된 ISLR 패키지의 Hitters 데이터 세트를 사용합니다.
우리는 이 데이터 세트를 사용하여 특정 선수의 연봉을 예측하기 위해 홈런 과 플레이 기간 의 예측 변수를 사용하는 회귀 트리를 구축할 것입니다.
이 회귀 트리를 만들려면 다음 단계를 따르세요.
1단계: 필요한 패키지를 로드합니다.
먼저 이 예제에 필요한 패키지를 로드합니다.
library (ISLR) #contains Hitters dataset library (rpart) #for fitting decision trees library (rpart.plot) #for plotting decision trees
2단계: 초기 회귀 트리를 구축합니다.
먼저 대규모 초기 회귀 트리를 구축합니다. “복잡성 매개변수”를 의미하는 cp 에 작은 값을 사용하여 트리가 크다는 것을 보장할 수 있습니다.
이는 모델의 전체 R-제곱이 최소한 cp로 지정된 값만큼 증가하는 한 회귀 트리에서 추가 분할을 수행한다는 것을 의미합니다.
그런 다음 printcp() 함수를 사용하여 모델 결과를 인쇄합니다.
#build the initial tree
tree <- rpart(Salary ~ Years + HmRun, data=Hitters, control=rpart. control (cp= .0001 ))
#view results
printcp(tree)
Variables actually used in tree construction:
[1] HmRun Years
Root node error: 53319113/263 = 202734
n=263 (59 observations deleted due to missingness)
CP nsplit rel error xerror xstd
1 0.24674996 0 1.00000 1.00756 0.13890
2 0.10806932 1 0.75325 0.76438 0.12828
3 0.01865610 2 0.64518 0.70295 0.12769
4 0.01761100 3 0.62652 0.70339 0.12337
5 0.01747617 4 0.60891 0.70339 0.12337
6 0.01038188 5 0.59144 0.66629 0.11817
7 0.01038065 6 0.58106 0.65697 0.11687
8 0.00731045 8 0.56029 0.67177 0.11913
9 0.00714883 9 0.55298 0.67881 0.11960
10 0.00708618 10 0.54583 0.68034 0.11988
11 0.00516285 12 0.53166 0.68427 0.11997
