Sas에서 주성분 분석을 수행하는 방법
주성분 분석(PCA)은 데이터 세트의 변동 중 큰 부분을 설명하는 주성분(예측 변수의 선형 조합)을 찾는 비지도 기계 학습 기술입니다.
SAS에서 PCA를 수행하는 가장 간단한 방법은 다음 기본 구문을 사용하는 PROC PRINCOMP 문을 사용하는 것입니다.
proc princomp data =my_data out =out_data outstat =stats; var var1 var2 var3; run ;
각 명령이 수행하는 작업은 다음과 같습니다.
- data : PCA에 사용할 데이터 세트의 이름
- out : 모든 원본 데이터와 주성분 점수를 포함하는 생성할 데이터 세트의 이름입니다.
- outstat : 평균, 표준 편차, 상관 계수, 고유값 및 고유 벡터를 포함하는 데이터 세트를 생성하도록 지정합니다.
- var : 입력 데이터 세트에서 PCA에 사용할 변수입니다.
다음 단계별 예에서는 실제로 PROC PRINCOMP 문을 사용하여 SAS에서 주성분 분석을 수행하는 방법을 보여줍니다.
1단계: 데이터세트 만들기
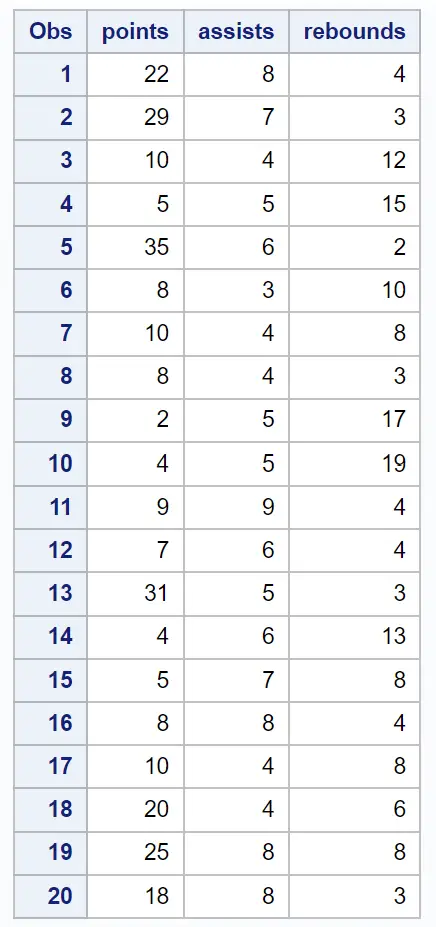
20명의 농구 선수에 대한 다양한 정보가 포함된 다음 데이터 세트가 있다고 가정합니다.
/*create dataset*/ data my_data; input points assists rebounds; datalines ; 22 8 4 29 7 3 10 4 12 5 5 15 35 6 2 8 3 10 10 4 8 8 4 3 2 5 17 4 5 19 9 9 4 7 6 4 31 5 3 4 6 13 5 7 8 8 8 4 10 4 8 20 4 6 25 8 8 18 8 3 ; run ; /*view dataset*/ proc print data =my_data;
2단계: 주성분 분석 수행
PROC PRINCOMP 문을 사용하면 데이터세트의 points , Assists 및 Bounces 변수를 사용하여 주성분 분석을 수행할 수 있습니다.
