R에서 dunnett의 테스트를 수행하는 방법
사후 테스트는 어떤 그룹 평균이 서로 통계적으로 유의하게 다른지 확인하기 위해 ANOVA 에 따라 수행되는 테스트 유형입니다.
연구 그룹 중 하나가 대조군으로 간주되는 경우 Dunnett의 테스트를 사후 테스트로 사용해야 합니다.
이 튜토리얼에서는 R에서 Dunnett 테스트를 수행하는 방법을 설명합니다.
예: R의 Dunnett 테스트
교사가 두 가지 새로운 학습 기술이 학생의 시험 점수를 향상시킬 수 있는 잠재력이 있는지 알고 싶어한다고 가정해 보겠습니다. 이를 테스트하기 위해 그녀는 30명의 학생으로 구성된 학급을 무작위로 다음 세 그룹으로 나눕니다.
- 통제그룹: 학생 10명
- 신규기술연구1:10명
- 새로운 기술 연구 2: 학생 10명
일주일 동안 할당된 학습 방법을 사용한 후 각 학생은 동일한 시험을 치릅니다.
R에서 다음 단계를 사용하여 데이터 세트를 생성하고, 그룹 평균을 시각화하고, 일원 분산 분석을 수행하고, 마지막으로 Dunnett의 테스트를 수행하여 어떤 새로운 연구 기법(있는 경우)이 대조군과 비교하여 다른 결과를 생성하는지 확인할 수 있습니다. .
1단계: 데이터세트를 만듭니다.
다음 코드는 학생 30명 모두의 시험 결과가 포함된 데이터 세트를 생성하는 방법을 보여줍니다.
#create data frame data <- data.frame(technique = rep (c("control", "new1", "new2"), each = 10 ), score = c(76, 77, 77, 81, 82, 82, 83, 84, 85, 89, 81, 82, 83, 83, 83, 84, 87, 90, 92, 93, 77, 78, 79, 88, 89, 90, 91, 95, 95, 98)) #view first six rows of data frame head(data) technical score 1 control 76 2 controls 77 3 controls 77 4 controls 81 5 controls 82 6 controls 82
2단계: 각 그룹의 시험 결과를 봅니다.
다음 코드는 각 그룹의 시험 결과 분포를 시각화하기 위해 상자 그림을 생성하는 방법을 보여줍니다.
boxplot(score ~ technique,
data = data,
main = "Exam Scores by Studying Technique",
xlab = "Studying Technique",
ylab = "Exam Scores",
col = "steelblue",
border = "black")
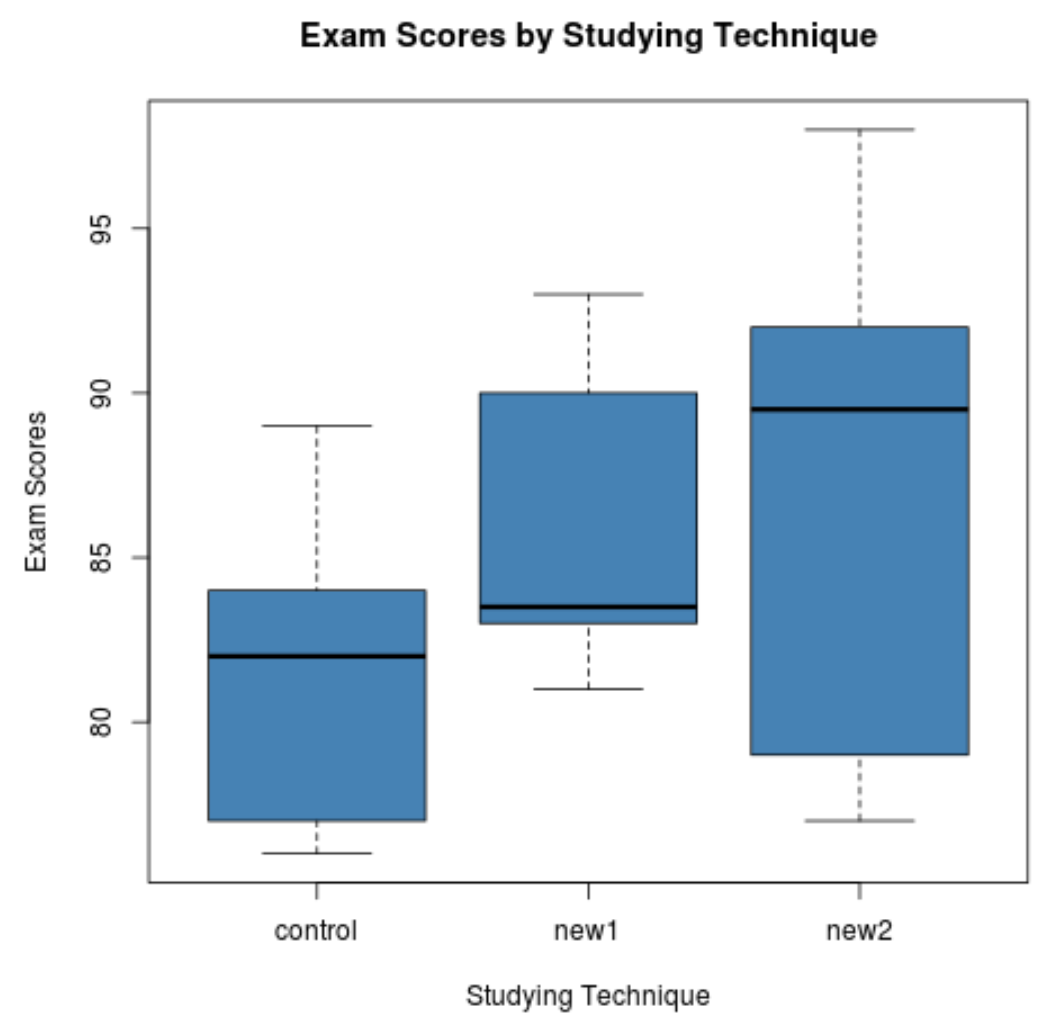
상자 그림을 보면 시험 점수 분포가 각 학습 방법마다 매우 다르다는 것을 알 수 있습니다. 그런 다음 일원 분산 분석을 수행하여 이러한 차이가 통계적으로 유의한지 확인합니다.