12 0.00445345 13 0.52650 0.68994 0.11996
13 0.00406069 14 0.52205 0.68988 0.11940
14 0.00264728 15 0.51799 0.68874 0.11916
15 0.00196586 16 0.51534 0.68638 0.12043
16 0.00016686 17 0.51337 0.67577 0.11635
17 0.00010000 18 0.51321 0.67576 0.11615
n=263 (59 observations deleted due to missingness)
3단계: 나무를 가지치기합니다.
다음으로, 가장 낮은 테스트 오류로 이어지는 cp(복잡도 매개변수)에 사용할 최적의 값을 찾기 위해 회귀 트리를 정리합니다.
cp의 최적 값은 이전 출력에서 가장 낮은 x 오류 로 이어지는 값이며, 이는 교차 검증 데이터의 관측값에 대한 오류를 나타냅니다.
#identify best cp value to use
best <- tree$cptable[which. min (tree$cptable[," xerror "])," CP "]
#produce a pruned tree based on the best cp value
pruned_tree <- prune (tree, cp=best)
#plot the pruned tree
prp(pruned_tree,
faclen= 0 , #use full names for factor labels
extra= 1 , #display number of obs. for each terminal node
roundint= F , #don't round to integers in output
digits= 5 ) #display 5 decimal places in output

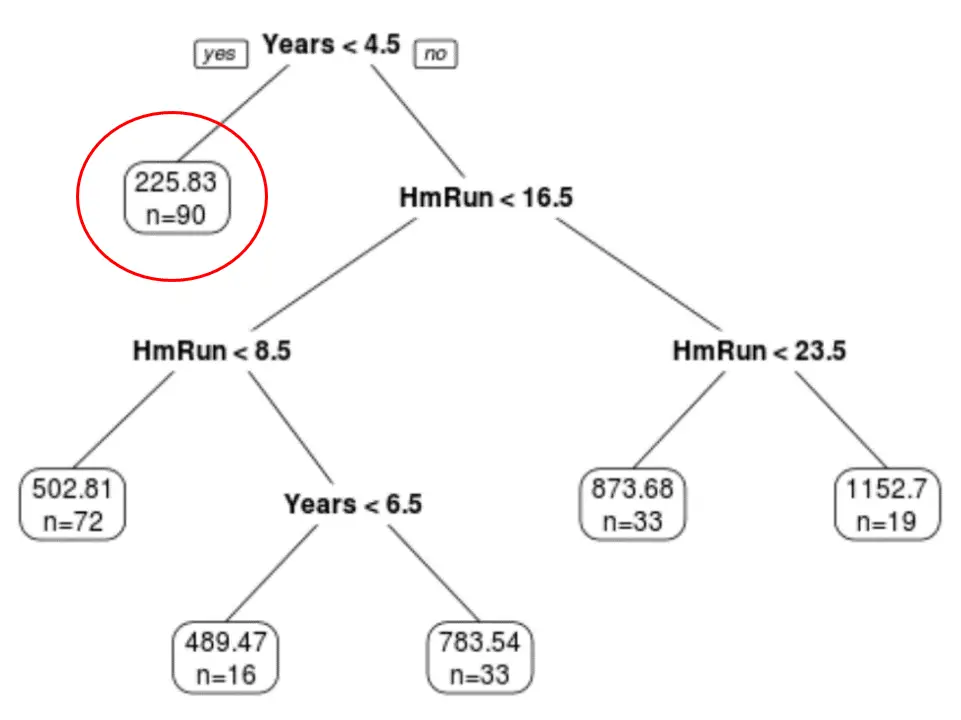
최종 가지치기 트리에는 6개의 터미널 노드가 있음을 알 수 있습니다. 각 리프 노드에는 해당 노드에 있는 플레이어의 예상 급여와 해당 등급에 속하는 원래 데이터 세트의 관측치 수가 표시됩니다.
예를 들어, 원본 데이터세트에는 경력이 4.5년 미만인 선수가 90명 있고 평균 연봉이 $225.83K임을 알 수 있습니다.
4단계: 트리를 사용하여 예측합니다.
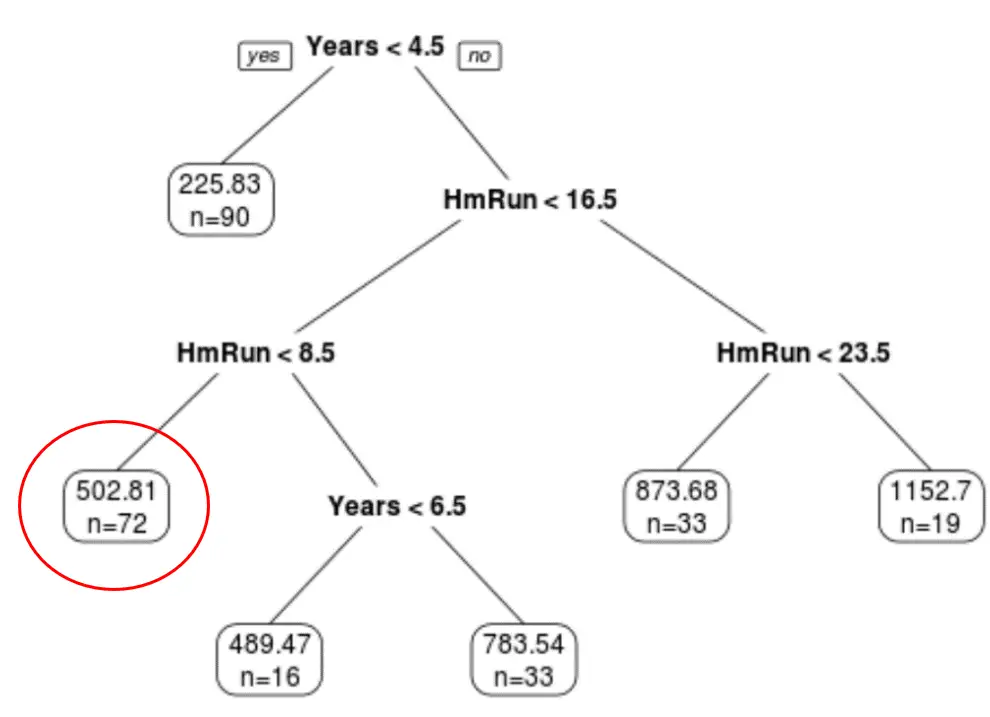
우리는 최종 가지치기 트리를 사용하여 특정 선수의 수년간의 경험과 평균 홈런을 기반으로 해당 선수의 급여를 예측할 수 있습니다.
예를 들어, 경력 7년, 평균 4홈런을 보유한 선수의 예상 연봉은 $502.81k 입니다.
이를 확인하기 위해 R의 예측() 함수를 사용할 수 있습니다.