/*perform principal components analysis*/ proc princomp data =my_data out =out_data outstat =stats; var points assists rebounds; run ;
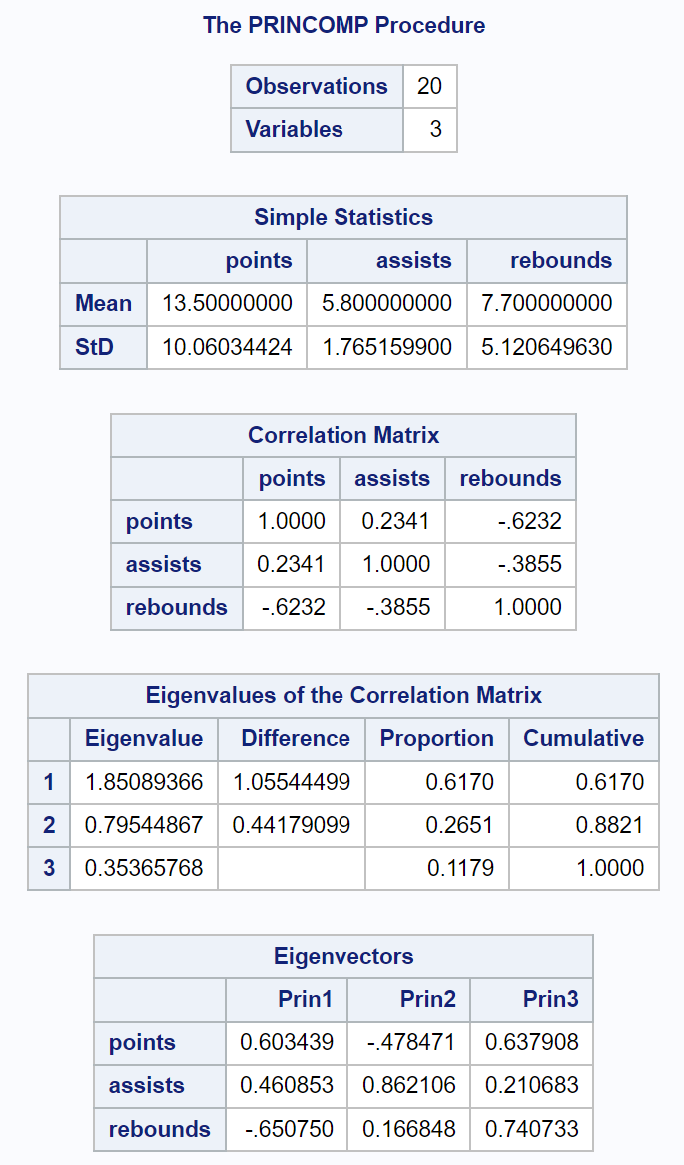
출력의 첫 번째 부분에는 각 입력 변수의 평균 및 표준 편차, 상관 행렬, 고유값 및 고유벡터 값을 포함한 다양한 기술 통계가 표시됩니다.
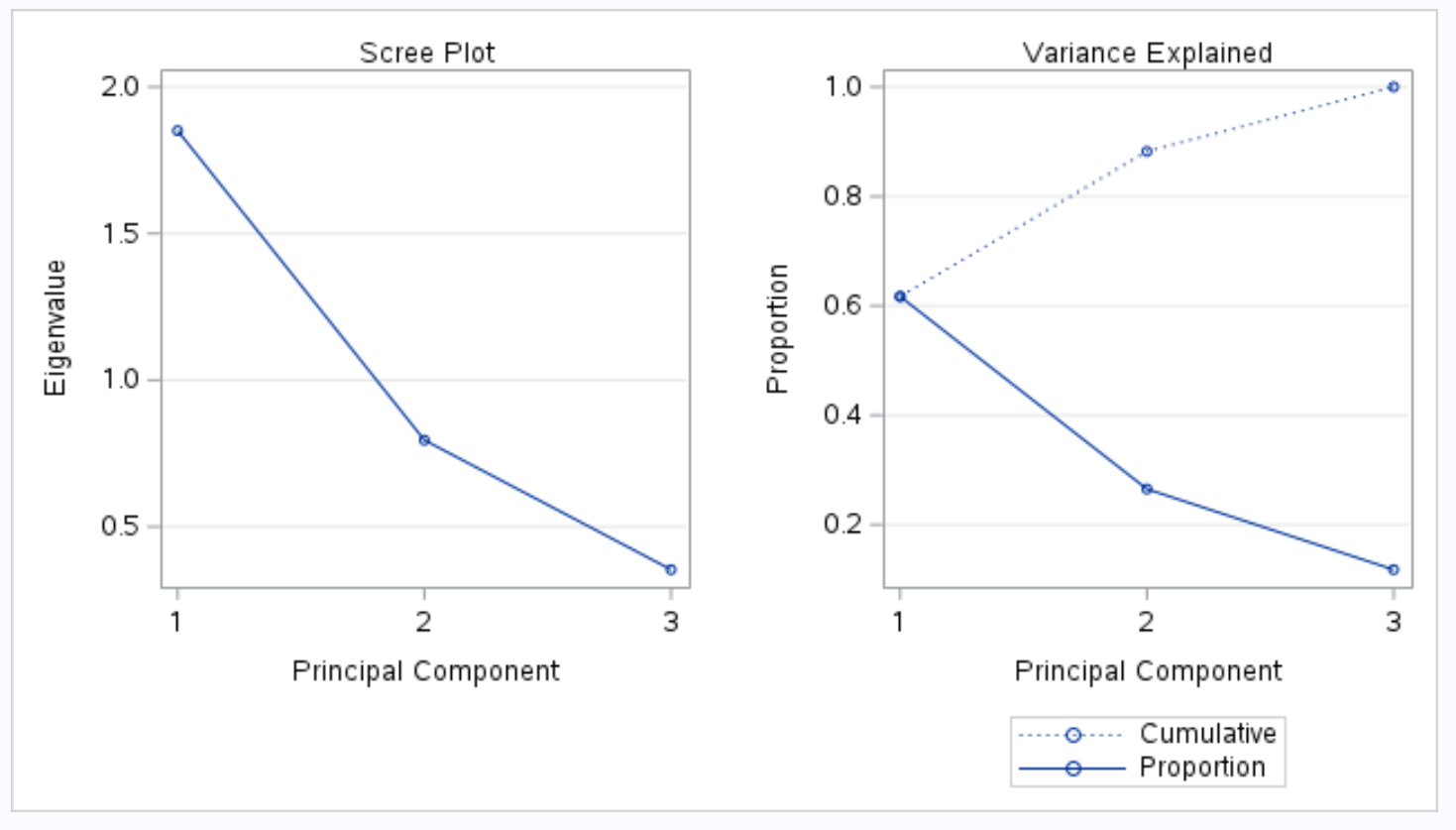
출력의 다음 부분에는 Scree 플롯 과 설명된 분산 플롯이 표시됩니다.
PCA를 수행할 때 데이터 세트의 전체 변동 중 각 주성분이 몇 퍼센트를 설명할 수 있는지 이해하려는 경우가 많습니다.
Correlation Matrix Eigenvalues 라는 제목의 결과 테이블을 통해 각 주성분이 전체 변동의 몇 퍼센트를 설명하는지 정확히 확인할 수 있습니다.
- 첫 번째 주성분은 데이터세트 전체 변동의 61.7% 를 설명합니다.
- 두 번째 주성분은 데이터 세트의 전체 변동의 26.51% 를 설명합니다.
- 세 번째 주성분은 데이터 세트의 전체 변동의 11.79% 를 설명합니다.
모든 백분율을 더하면 100%가 됩니다.
