Anova 가정을 확인하는 방법
일원 분산 분석 (one-way ANOVA)은 세 개 이상의 독립 그룹의 평균 간에 유의미한 차이가 있는지 여부를 확인하는 데 사용되는 통계 테스트입니다.
다음은 일원 분산 분석을 사용할 수 있는 경우의 예입니다.
90명의 학생으로 구성된 학급을 무작위로 30명의 세 그룹으로 나눕니다. 각 그룹은 한 달 동안 서로 다른 학습 방법을 사용하여 시험을 준비합니다. 월말에는 모든 학생이 동일한 시험을 치릅니다.
학습 방법이 시험 점수에 영향을 미치는지 여부를 알고 싶습니다. 따라서 일원 분산 분석을 수행하여 세 그룹의 평균 점수 간에 통계적으로 유의미한 차이가 있는지 확인합니다.
일원 분산 분석을 수행하려면 먼저 세 가지 가정이 충족되는지 확인해야 합니다.
1. 정규성 – 각 표본은 정규 분포 모집단에서 추출되었습니다.
2. 등분산 – 표본을 추출하는 모집단의 분산이 동일합니다.
3. 독립성 – 각 그룹 내의 관측치는 서로 독립적이며 그룹 내의 관측치는 무작위 샘플링을 통해 얻어졌습니다.
이러한 가정이 충족되지 않으면 일원 분산 분석의 결과가 신뢰할 수 없을 수 있습니다.
이 글에서는 이러한 가정을 확인하는 방법과 그 중 하나라도 위반되면 어떻게 해야 하는지 설명합니다.
가정 #1: 정규성
ANOVA는 각 표본이 정규 분포 모집단에서 추출되었다고 가정합니다.
R에서 이 가설을 확인하는 방법:
이 가설을 검증하기 위해 두 가지 접근 방식을 사용할 수 있습니다.
- 히스토그램이나 QQ 플롯을 사용하여 가설을 시각적으로 검증합니다.
- Shapiro-Wilk, Kolmogorov-Smironov, Jarque-Barre 또는 D’Agostino-Pearson과 같은 공식 통계 테스트를 사용하여 가설을 검증합니다.
예를 들어, 한 달 동안 프로그램 A, 프로그램 B 또는 프로그램 C를 따르도록 무작위로 30명을 할당하는 체중 감량 실험에 참가하기 위해 90명을 모집한다고 가정합니다. 프로그램이 체중 감량에 영향을 미치는지 확인하기 위해 일원 분산 분석을 수행하려고 합니다. 다음 코드는 히스토그램, QQ 플롯 및 Shapiro-Wilk 테스트를 사용하여 정규성 가정을 확인하는 방법을 보여줍니다.
1. ANOVA 모델을 피팅합니다.
#make this example reproducible
set.seed(0)
#create data frame
data <- data. frame (program = rep(c(" A ", " B ", " C "), each = 30 ),
weight_loss = c(runif(30, 0, 3),
runif(30, 0, 5),
runif(30, 1, 7)))
#fit the one-way ANOVA model
model <- aov(weight_loss ~ program, data = data)
2. 반응 값의 히스토그램을 만듭니다.
#create histogram
hist(data$weight_loss)
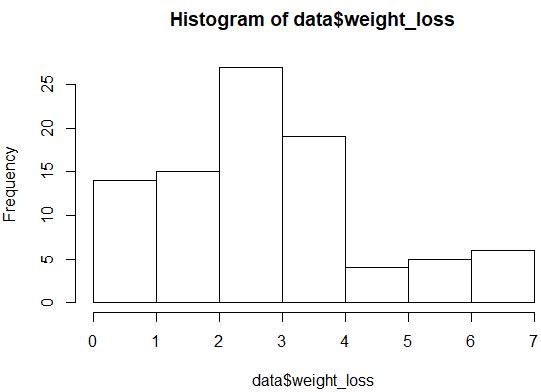
분포는 정규 분포처럼 보이지 않지만(예: “종” 모양이 아님) 분포를 다시 살펴보기 위해 QQ 플롯을 만들 수도 있습니다.
3. 잔차의 QQ 플롯 생성
#create QQ plot to compare this dataset to a theoretical normal distribution qqnorm(model$residuals) #add straight diagonal line to plot qqline(model$residuals)
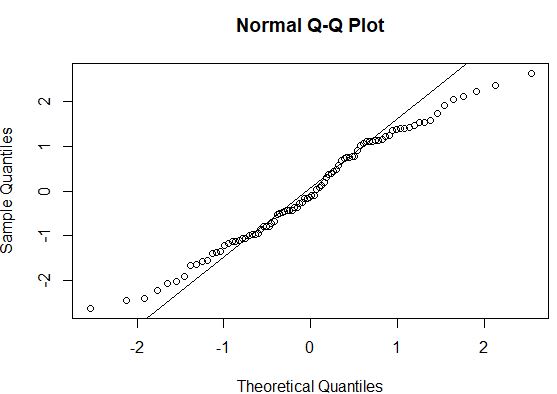
일반적으로 데이터 포인트가 QQ 플롯에서 직선 대각선을 따라 있는 경우 데이터 세트는 정규 분포를 따를 가능성이 높습니다. 이 경우 끝을 따라 선에서 눈에 띄는 편차가 있는 것을 볼 수 있는데, 이는 데이터가 정규 분포를 따르지 않음을 나타낼 수 있습니다.
4. 정규성을 확인하기 위해 Shapiro-Wilk 테스트를 수행합니다.
