R의 주성분 분석: 단계별 예
흔히 PCA로 축약되는 주성분 분석은 데이터 세트의 변동 중 큰 부분을 설명하는 주성분(원래 예측 변수의 선형 조합)을 찾는 비지도 기계 학습 기술입니다.
PCA의 목표는 원래 데이터 세트보다 더 적은 수의 변수를 사용하여 데이터 세트의 변동성 대부분을 설명하는 것입니다.
p 변수가 있는 특정 데이터 세트에 대해 각 쌍별 변수 조합의 산점도를 검사할 수 있지만 산점도 수가 매우 빨리 커질 수 있습니다.
p개의 예측 변수에 대해 p(p-1)/2개의 점 구름이 존재합니다.
따라서 p = 15개의 예측 변수가 있는 데이터 세트의 경우 105개의 서로 다른 산점도가 있습니다!
다행스럽게도 PCA는 데이터의 변동을 최대한 많이 포착하는 데이터 세트의 저차원 표현을 찾는 방법을 제공합니다.
단 2차원에서 대부분의 변동을 포착할 수 있다면 원본 데이터 세트의 모든 관측치를 간단한 산점도에 투영할 수 있습니다.
주요 구성 요소를 찾는 방법은 다음과 같습니다.
p개의 예측 변수가 있는 데이터 세트 가 주어지면 : _
- Zm = ΣΦ jm _ _
- Z 1 은 가능한 한 많은 분산을 포착하는 예측 변수의 선형 조합입니다.
- Z 2 는 Z 1 과 직교 (상관 관계 없음)하면서 가장 큰 분산을 포착하는 예측 변수의 다음 선형 조합입니다.
- 그러면 Z 3 은 Z 2 와 직교하면서 가장 큰 분산을 포착하는 예측 변수의 다음 선형 조합입니다.
- 등등.
실제로는 다음 단계를 사용하여 원래 예측 변수의 선형 조합을 계산합니다.
1. 평균이 0이고 표준편차가 1이 되도록 각 변수의 크기를 조정합니다.
2. 척도화된 변수에 대한 공분산 행렬을 계산합니다.
3. 공분산 행렬의 고유값을 계산합니다.
선형 대수학을 사용하여 가장 큰 고유값에 해당하는 고유벡터가 첫 번째 주성분임을 보여줄 수 있습니다. 즉, 이 특정 예측 변수 조합은 데이터의 가장 큰 변동을 설명합니다.
두 번째로 큰 고유값에 해당하는 고유벡터는 두 번째 주성분이 되는 식입니다.
이 튜토리얼에서는 R에서 이 프로세스를 수행하는 방법에 대한 단계별 예를 제공합니다.
1단계: 데이터 로드
먼저 데이터 시각화 및 조작을 위한 몇 가지 유용한 기능이 포함된 Tidyverse 패키지를 로드합니다.
library (tidyverse)
이 예에서는 R에 내장된 USArrests 데이터세트를 사용합니다. 이 데이터세트에는 1973년 살인 , 폭행 , 강간 혐의 로 미국 각 주에서 주민 100,000명당 체포된 횟수가 포함되어 있습니다.
또한 도시 지역에 거주하는 각 주의 인구 비율 (UrbanPop) 도 포함됩니다.
다음 코드는 데이터 세트의 첫 번째 행을 로드하고 표시하는 방법을 보여줍니다.
#load data data ("USArrests") #view first six rows of data head(USArrests) Murder Assault UrbanPop Rape Alabama 13.2 236 58 21.2 Alaska 10.0 263 48 44.5 Arizona 8.1 294 80 31.0 Arkansas 8.8 190 50 19.5 California 9.0 276 91 40.6 Colorado 7.9 204 78 38.7
2단계: 주성분 계산
데이터를 로드한 후 R의 내장 함수 prcomp()를 사용하여 데이터 세트의 주요 구성 요소를 계산할 수 있습니다.
주성분을 계산하기 전에 데이터세트의 각 변수가 평균 0, 표준편차 1을 갖도록 척도 = TRUE 로 지정해야 합니다.
또한 R의 고유벡터는 기본적으로 음의 방향을 가리키므로 부호를 반전시키기 위해 -1을 곱할 것입니다.