그러면 Variance explained 라는 제목의 플롯을 통해 이러한 값을 시각화할 수 있습니다.
x축은 주성분을 표시하고 y축은 각 개별 주성분이 설명하는 전체 분산의 백분율을 표시합니다.
3단계: 결과를 시각화하기 위한 Biplot 만들기
주어진 데이터 세트에 대한 PCA 결과를 시각화하기 위해 처음 두 개의 주성분으로 구성된 평면에 데이터 세트의 각 관측치를 표시하는 도표인 biplot을 만들 수 있습니다.
SAS에서 다음 구문을 사용하여 Biplot을 만들 수 있습니다.
/*create dataset with column called obs to represent row numbers of original data*/
data biplot_data;
set out_data;
obs=_n_;
run ;
/*create biplot using values from first two principal components*/
proc sgplot data =biplot_data;
scatter x =Prin1 y =Prin2 / datalabel =obs;
run ;
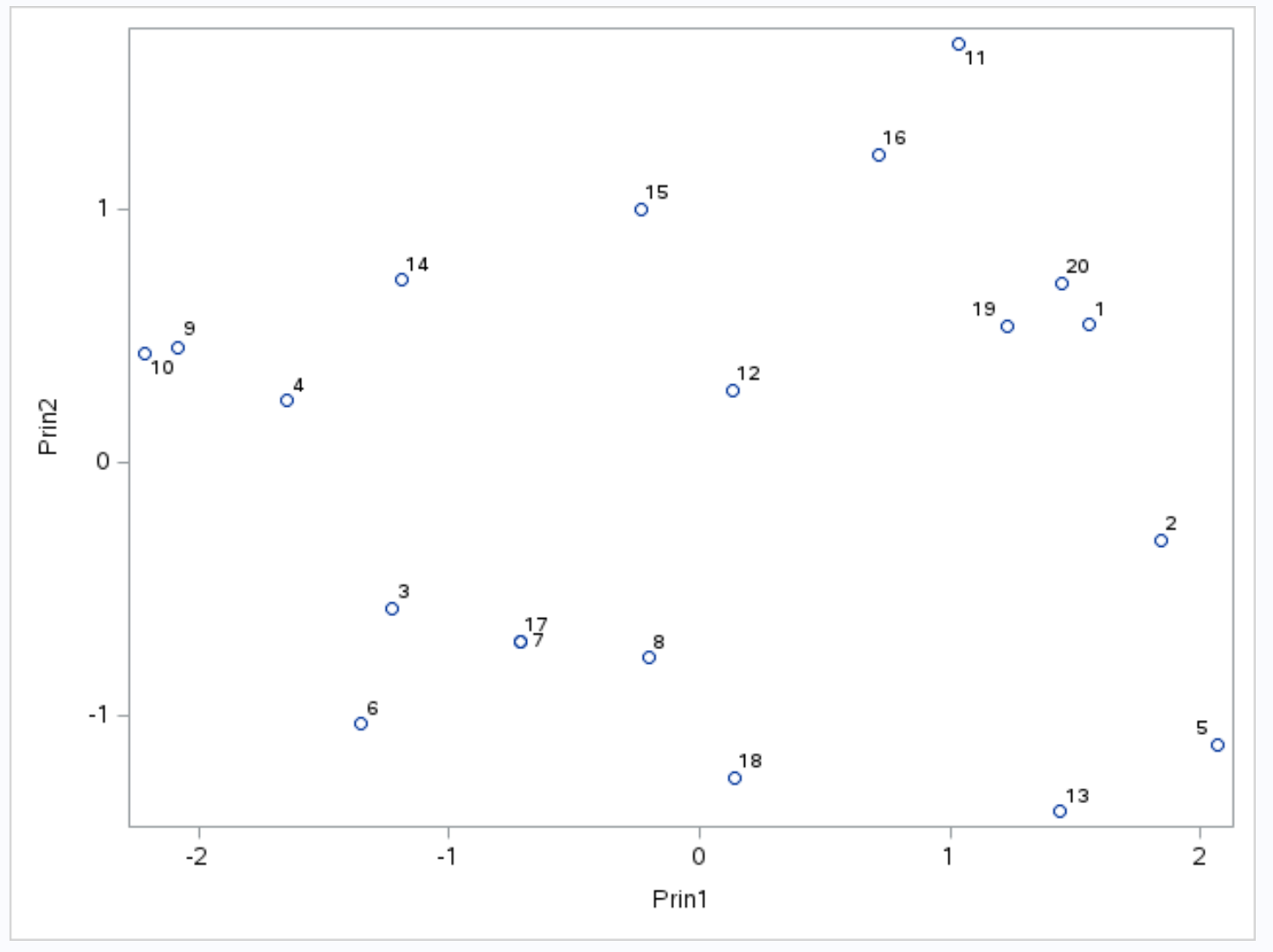
x축은 첫 번째 주성분을 표시하고, y축은 두 번째 주성분을 표시하며, 데이터세트의 개별 관측값은 그래프 내부에 작은 원으로 표시됩니다.
