R의 능선 회귀(단계별)
능형 회귀는 데이터에 다중 공선성이 존재할 때 회귀 모델을 적합시키는 데 사용할 수 있는 방법입니다.
간단히 말해서, 최소 제곱 회귀는 잔차 제곱합(RSS)을 최소화하는 계수 추정값을 찾으려고 시도합니다.
RSS = Σ(y i – ŷ i )2
금:
- Σ : 합계를 의미하는 그리스 기호
- y i : i번째 관측값에 대한 실제 응답 값
- ŷ i : 다중선형회귀모델을 기반으로 예측된 반응값
반대로, 능선 회귀는 다음을 최소화하려고 합니다.
RSS + λΣβ j 2
여기서 j는 1에서 p개의 예측 변수로 이동하고 λ ≥ 0입니다.
방정식의 두 번째 항은 인출 페널티 로 알려져 있습니다. 능선 회귀 분석에서는 가능한 가장 낮은 MSE 테스트(평균 제곱 오차)를 생성하는 λ 값을 선택합니다.
이 튜토리얼에서는 R에서 능선 회귀를 수행하는 방법에 대한 단계별 예를 제공합니다.
1단계: 데이터 로드
이 예에서는 mtcars 라는 R의 내장 데이터 세트를 사용합니다. hp를 반응 변수로 사용하고 다음 변수를 예측 변수로 사용합니다.
- mpg
- 무게
- 똥
- q초
능선 회귀를 수행하기 위해 glmnet 패키지의 기능을 사용합니다. 이 패키지에서는 응답 변수가 벡터여야 하고 예측 변수 세트가 data.matrix 클래스에 속해야 합니다.
다음 코드는 데이터를 정의하는 방법을 보여줍니다.
#define response variable
y <- mtcars$hp
#define matrix of predictor variables
x <- data.matrix(mtcars[, c('mpg', 'wt', 'drat', 'qsec')])
2단계: 능형 회귀 모델 적합
다음으로 glmnet() 함수를 사용하여 Ridge 회귀 모델을 맞추고 alpha=0 을 지정합니다.
알파를 1로 설정하는 것은 올가미 회귀를 사용하는 것과 동일하며, 알파를 0과 1 사이의 값으로 설정하는 것은 탄성망을 사용하는 것과 동일합니다.
또한 능형 회귀 분석에서는 각 예측 변수의 평균이 0이고 표준 편차가 1이 되도록 데이터를 표준화해야 합니다.
다행히 glmnet()은 자동으로 이 표준화를 수행합니다. 변수를 이미 표준화한 경우에는 standardize=False를 지정할 수 있습니다.
library (glmnet)
#fit ridge regression model
model <- glmnet(x, y, alpha = 0 )
#view summary of model
summary(model)
Length Class Mode
a0 100 -none- numeric
beta 400 dgCMatrix S4
df 100 -none- numeric
dim 2 -none- numeric
lambda 100 -none- numeric
dev.ratio 100 -none- numeric
nulldev 1 -none- numeric
npasses 1 -none- numeric
jerr 1 -none- numeric
offset 1 -none- logical
call 4 -none- call
nobs 1 -none- numeric
3단계: Lambda에 대한 최적 값 선택
다음으로 k-겹 교차 검증을 사용하여 가장 낮은 테스트 평균 제곱 오차(MSE)를 생성하는 람다 값을 식별합니다.
다행히 glmnet에는 k = 10번을 사용하여 k-겹 교차 검증을 자동으로 수행하는 cv.glmnet() 함수가 있습니다.