#calculate main components results <- prcomp(USArrests, scale = TRUE ) #reverse the signs results$rotation <- -1*results$rotation #display main components results$rotation PC1 PC2 PC3 PC4 Murder 0.5358995 -0.4181809 0.3412327 -0.64922780 Assault 0.5831836 -0.1879856 0.2681484 0.74340748 UrbanPop 0.2781909 0.8728062 0.3780158 -0.13387773 Rape 0.5434321 0.1673186 -0.8177779 -0.08902432
첫 번째 주성분(PC1)이 살인, 폭행, 강간에 대해 높은 값을 갖는 것을 볼 수 있는데, 이는 이 주성분이 이러한 변수의 가장 큰 변동을 설명한다는 것을 나타냅니다.
또한 두 번째 주성분(PC2)이 UrbanPop에 대해 높은 값을 갖는 것을 볼 수 있는데, 이는 이 주성분이 도시 인구를 강조한다는 것을 나타냅니다.
각 주의 주성분 점수는 results$x 에 저장됩니다. 또한 부호를 반전시키기 위해 이 점수에 -1을 곱할 것입니다.
#reverse the signs of the scores results$x <- -1*results$x #display the first six scores head(results$x) PC1 PC2 PC3 PC4 Alabama 0.9756604 -1.1220012 0.43980366 -0.154696581 Alaska 1.9305379 -1.0624269 -2.01950027 0.434175454 Arizona 1.7454429 0.7384595 -0.05423025 0.826264240 Arkansas -0.1399989 -1.1085423 -0.11342217 0.180973554 California 2.4986128 1.5274267 -0.59254100 0.338559240 Colorado 1.4993407 0.9776297 -1.08400162 -0.001450164
3단계: Biplot으로 결과 시각화
다음으로 데이터세트의 각 관측치를 첫 번째와 두 번째 주성분을 축으로 사용하는 산점도에 투영하는 도표인 Biplot을 만들 수 있습니다.
scale = 0 이면 플롯의 화살표가 하중을 나타내도록 크기가 조정됩니다.
biplot(results, scale = 0 )
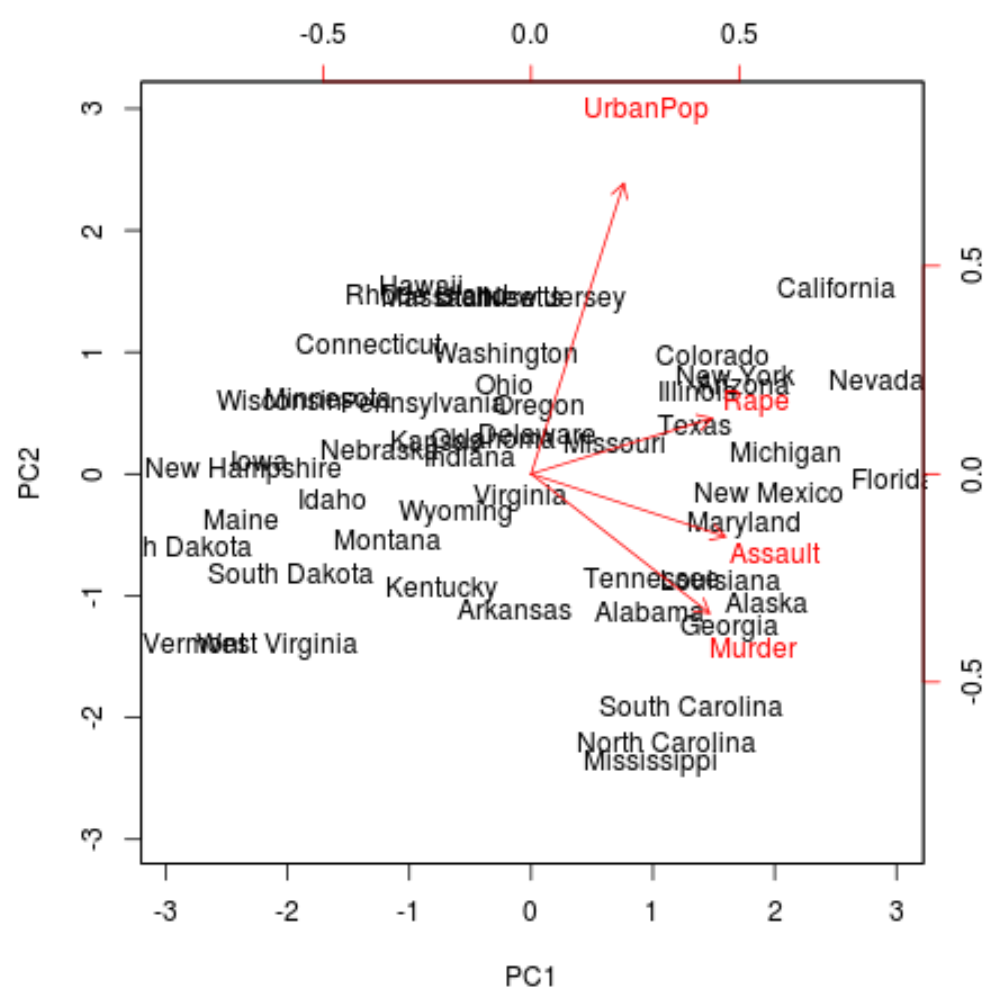
플롯에서 우리는 단순한 2차원 공간에 표현된 50개 상태 각각을 볼 수 있습니다.
