R에서 정규성을 테스트하는 방법(4가지 방법)
많은 통계 테스트에서는 데이터 세트가 정규 분포를 따른다고 가정합니다 .
R에는 이 가정을 확인하는 네 가지 일반적인 방법이 있습니다.
1. (시각적 방법) 히스토그램을 생성합니다.
- 히스토그램이 대략 “종” 모양이면 데이터가 정규 분포를 따르는 것으로 간주됩니다.
2. (시각적 방법) QQ 플롯을 생성합니다.
- 그림의 점이 대략 직선 대각선을 따라 있으면 데이터가 정규 분포를 따르는 것으로 간주됩니다.
3. (정식 통계 검정) Shapiro-Wilk 검정을 수행합니다.
- 검정의 p-값이 α = 0.05보다 크면 데이터가 정규 분포를 따르는 것으로 가정됩니다.
4. (공식 통계 검정) Kolmogorov-Smirnov 검정을 수행합니다.
- 검정의 p-값이 α = 0.05보다 크면 데이터가 정규 분포를 따르는 것으로 가정됩니다.
다음 예에서는 이러한 각 방법을 실제로 사용하는 방법을 보여줍니다.
방법 1: 히스토그램 만들기
다음 코드는 R에서 정규 분포 및 비정규 분포 데이터 세트에 대한 히스토그램을 만드는 방법을 보여줍니다.
#make this example reproducible
set. seeds (0)
#create data that follows a normal distribution
normal_data <- rnorm(200)
#create data that follows an exponential distribution
non_normal_data <- rexp(200, rate=3)
#define plotting region
by(mfrow=c(1,2))
#create histogram for both datasets
hist(normal_data, col=' steelblue ', main=' Normal ')
hist(non_normal_data, col=' steelblue ', main=' Non-normal ')
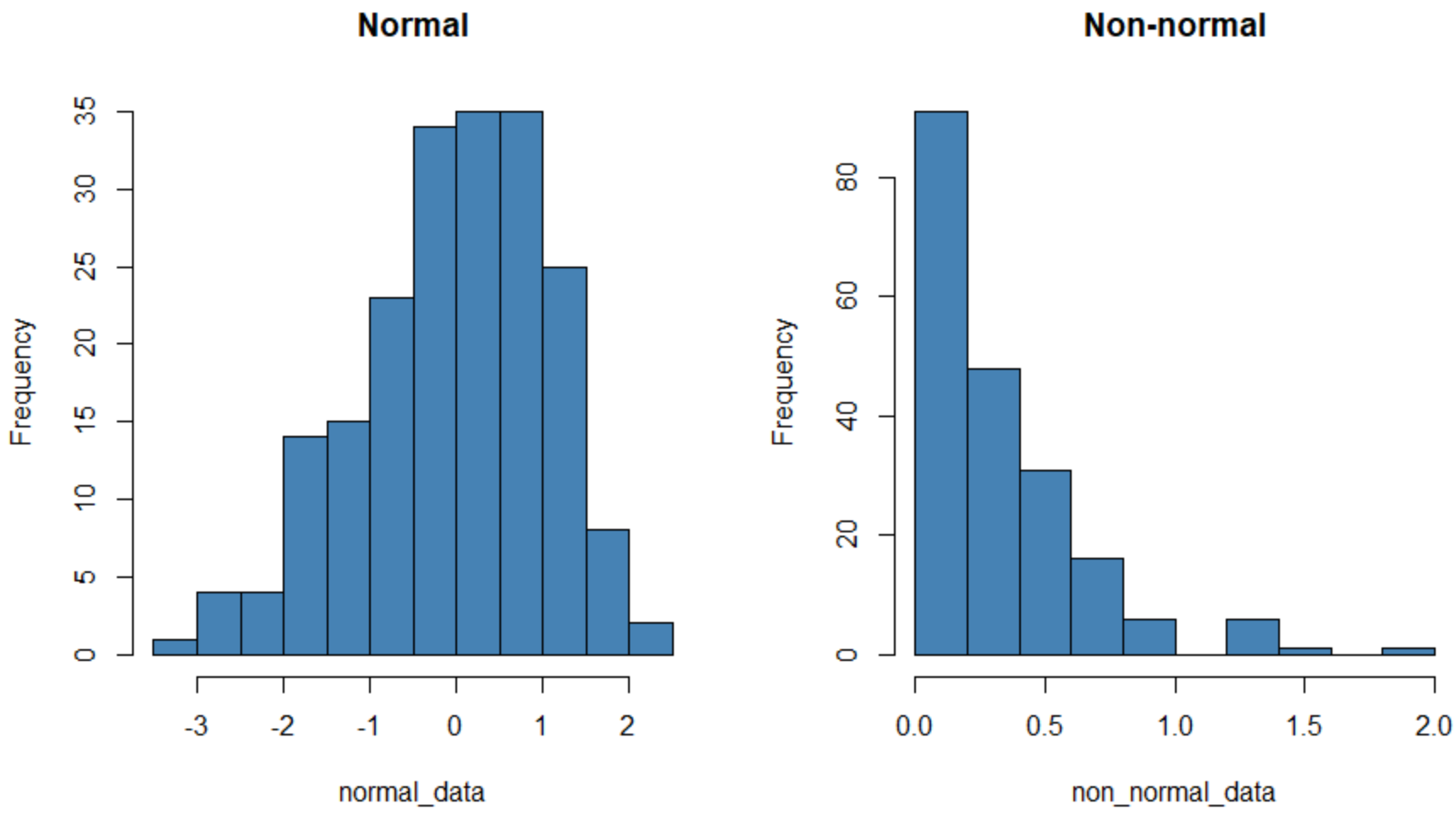
왼쪽의 히스토그램은 정규 분포(대략 “종” 모양)인 데이터 세트를 보여주고, 오른쪽 히스토그램은 정규 분포가 아닌 데이터 세트를 보여줍니다.