그래프에 나란히 표시된 관측값은 포인트 , 어시스트 , 리바운드 의 세 가지 변수에 대해 비슷한 값을 갖습니다.
예를 들어, 그래프의 가장 왼쪽에서 관측치 #9 와 #10이 서로 매우 가깝다는 것을 알 수 있습니다.
원본 데이터 세트를 참조하면 이러한 관찰에 대해 다음 값을 볼 수 있습니다.
- 관찰 9번 : 2득점, 5어시스트, 17리바운드
- 관찰 #10 : 4득점, 5어시스트, 19리바운드
값은 세 변수 각각에 대해 유사하며, 이는 이러한 관측치가 Biplot에서 서로 너무 가까운 이유를 설명합니다.
또한 Correlation Matrix Eigenvalues 라는 결과 테이블에서 처음 두 개의 주성분이 데이터 세트의 전체 변동의 88.21% 를 설명한다는 것을 확인했습니다.
이 백분율은 매우 높기 때문에 Biplot을 구성하는 두 가지 주요 구성 요소가 데이터 세트의 거의 모든 변동을 설명하기 때문에 Biplot의 어떤 관측치가 서로 가까운지 분석하는 것이 유효합니다.
추가 리소스
다음 튜토리얼에서는 SAS에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
SAS에서 단순 선형 회귀를 수행하는 방법
SAS에서 다중 선형 회귀를 수행하는 방법
SAS에서 로지스틱 회귀를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기