R에서 교차 상관을 계산하는 방법
상호상관은 시계열과 다른 시계열의 지연 버전 간의 유사성 정도를 측정하는 방법입니다.
이러한 유형의 상관 관계는 한 시계열의 값이 다른 시계열의 미래 값을 예측하는지 여부를 알려줄 수 있으므로 계산에 유용합니다. 즉, 하나의 시계열이 다른 시계열의 선행 지표인지 여부를 알려줄 수 있습니다.
이러한 유형의 상관 관계는 다음을 포함하여 다양한 분야에서 사용됩니다.
경제: 소비자 신뢰 지수(CCI)는 국가의 국내총생산(GDP)을 나타내는 주요 지표로 간주됩니다. 예를 들어, 특정 달에 CCI가 높다면, GDP는 x 개월 후에 더 높아질 가능성이 높습니다.
기업: 마케팅 지출은 종종 미래 비즈니스 수익의 주요 지표로 간주됩니다. 예를 들어, 회사가 한 분기에 마케팅에 비정상적으로 많은 돈을 지출했다면 총 수익은 x 분기 이후에 높아야 합니다.
생물학: 총 해양 오염은 특정 거북이 종의 개체수를 나타내는 주요 지표로 간주됩니다. 예를 들어, 특정 연도에 오염이 더 높으면 전체 거북이 개체수는 x 년 후에 감소할 것으로 예상됩니다.
다음 예는 R에서 두 시계열 간의 상호 상관을 계산하는 방법을 보여줍니다.
예: R에서 상호 상관을 계산하는 방법
특정 회사의 총 마케팅 지출(천 단위)과 12개월 연속 총 수익(천 단위)을 보여주는 다음과 같은 시계열이 R에 있다고 가정합니다.
#define data
marketing <- c(3, 4, 5, 5, 7, 9, 13, 15, 12, 10, 8, 8)
revenue <- c(21, 19, 22, 24, 25, 29, 30, 34, 37, 40, 35, 30)
다음과 같이 ccf() 함수를 사용하여 두 시계열 간의 각 시차에 대한 상호 상관을 계산할 수 있습니다.
#calculate cross correlation
ccf(marketing, revenue)
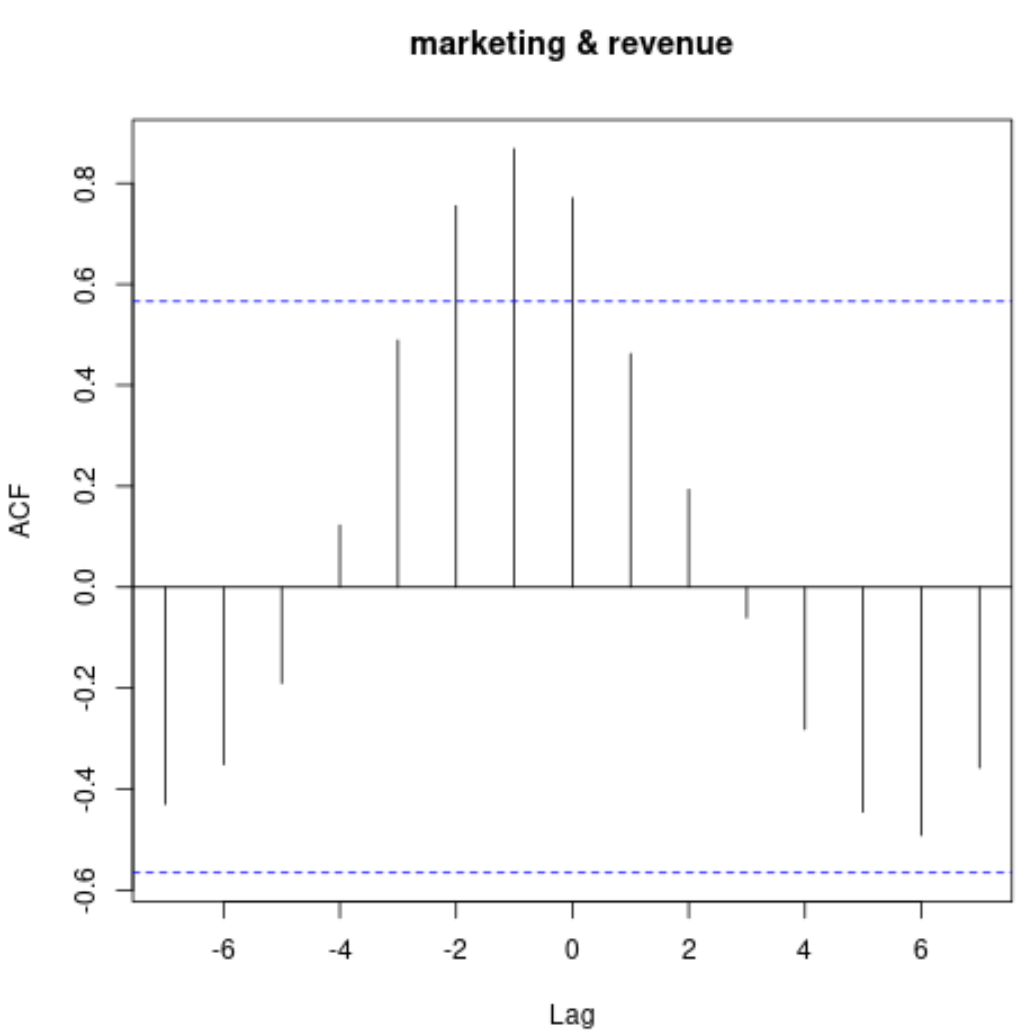
이 차트는 서로 다른 시차에서 두 시계열 간의 상관 관계를 표시합니다.
실제 상관관계 값을 표시하려면 다음 구문을 사용할 수 있습니다.
#display cross correlation values print (ccf(marketing, revenue)) Autocorrelations of series 'X', by lag -7 -6 -5 -4 -3 -2 -1 0 1 2 3 -0.430 -0.351 -0.190 0.123 0.489 0.755 0.868 0.771 0.462 0.194 -0.061 4 5 6 7 -0.282 -0.445 -0.492 -0.358
이 출력을 해석하는 방법은 다음과 같습니다.
- 시차 0에서의 상호 상관은 0.771 입니다.
- 시차 1에서의 상호 상관은 0.462 입니다.
- 시차 2에서의 상호 상관은 0.194 입니다.
- 시차 3에서의 상호 상관은 -0.061 입니다.
등등.
두 시계열 사이의 상관관계는 -2 대 2의 시차로 매우 긍정적입니다. 이는 특정 달의 마케팅 지출이 1개월 및 2개월 후의 수익을 상당히 예측한다는 것을 의미합니다.
이는 직관적으로 이해됩니다. 특정 달의 높은 마케팅 지출이 향후 2개월 동안 수익 증가를 예측할 것으로 예상합니다.
추가 리소스
R에서 자기상관을 계산하는 방법
R에서 부분 상관 관계를 계산하는 방법
R에서 슬라이딩 상관관계를 계산하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기