그래프에서 서로 가까운 상태는 원래 데이터세트의 변수와 관련하여 유사한 데이터 패턴을 가지고 있습니다.
또한 일부 주에서는 다른 주보다 특정 범죄와 더 밀접하게 연관되어 있음을 알 수 있습니다. 예를 들어, 조지아는 플롯에서 살인 변수에 가장 가까운 주입니다.
원래 데이터세트에서 살인율이 가장 높은 주를 살펴보면 조지아가 실제로 목록의 1위를 차지한다는 것을 알 수 있습니다.
#display states with highest murder rates in original dataset head(USArrests[ order (-USArrests$Murder),]) Murder Assault UrbanPop Rape Georgia 17.4 211 60 25.8 Mississippi 16.1 259 44 17.1 Florida 15.4 335 80 31.9 Louisiana 15.4 249 66 22.2 South Carolina 14.4 279 48 22.5 Alabama 13.2 236 58 21.2
4단계: 각 주성분이 설명하는 분산 찾기
다음 코드를 사용하여 각 주성분으로 설명되는 원본 데이터 세트의 총 분산을 계산할 수 있습니다.
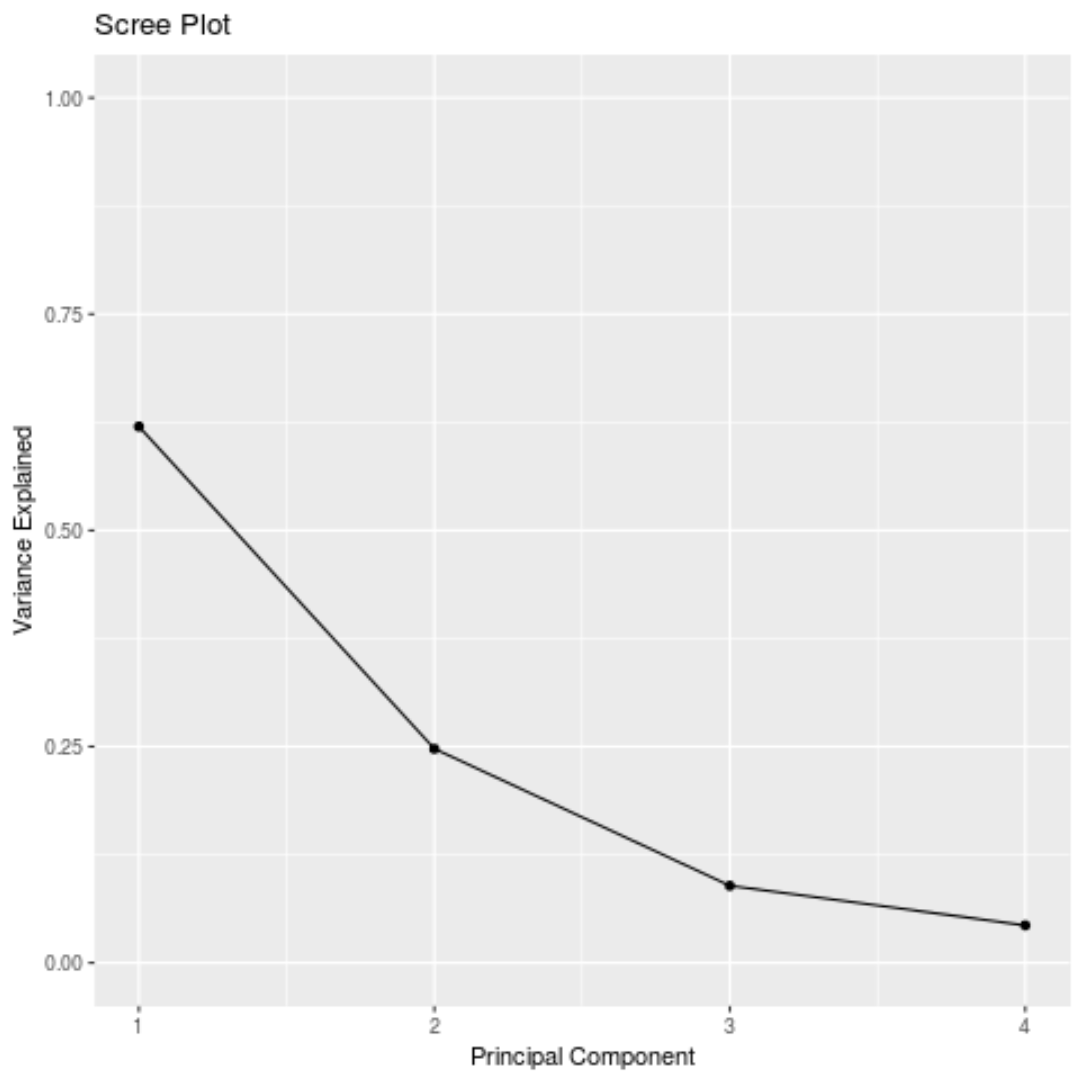
#calculate total variance explained by each principal component results$sdev^2 / sum (results$sdev^2) [1] 0.62006039 0.24744129 0.08914080 0.04335752
결과에서 우리는 다음을 관찰할 수 있습니다.
- 첫 번째 주성분은 데이터세트 전체 분산의 62% 를 설명합니다.
- 두 번째 주성분은 데이터 세트의 전체 분산의 24.7% 를 설명합니다.