방법 2: QQ 플롯 생성
다음 코드는 R에서 정규 분포 및 비정규 분포 데이터 세트에 대한 QQ 플롯을 생성하는 방법을 보여줍니다.
#make this example reproducible
set. seeds (0)
#create data that follows a normal distribution
normal_data <- rnorm(200)
#create data that follows an exponential distribution
non_normal_data <- rexp(200, rate=3)
#define plotting region
by(mfrow=c(1,2))
#create QQ plot for both datasets
qqnorm(normal_data, main=' Normal ')
qqline(normal_data)
qqnorm(non_normal_data, main=' Non-normal ')
qqline(non_normal_data)
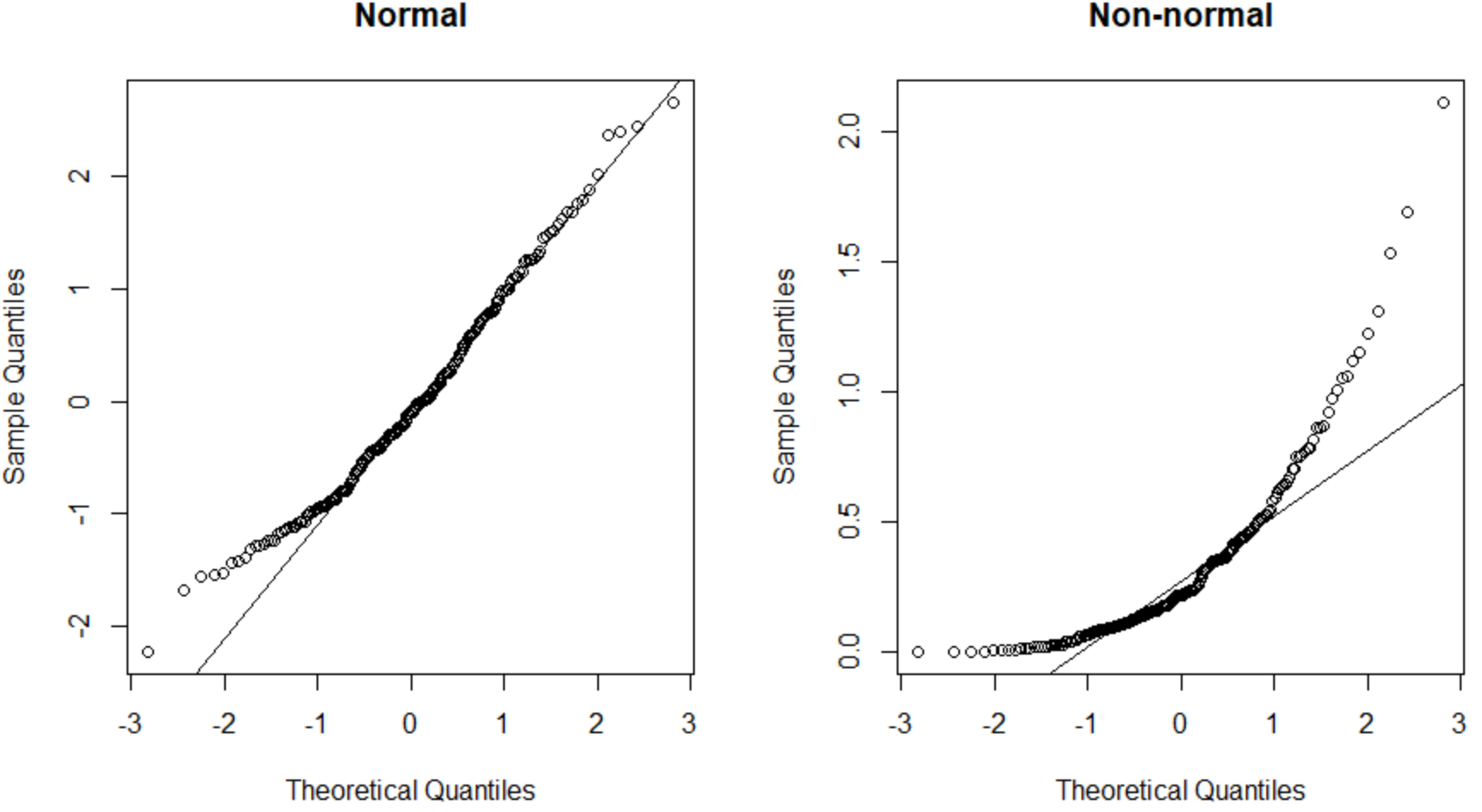
왼쪽의 QQ 플롯은 정규 분포(점들이 직선 대각선을 따라 있음)인 데이터 세트를 나타내고 오른쪽의 QQ 플롯은 정규 분포가 아닌 데이터 세트를 나타냅니다.
방법 3: Shapiro-Wilk 테스트 수행
다음 코드는 R의 정규 분포 및 비정규 분포 데이터 세트에 대해 Shapiro-Wilk 테스트를 수행하는 방법을 보여줍니다.
#make this example reproducible
set. seeds (0)
#create data that follows a normal distribution
normal_data <- rnorm(200)
#perform shapiro-wilk test
shapiro. test (normal_data)
Shapiro-Wilk normality test
data: normal_data
W = 0.99248, p-value = 0.3952
#create data that follows an exponential distribution
non_normal_data <- rexp(200, rate=3)
#perform shapiro-wilk test
shapiro. test (non_normal_data)
Shapiro-Wilk normality test
data: non_normal_data
W = 0.84153, p-value = 1.698e-13
첫 번째 검정의 p-값은 0.05 이상으로 데이터가 정규 분포를 따르고 있음을 나타냅니다.
