R에서 chow 테스트를 수행하는 방법
Chow 테스트는 서로 다른 데이터 세트에 대한 두 개의 서로 다른 회귀 모델의 계수가 동일한지 여부를 테스트하는 데 사용됩니다.
이 테스트는 일반적으로 시계열 데이터를 사용하는 계량경제학 분야에서 특정 시점에 데이터에 구조적 중단이 있는지 확인하는 데 사용됩니다.
이 튜토리얼에서는 R에서 Chow 테스트를 수행하는 방법에 대한 단계별 예를 제공합니다.
1단계: 데이터 생성
먼저 가짜 데이터를 만듭니다.
#create data data <- data.frame(x = c(1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20), y = c(3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36)) #view first six rows of data head(data) xy 1 1 3 2 1 5 3 2 6 4 3 10 5 4 13 6 4 15
2단계: 데이터 시각화
다음으로, 데이터를 시각화하기 위한 간단한 산점도를 만들어 보겠습니다.
#load ggplot2 visualization package library (ggplot2) #create scatterplot ggplot(data, aes (x = x, y = y)) + geom_point(col=' steelblue ', size= 3 )
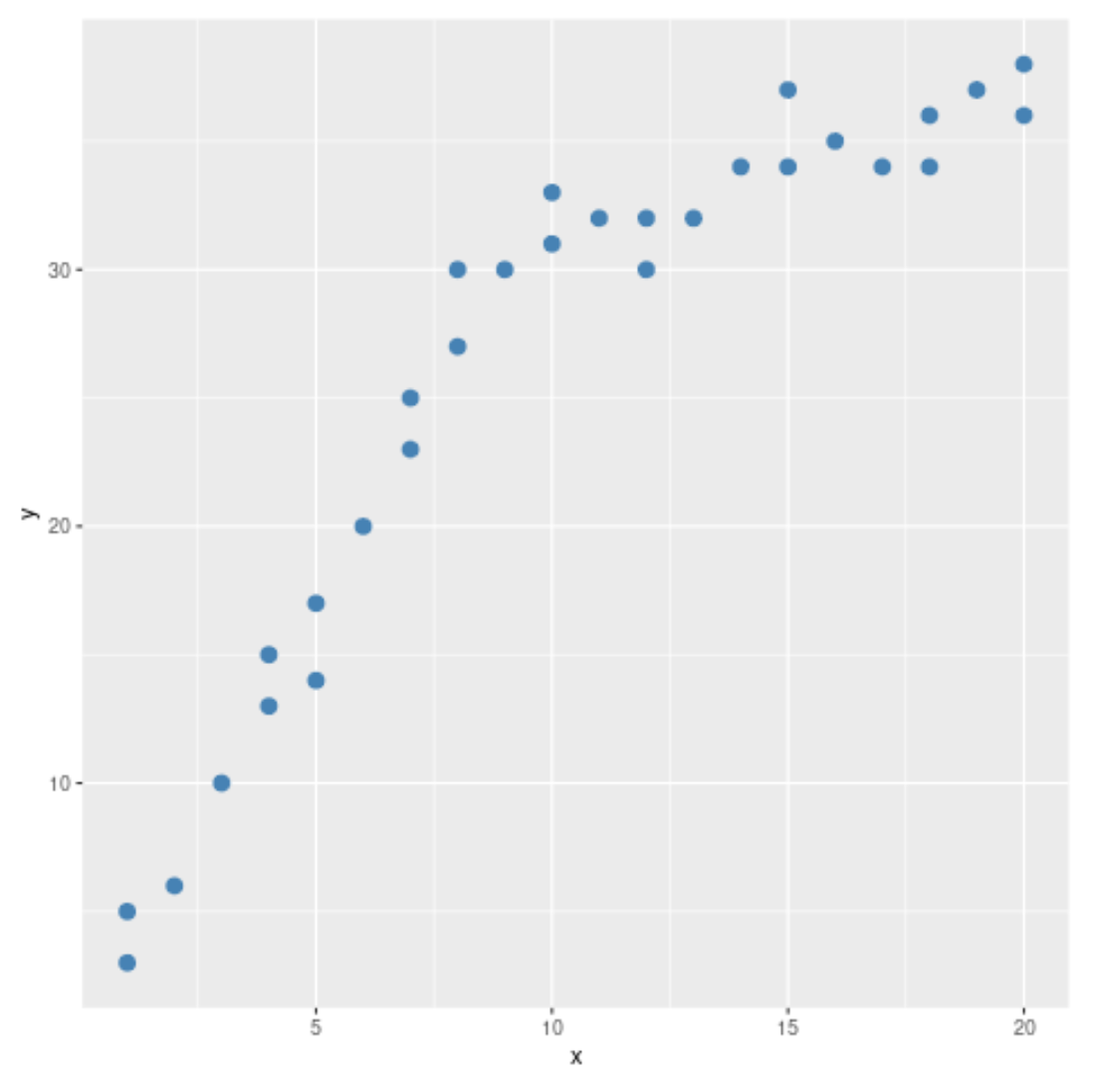
산점도에서 데이터의 패턴이 x = 10에서 변경되는 것으로 나타나는 것을 볼 수 있습니다. 따라서 x = 10에서 데이터에 구조적 중단점이 있는지 확인하기 위해 Chow 테스트를 수행할 수 있습니다.
3단계: 차우 테스트 수행
strucchange 패키지의 sctest 함수를 사용하여 Chow 테스트를 수행할 수 있습니다 .
#load strucchange package library (strucchange) #perform Chow test sctest(data$y ~ data$x, type = " Chow ", point = 10 ) Chow test data: data$y ~ data$x F = 110.14, p-value = 2.023e-13
테스트 결과에서 다음을 확인할 수 있습니다.
- F-검정 통계량 : 110.14
- p-값: <.0000
p-값이 0.05보다 작으므로 검정의 귀무가설을 기각할 수 있습니다. 이는 데이터에 구조적 중단점이 존재한다고 말할 수 있는 충분한 증거가 있음을 의미합니다.
즉, 두 개의 회귀선이 단일 회귀선보다 데이터에 모델을 더 효과적으로 맞출 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기