Sas에서 proc glmselect 문을 사용하는 방법
SAS의 PROC GLMSELECT 문을 사용하여 잠재적인 예측 변수 목록을 기반으로 최상의 회귀 모델을 선택할 수 있습니다.
다음 예에서는 이 문을 실제로 사용하는 방법을 보여줍니다.
예: 모델 선택을 위해 SAS에서 PROC GLMSELECT를 사용하는 방법
(1) 공부에 소비한 시간, (2) 응시한 준비 시험 수, (3) 성별을 사용하여 학생의 ‘시험 최종 성적’을 예측하는 다중 선형 회귀 모델을 적합화한다고 가정합니다.
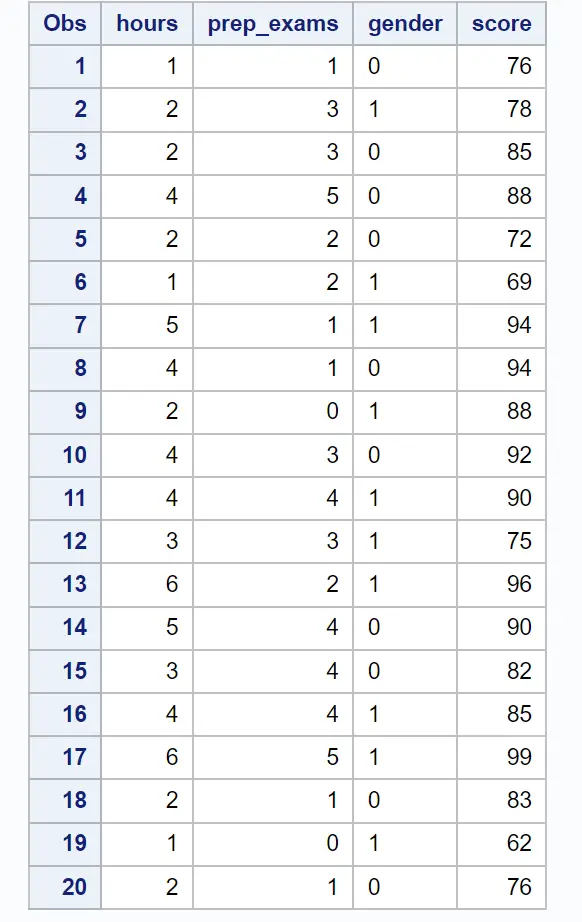
먼저 다음 코드를 사용하여 학생 20명에 대한 이 정보가 포함된 데이터세트를 만듭니다.
/*create dataset*/ data exam_data; input hours prep_exams gender $score; datalines ; 1 1 0 76 2 3 1 78 2 3 0 85 4 5 0 88 2 2 0 72 1 2 1 69 5 1 1 94 4 1 0 94 2 0 1 88 4 3 0 92 4 4 1 90 3 3 1 75 6 2 1 96 5 4 0 90 3 4 0 82 4 4 1 85 6 5 1 99 2 1 0 83 1 0 1 62 2 1 0 76 ; run ; /*view dataset*/ proc print data =exam_data;
다음으로, PROC GLMSELECT 문을 사용하여 최상의 회귀 모델을 생성하는 예측 변수의 하위 집합을 식별합니다.
/*perform model selection*/
proc glmselect data =exam_data;
classgender ;
model score = hours prep_exams gender;
run ;
참고 : 성별은 범주형 변수이기 때문에 클래스 문에 포함했습니다.
출력의 첫 번째 테이블 그룹은 GLMSELECT 프로시저의 개요를 보여줍니다.