- 세 번째 주성분은 데이터세트 전체 분산의 8.9% 를 설명합니다.
- 네 번째 주성분은 데이터세트 전체 분산의 4.3% 를 설명합니다.
따라서 처음 두 가지 주성분은 데이터의 전체 분산의 대부분을 설명합니다.
이전 Biplot에서는 원본 데이터의 각 관측치를 처음 두 개의 주성분만 고려한 산점도에 투영했기 때문에 이는 좋은 신호입니다.
따라서 서로 유사한 상태를 식별하기 위해 Biplot의 패턴을 조사하는 것이 유효합니다.
또한 PCA 결과를 시각화하기 위해 각 주성분에 의해 설명되는 총 분산을 표시하는 그래프인 스크리 플롯을 만들 수도 있습니다.
#calculate total variance explained by each principal component var_explained = results$sdev^2 / sum (results$sdev^2) #create scree plot qplot(c(1:4), var_explained) + geom_line() + xlab(" Principal Component ") + ylab(" Variance Explained ") + ggtitle(" Scree Plot ") + ylim(0, 1)
실제 주성분 분석
실제로 PCA는 다음 두 가지 이유로 가장 자주 사용됩니다.
1. 탐색적 데이터 분석 – 데이터 세트를 처음 탐색하고 데이터의 어떤 관찰이 서로 가장 유사한지 이해하려고 할 때 PCA를 사용합니다.
2. 주성분 회귀 – PCA를 사용하여 주성분 회귀 에 사용할 수 있는 주성분을 계산할 수도 있습니다. 이러한 유형의 회귀는 데이터 세트의 예측 변수 간에 다중 공선성이 있을 때 자주 사용됩니다.
이 튜토리얼에 사용된 전체 R 코드는 여기에서 찾을 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기