#define new player
new <- data.frame(Years=7, HmRun=4)
#use pruned tree to predict salary of this player
predict(pruned_tree, newdata=new)
502.8079
예시 2: R에서 분류 트리 구축
이 예에서는 타이타닉에 탑승한 승객에 대한 다양한 정보가 포함된 rpart.plot 패키지의 ptitanic 데이터 세트를 사용합니다.
우리는 이 데이터 세트를 사용하여 특정 승객의 생존 여부를 예측하기 위해 예측 변수 class , 성별 및 연령을 사용하는 분류 트리를 만듭니다.
이 분류 트리를 만들려면 다음 단계를 따르세요.
1단계: 필요한 패키지를 로드합니다.
먼저 이 예제에 필요한 패키지를 로드합니다.
library (rpart) #for fitting decision trees library (rpart.plot) #for plotting decision trees
2단계: 초기 분류 트리를 구축합니다.
먼저 대규모 초기 분류 트리를 구축합니다. “복잡성 매개변수”를 의미하는 cp 에 작은 값을 사용하여 트리가 크다는 것을 보장할 수 있습니다.
이는 전체 모델 적합도가 최소한 cp로 지정된 값만큼 증가하는 한 분류 트리에서 추가 분할을 수행한다는 의미입니다.
그런 다음 printcp() 함수를 사용하여 모델 결과를 인쇄합니다.
#build the initial tree
tree <- rpart(survived~pclass+sex+age, data=ptitanic, control=rpart. control (cp= .0001 ))
#view results
printcp(tree)
Variables actually used in tree construction:
[1] age pclass sex
Root node error: 500/1309 = 0.38197
n=1309
CP nsplit rel error xerror xstd