두 번째 검정의 p-값은 0.05보다 작아 데이터가 정규 분포를 따르지 않음을 나타냅니다.
방법 4: Kolmogorov-Smirnov 테스트 수행
다음 코드는 R에서 정규 분포 및 비정규 분포 데이터 세트에 대해 Kolmogorov-Smirnov 테스트를 수행하는 방법을 보여줍니다.
#make this example reproducible
set. seeds (0)
#create data that follows a normal distribution
normal_data <- rnorm(200)
#perform kolmogorov-smirnov test
ks. test (normal_data, ' pnorm ')
One-sample Kolmogorov–Smirnov test
data: normal_data
D = 0.073535, p-value = 0.2296
alternative hypothesis: two-sided
#create data that follows an exponential distribution
non_normal_data <- rexp(200, rate=3)
#perform kolmogorov-smirnov test
ks. test (non_normal_data, ' pnorm ')
One-sample Kolmogorov–Smirnov test
data: non_normal_data
D = 0.50115, p-value < 2.2e-16
alternative hypothesis: two-sided
첫 번째 검정의 p-값은 0.05 이상으로 데이터가 정규 분포를 따르고 있음을 나타냅니다.
두 번째 검정의 p-값은 0.05보다 작아 데이터가 정규 분포를 따르지 않음을 나타냅니다.
비정규 데이터를 처리하는 방법
주어진 데이터 세트가 정규 분포를 따르지 않는 경우 다음 변환 중 하나를 수행하여 보다 정규 분포를 만들 수 있습니다.
1. 로그 변환: x 값을 log(x) 로 변환합니다.
2. 제곱근 변환: x의 값을 √x 로 변환합니다.
3. 세제곱근 변환: x 값을 x 1/3 으로 변환합니다.
이러한 변환을 수행함으로써 데이터세트는 일반적으로 보다 정규 분포를 띄게 됩니다.
R에서 이러한 변환을 수행하는 방법을 보려면 이 튜토리얼을 읽어보세요.
추가 리소스
R에서 히스토그램을 만드는 방법
R에서 QQ 플롯을 생성하고 해석하는 방법
R에서 Shapiro-Wilk 테스트를 수행하는 방법
R에서 Kolmogorov-Smirnov 테스트를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기