관련 항목: R의 단일 차트에 여러 상자 그림을 그리는 방법
3단계: 일원 분산 분석을 수행합니다.
다음 코드는 일원 분산 분석을 수행하여 각 그룹의 평균 시험 점수 간의 차이를 테스트하는 방법을 보여줍니다.
#fit the one-way ANOVA model model <- aov(score ~ technique, data = data) #view model output summary(model) Df Sum Sq Mean Sq F value Pr(>F) technical 2 211.5 105.73 3.415 0.0476 * Residuals 27 836.0 30.96 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
전체 p-값( 0.0476 )이 0.05보다 작으므로 이는 각 그룹의 평균 시험 점수가 동일하지 않음을 나타냅니다. 다음으로 Dunnett 테스트를 수행하여 어떤 학습 기법이 대조군과 다른 평균 시험 점수를 생성하는지 확인합니다.
4단계: Dunnett 테스트를 수행합니다.
R에서 Dunnett 테스트를 수행하려면 다음 구문을 사용하는 DescTools 라이브러리의 DunnettTest() 함수를 사용할 수 있습니다.
던넷 테스트(x, g)
금:
- x: 데이터 값의 숫자형 벡터(예: 시험 결과)
- g: 그룹의 이름을 지정하는 벡터(예: 연구 기법)
다음 코드는 예제에서 이 함수를 사용하는 방법을 보여줍니다.
#load DescTools library library(DescTools) #perform Dunnett's Test DunnettTest(x=data$score, g=data$technique) Dunnett's test for comparing several treatments with a control: 95% family-wise confidence level $control diff lwr.ci upr.ci pval new1-control 4.2 -1.6071876 10.00719 0.1787 new2-control 6.4 0.5928124 12.20719 0.0296 * --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1' '1.' 0.1 ' ' 1
결과를 해석하는 방법은 다음과 같습니다.
- 새로운 학습법 1과 대조군 간의 시험 점수의 평균 차이는 4.2입니다. 해당 p-값은 0.1787 입니다.
- 새로운 학습법 2와 대조군 간의 시험 점수의 평균 차이는 6.4입니다. 해당 p-값은 0.0296 입니다.
결과에 따르면 기법 2를 공부하는 것이 대조군과 크게(p = 0.0296) 다른 평균 시험 점수를 생성하는 유일한 기법이라는 것을 알 수 있습니다.
추가 리소스
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기