1 0.4240 0 1.000 1.000 0.035158
2 0.0140 1 0.576 0.576 0.029976
3 0.0095 3 0.548 0.578 0.030013
4 0.0070 7 0.510 0.552 0.029517
5 0.0050 9 0.496 0.528 0.029035
6 0.0025 11 0.486 0.532 0.029117
7 0.0020 19 0.464 0.536 0.029198
8 0.0001 22 0.458 0.528 0.029035
3단계: 나무를 가지치기합니다.
다음으로, 가장 낮은 테스트 오류로 이어지는 cp(복잡도 매개변수)에 사용할 최적의 값을 찾기 위해 회귀 트리를 정리합니다.
cp의 최적 값은 이전 출력에서 가장 낮은 x 오류 로 이어지는 값이며, 이는 교차 검증 데이터의 관측값에 대한 오류를 나타냅니다.
#identify best cp value to use
best <- tree$cptable[which. min (tree$cptable[," xerror "])," CP "]
#produce a pruned tree based on the best cp value
pruned_tree <- prune (tree, cp=best)
#plot the pruned tree
prp(pruned_tree,
faclen= 0 , #use full names for factor labels
extra= 1 , #display number of obs. for each terminal node
roundint= F , #don't round to integers in output
digits= 5 ) #display 5 decimal places in output
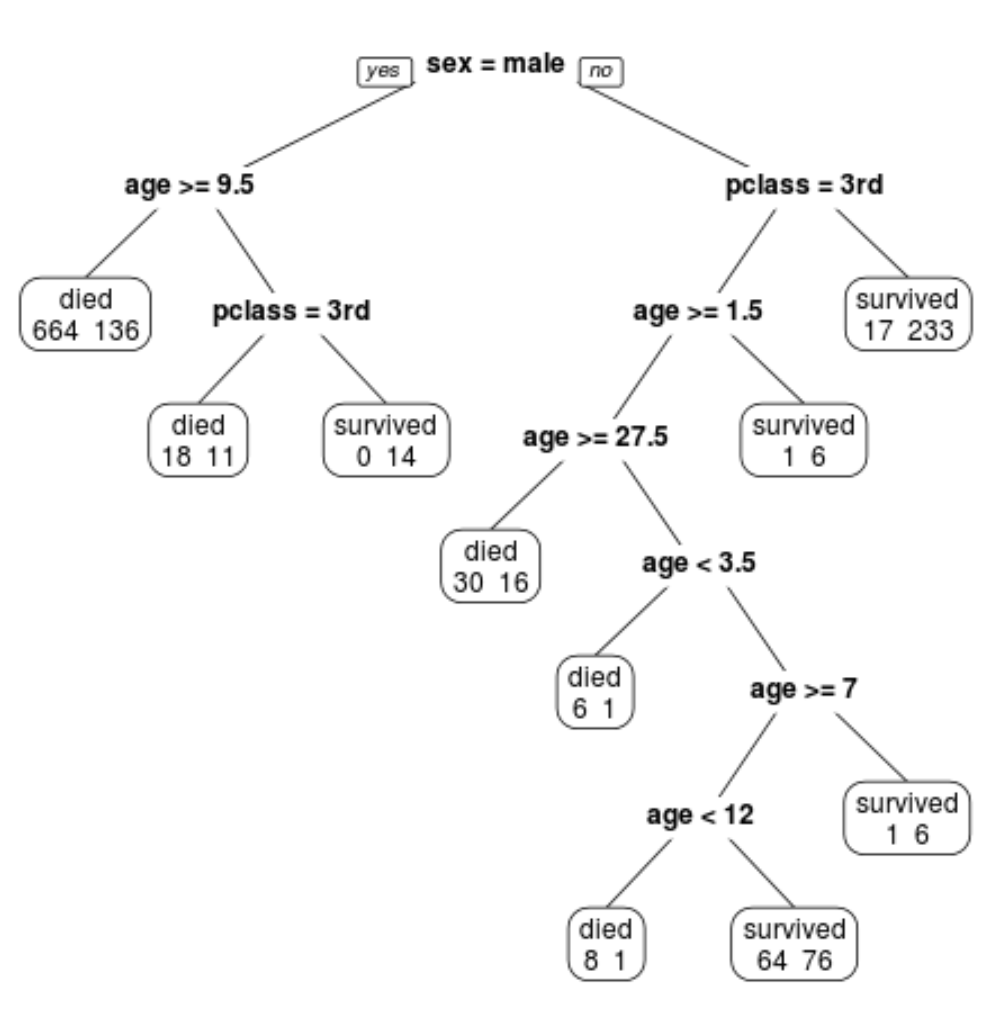
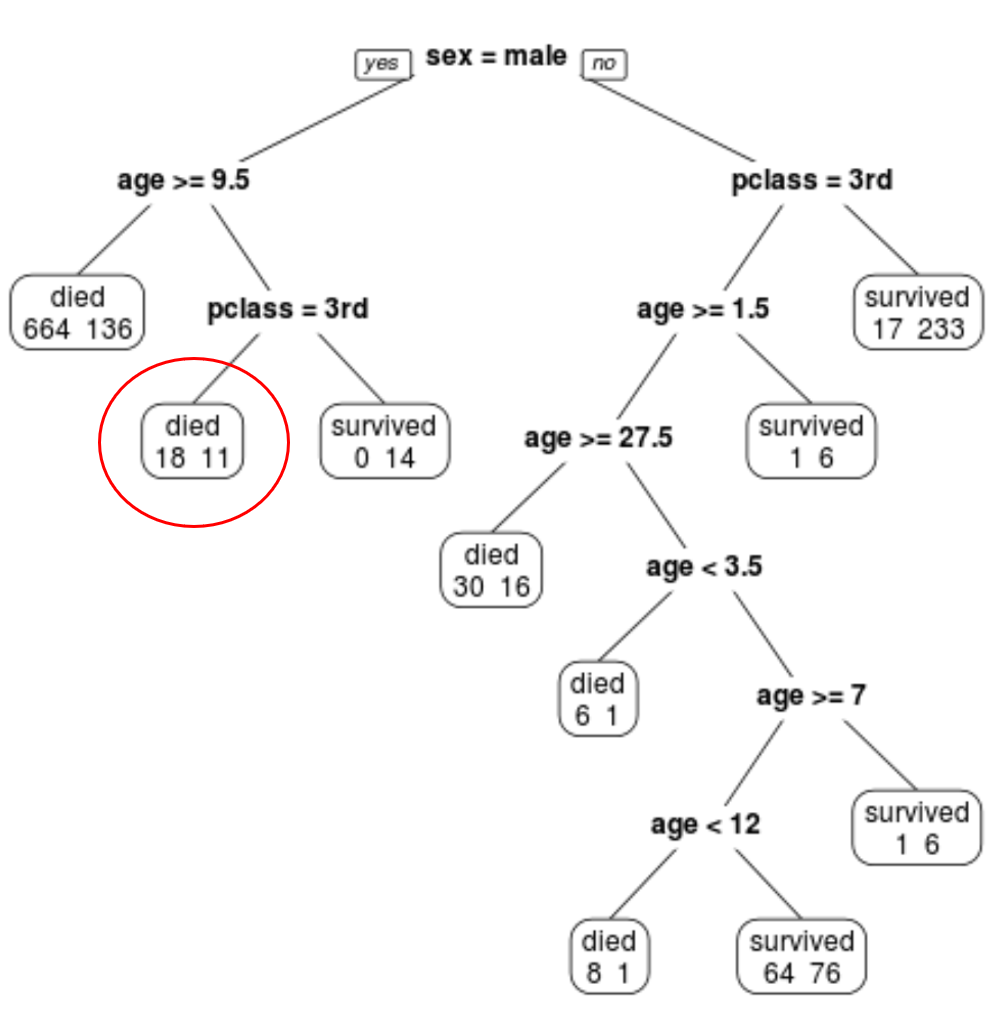
최종 가지치기 트리에는 10개의 터미널 노드가 있음을 알 수 있습니다. 각 터미널 노드에는 사망한 승객 수와 생존자 수가 표시됩니다.