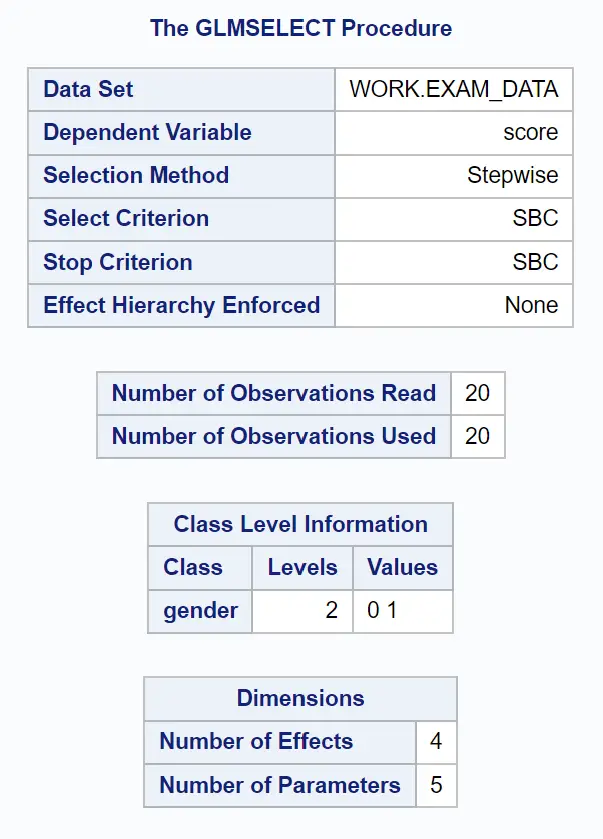
모델에 변수를 추가하거나 제거하는 것을 중지하는 데 사용된 기준은 SBC 였으며 이는 베이지안 정보 기준 이라고도 불리는 Schwarz 정보 기준 입니다.
기본적으로 PROC GLMSELECT 문은 “최상의” 모델로 간주되는 가장 낮은 SBC 값을 가진 모델을 찾을 때까지 모델에서 변수를 계속 추가하거나 제거합니다.
다음 테이블 그룹은 단계별 선택이 어떻게 종료되었는지 보여줍니다.
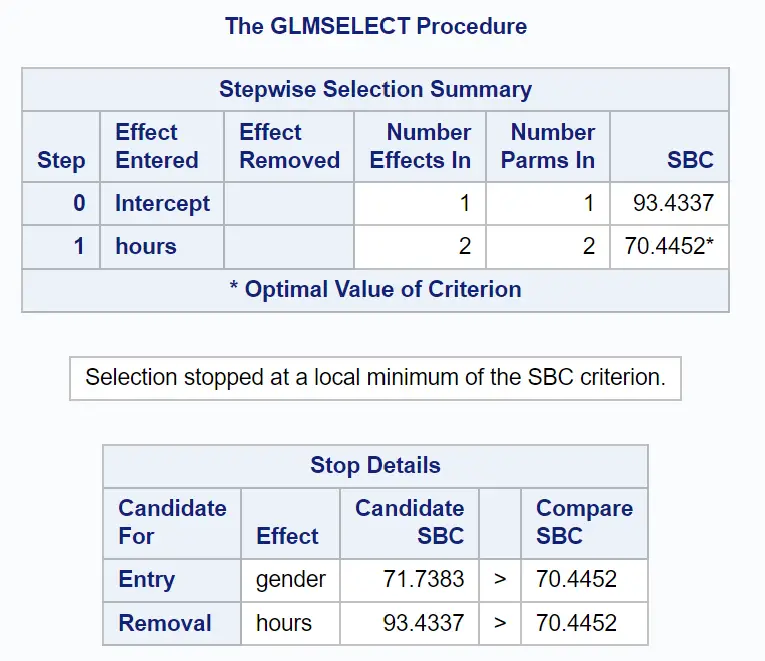
원래 항만 있는 모델의 SBC 값은 93.4337 임을 알 수 있습니다.
모델에 예측 변수로 시간을 추가하면 SBC 값이 70.4452 로 떨어졌습니다.
모델을 개선하는 가장 좋은 방법은 성별을 예측 변수로 추가하는 것이었지만 이로 인해 실제로 SBC 값이 71.7383으로 증가했습니다.
따라서 최종 모델에는 절편 항과 연구된 시간만 포함됩니다.