#perform k-fold cross-validation to find optimal lambda value
cv_model <- cv. glmnet (x, y, alpha = 0 )
#find optimal lambda value that minimizes test MSE
best_lambda <- cv_model$ lambda . min
best_lambda
[1] 10.04567
#produce plot of test MSE by lambda value
plot(cv_model)
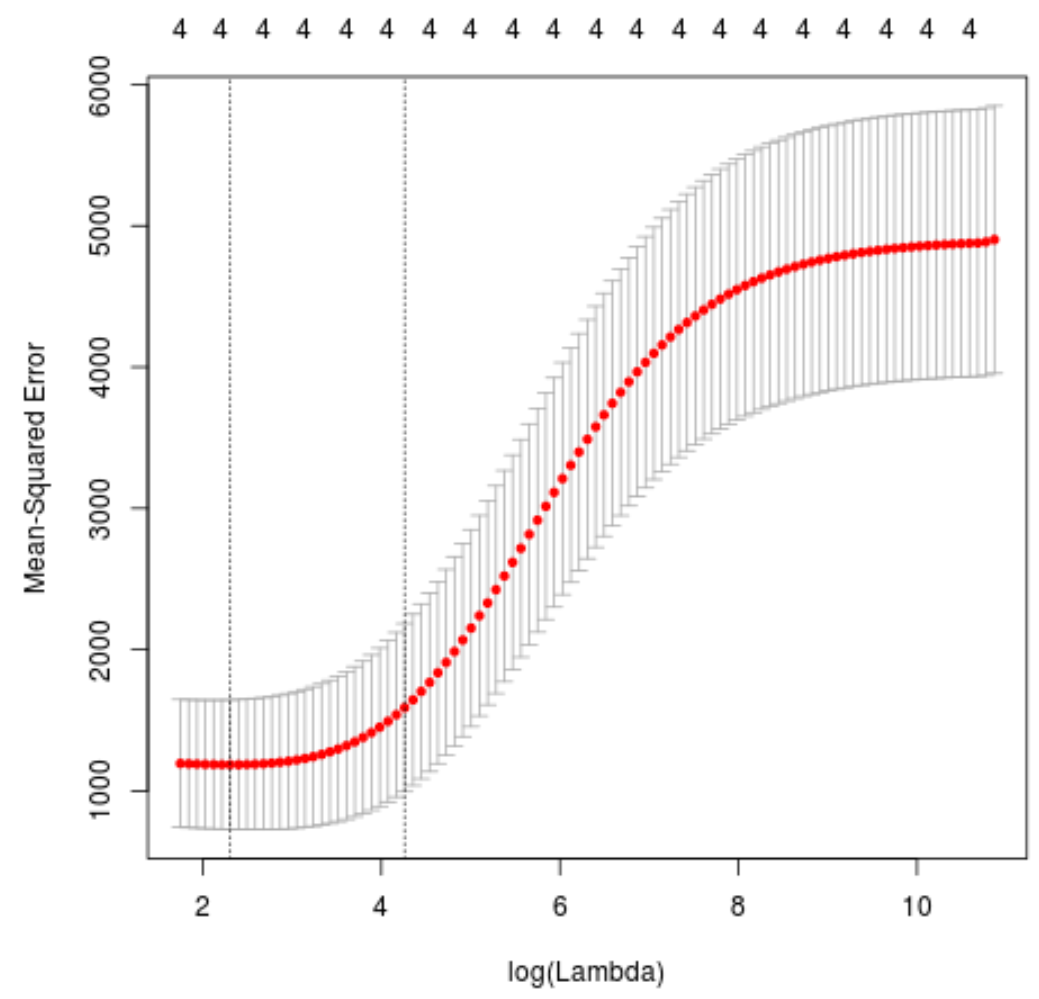
MSE 테스트를 최소화하는 람다 값은 10.04567 입니다.
4단계: 최종 모델 분석
마지막으로 최적의 람다 값을 통해 생성된 최종 모델을 분석할 수 있다.
다음 코드를 사용하여 이 모델에 대한 계수 추정치를 얻을 수 있습니다.
#find coefficients of best model
best_model <- glmnet(x, y, alpha = 0 , lambda = best_lambda)
coef(best_model)
5 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 475.242646
mpg -3.299732
wt 19.431238
drat -1.222429
qsec -17.949721
또한 람다 증가로 인해 계수 추정값이 어떻게 변경되었는지 시각화하기 위해 추적 플롯을 생성할 수도 있습니다.