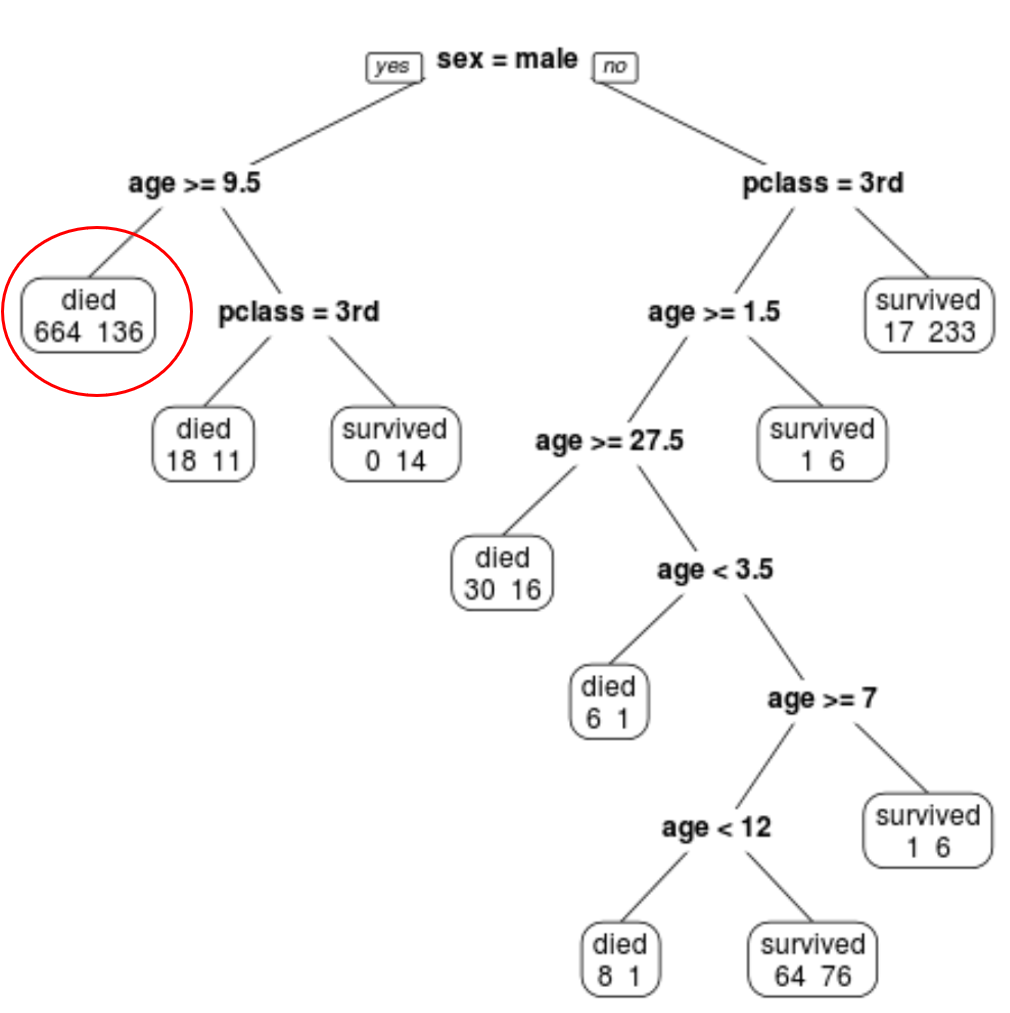
예를 들어, 가장 왼쪽 노드에서는 664명의 승객이 사망하고 136명이 살아남은 것을 볼 수 있습니다.
4단계: 트리를 사용하여 예측합니다.
최종 가지치기 트리를 사용하여 클래스, 연령, 성별을 기준으로 특정 승객의 생존 확률을 예측할 수 있습니다.
예를 들어 8세의 1등석 남성 승객의 생존 확률은 11/29 = 37.9%입니다.
여기 에서 이러한 예제에 사용된 전체 R 코드를 찾을 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기