#Conduct Shapiro-Wilk Test for normality shapiro. test (data$weight_loss) #Shapiro-Wilk normality test # #data: data$weight_loss #W = 0.9587, p-value = 0.005999
Shapiro-Wilk 검정은 표본이 정규 분포에서 나오지 않는다는 대립 가설에 대해 표본이 정규 분포에서 나온다는 귀무 가설을 테스트합니다. 이 경우 테스트의 p-값은 0.005999 로 알파 수준인 0.05보다 낮습니다. 이는 표본이 정규 분포를 따르지 않는다는 것을 의미합니다.
이 가정이 존중되지 않으면 어떻게 해야 할까요?
일반적으로 일원 분산 분석은 표본 크기가 충분히 크면 정규성 가정 위반에 대해 상당히 견고한 것으로 간주됩니다.
또한 매우 큰 샘플이 있는 경우 Shapiro-Wilk 테스트와 같은 통계 테스트는 거의 항상 데이터가 정규적이지 않다는 것을 알려줍니다. 이러한 이유로 히스토그램, QQ 플롯과 같은 차트를 사용하여 데이터를 시각적으로 검사하는 것이 가장 좋은 경우가 많습니다. 그래프만 봐도 데이터가 정규 분포를 이루고 있는지 아닌지를 꽤 잘 알 수 있습니다.
정규성 가정이 심각하게 위반되거나 매우 보수적으로 적용하려는 경우 두 가지 선택이 있습니다.
(1) 분포가 보다 정규 분포를 따르도록 데이터의 반응 값을 변환합니다.
(2) 정규성 가정이 필요하지 않은 Kruskal-Wallis 테스트 와 같은 동등한 비모수 테스트를 수행합니다.
가정 #2: 등분산
ANOVA는 표본을 추출한 모집단의 분산이 동일하다고 가정합니다.
R에서 이 가설을 확인하는 방법:
우리는 두 가지 접근법을 사용하여 R에서 이 가설을 검증할 수 있습니다.
- 상자 그림을 사용하여 가설을 시각적으로 검증합니다.
- Bartlett의 검정과 같은 공식적인 통계 검정을 사용하여 가설을 검정합니다.
다음 코드는 이전에 생성한 것과 동일한 가짜 체중 감량 데이터 세트를 사용하여 이를 수행하는 방법을 보여줍니다.
1. 상자 그림을 만듭니다.
#Create box plots that show distribution of weight loss for each group boxplot(weight_loss ~ program, xlab=' Program ', ylab=' Weight Loss ', data=data)
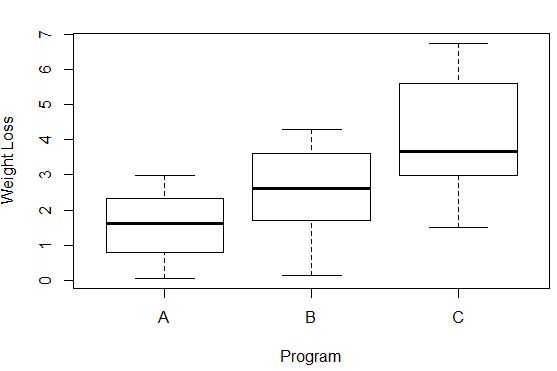
각 그룹의 체중 감소 차이는 각 상자 그림의 길이를 통해 관찰할 수 있습니다. 상자가 길수록 분산이 높아집니다. 예를 들어, 프로그램 A 및 프로그램 B에 비해 프로그램 C 참가자의 차이가 약간 더 높다는 것을 알 수 있습니다.
2. Bartlett 테스트를 수행합니다.
#Create box plots that show distribution of weight loss for each group bartlett. test (weight_loss ~ program, data=data) #Bartlett test of homogeneity of variances # #data: weight_loss by program #Bartlett's K-squared = 8.2713, df = 2, p-value = 0.01599
Bartlett 검정은 표본의 분산이 동일하지 않다는 대립 가설에 대해 표본의 분산이 동일하다는 귀무가설을 테스트합니다. 이 경우 검정의 p-값은 0.01599 로 알파 수준인 0.05보다 낮습니다. 이는 표본의 분산이 모두 동일하지 않음을 나타냅니다.
이 가정이 존중되지 않으면 어떻게 해야 할까요?
일반적으로 일원 분산 분석은 각 그룹이 동일한 표본 크기를 갖는 한 등분산 가정을 위반하는 경우 상당히 견고한 것으로 간주됩니다.
그러나 표본 크기가 동일하지 않고 이 가정이 심각하게 위반되는 경우 대신 일원 분산 분석의 비모수적 버전인 Kruskal-Wallis 검정을 실행할 수 있습니다.
가정 #3: 독립성
ANOVA는 다음을 가정합니다.
- 각 그룹의 관측치는 다른 모든 그룹의 관측치와 독립적입니다.
- 각 그룹 내의 관찰은 무작위 표본을 통해 얻어졌습니다.
이 가설을 검증하는 방법:
각 그룹의 관측치가 독립적이고 무작위 표본을 통해 얻은 것인지 확인하는 데 사용할 수 있는 공식적인 테스트는 없습니다. 이 가정을 만족시키는 유일한 방법은 무작위 설계를 사용하는 것입니다.
이 가정이 존중되지 않으면 어떻게 해야 할까요?
불행하게도 이 가정이 충족되지 않으면 할 수 있는 일이 많지 않습니다. 간단히 말해서, 각 그룹의 관측값이 다른 그룹의 관측값과 독립적이지 않은 방식으로 데이터가 수집되었거나 각 그룹 내의 관측값이 무작위 프로세스에 의해 얻어지지 않은 경우 ANOVA 결과는 신뢰할 수 없습니다. .
이 가정이 충족되지 않는 경우 가장 좋은 방법은 무작위 설계를 사용하여 실험을 재현하는 것입니다.
추가 자료:
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기