#produce Ridge trace plot
plot(model, xvar = " lambda ")
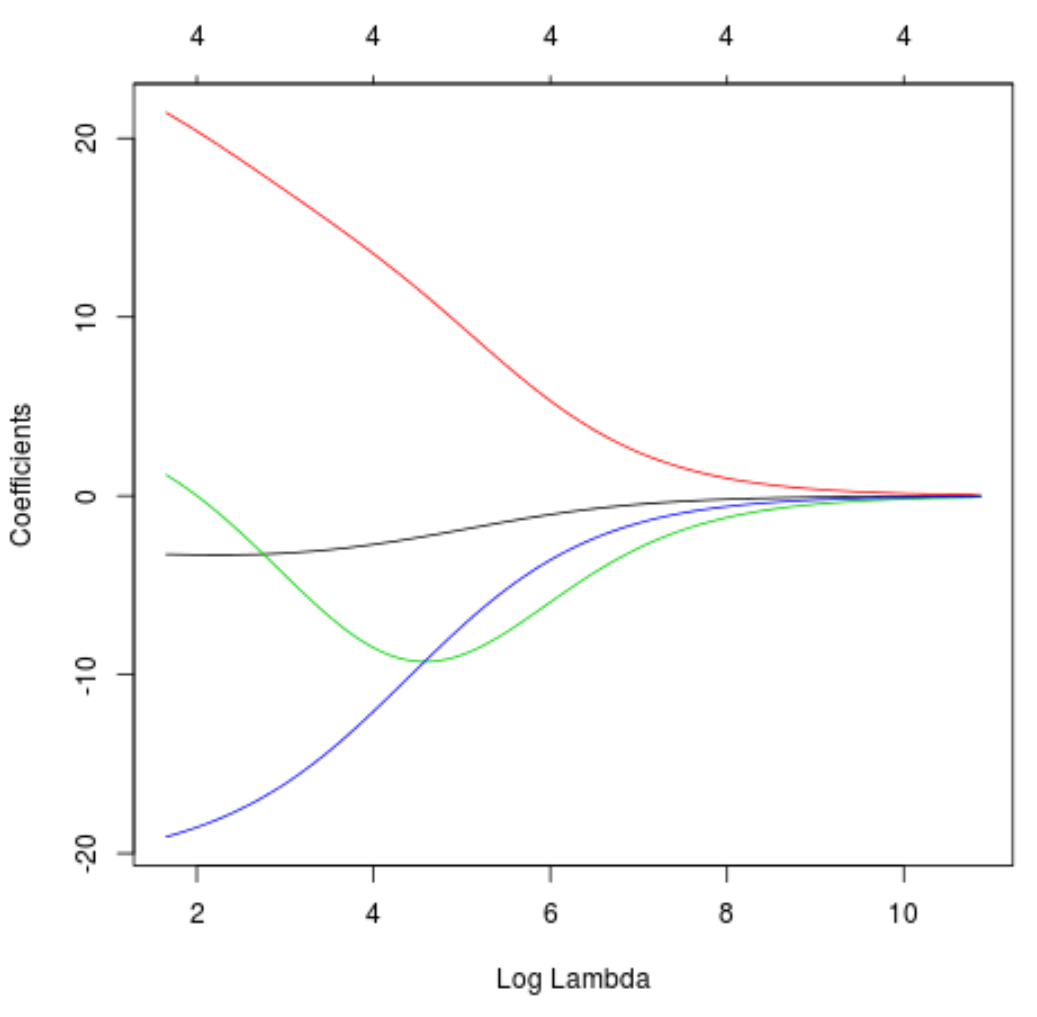
마지막으로 훈련 데이터에 대한 모델의 R-제곱을 계산할 수 있습니다.
#use fitted best model to make predictions
y_predicted <- predict (model, s = best_lambda, newx = x)
#find OHS and SSE
sst <- sum ((y - mean (y))^2)
sse <- sum ((y_predicted - y)^2)
#find R-Squared
rsq <- 1 - sse/sst
rsq
[1] 0.7999513
R 제곱은 0.7999513 입니다. 즉, 가장 좋은 모델은 훈련 데이터의 반응값 변화를 79.99% 설명할 수 있었다.
이 예제에 사용된 전체 R 코드는 여기에서 찾을 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기