결과의 마지막 부분은 이 적합 회귀 모델의 요약을 보여줍니다.
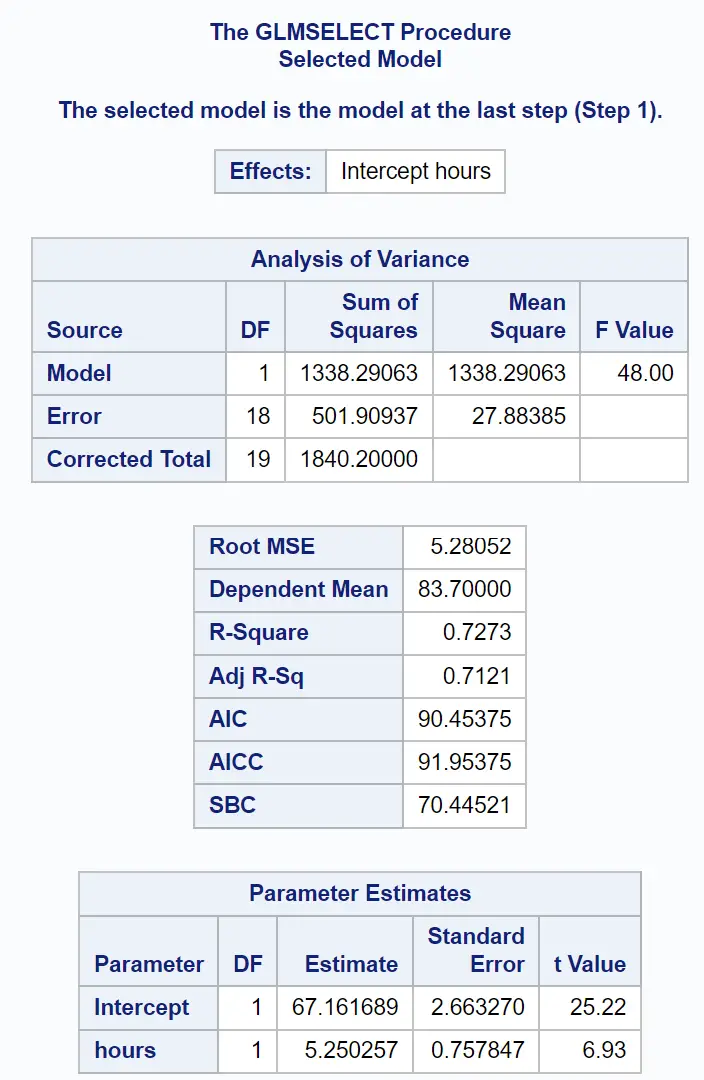
매개변수 추정값 표의 값을 사용하여 적합 회귀 모델을 작성할 수 있습니다.
시험 점수 = 67.161689 + 5.250257(공부한 시간)
또한 이 모델이 데이터에 얼마나 잘 맞는지 알려주는 다양한 측정항목도 볼 수 있습니다.
R-Square 값은 공부한 시간과 응시한 준비 시험 횟수로 설명할 수 있는 시험 점수의 변동 비율을 알려줍니다.
이 경우 시험점수 변동의 72.73% 는 공부시간과 준비시험 횟수로 설명할 수 있다.
루트 MSE 값도 알아두면 유용합니다. 이는 관측값과 회귀선 사이의 평균 거리를 나타냅니다.
이 회귀 모델에서 관측값은 회귀선에서 평균 5.28052 단위만큼 벗어납니다.
참고 : PROC GLMSELECT 와 함께 사용할 수 있는 잠재적 인수의 전체 목록은 SAS 설명서를 참조하세요.
추가 리소스
다음 튜토리얼에서는 SAS에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
SAS에서 단순 선형 회귀를 수행하는 방법
SAS에서 다중 선형 회귀를 수행하는 방법
SAS에서 다항식 회귀를 수행하는 방법
SAS에서 로지스틱 회귀를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기