Sas에서 proc surveyselect를 사용하는 방법(예제 포함)
PROC SURVEYSELECT를 사용하여 SAS의 데이터 세트에서 무작위 샘플을 선택할 수 있습니다.
실제로 이 절차를 사용하는 세 가지 일반적인 방법은 다음과 같습니다.
예 1: PROC SURVEYSELECT를 사용하여 단순 무작위 표본 선택
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =5 /*select a total of 5 observations*/
seed =1; /*set seed to make this example reproducible*/
run ;
이 특별한 예는 데이터 세트에서 5개의 무작위 관측치를 선택합니다.
예 2: PROC SURVEYSELECT를 사용하여 계층화된 무작위 표본 선택
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =2 /*select 2 observations from each strata*/
seed =1; /*set seed to make this example reproducible*/
strata grouping_var; /*specify variable to use for stratification*/
run ;
이 특정 예는 데이터 세트의 각 고유 계층에서 2개의 무작위 관측치를 선택합니다.
Strata 문은 계층화에 사용할 변수를 지정합니다.
예 3: PROC SURVEYSELECT를 사용하여 합동 무작위 표본 선택
proc surveyselect data =my_data
out =my_sample
n =2 /*select 2 clusters*/
seed =1; /*set seed to make this example reproducible*/
clustergrouping_var ; /*specify variable to use for stratification*/
run ;
이 특정 예는 데이터 세트에서 2개의 무작위 클러스터를 선택하고 샘플의 모든 클러스터에서 모든 관측치를 포함합니다.
클러스터 문은 클러스터링에 사용할 변수를 지정합니다.
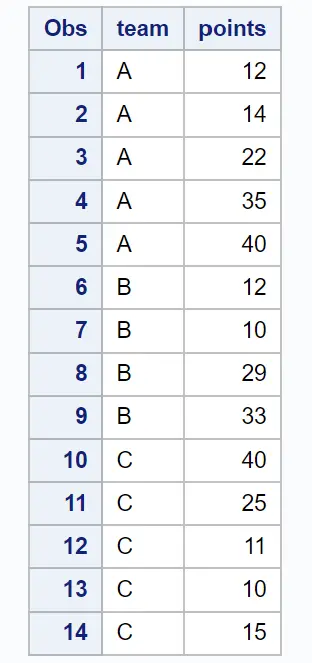
다음 예에서는 다양한 팀의 농구 선수에 대한 정보가 포함된 SAS의 다음 데이터 세트를 사용하여 실제로 각 방법을 사용하는 방법을 보여줍니다.
/*create dataset*/
data my_data;
input team $points;
datalines ;
AT 12
At 14
At 22
At 35
At 40
B 12
B 10
B29
B 33
C40
C25
C 11
C 10
C15
;
run ;
/*view dataset*/
proc print data = my_data;
예 1: PROC SURVEYSELECT를 사용하여 단순 무작위 표본 선택
다음 구문을 사용하여 데이터세트에서 5개 관측값의 단순 무작위 샘플을 선택할 수 있습니다.
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =5 /*select a total of 5 observations*/
seed =1; /*set seed to make this example reproducible*/
run ;
/*view sample*/
proc print data =my_sample;
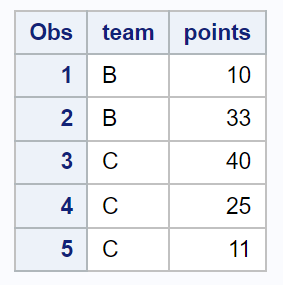
결과 샘플에는 데이터 세트에서 무작위로 선택된 5개의 관측치가 포함됩니다.
예 2: PROC SURVEYSELECT를 사용하여 계층화된 무작위 표본 선택
다음 구문을 사용하여 각 팀에서 2개의 관측치를 무작위로 선택하여 표본에 포함시키는 계층화된 무작위 샘플링을 수행할 수 있습니다.
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling within strata*/
n =2 /*select 2 observations from each strata*/
seed =1; /*set seed to make this example reproducible*/
strata grouping_var; /*specify variable to use for stratification*/
run ;
/*view sample*/
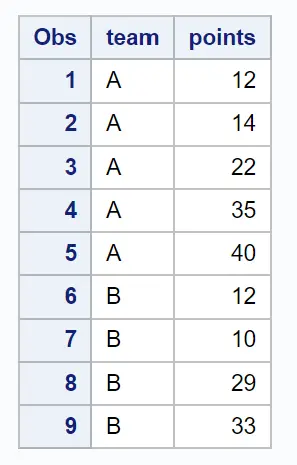
proc print data =my_sample;
결과 샘플에는 각 팀에서 무작위로 선택된 2개의 관측치가 포함됩니다.
관련 항목: 클러스터 샘플링과 계층화된 샘플링: 차이점은 무엇입니까?
예 3: PROC SURVEYSELECT를 사용하여 합동 무작위 표본 선택
다음 구문을 사용하여 팀을 클러스터로 사용하고 무작위로 2개의 클러스터를 선택하고 이러한 클러스터의 각 관측치를 샘플에 포함하는 클러스터형 무작위 샘플링을 수행할 수 있습니다.
proc surveyselect data =my_data
out =my_sample
n =2 /*select a total of 2 clusters*/
seed =1; /*set seed to make this example reproducible*/
clustergrouping_var ; /*specify variable to use for clustering*/
run ;
/*view sample*/
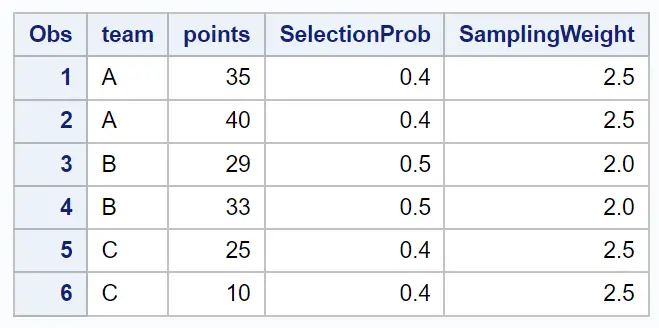
proc print data =my_sample;
이 특정 샘플에는 무작위로 선택된 두 “클러스터”인 팀 A와 B의 모든 관측치가 포함되어 있습니다.
참고 : 여기에서 전체 PROC SURVEYSELECT 설명서를 찾을 수 있습니다.
추가 리소스
다음 튜토리얼에서는 SAS에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
SAS에서 기술 통계를 계산하는 방법
SAS에서 빈도표를 만드는 방법
SAS에서 백분위수를 계산하는 방법
SAS에서 피벗 테이블을 만드는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기