R에서 데이터를 변환하는 방법(로그, 제곱근, 세제곱근)
많은 통계 검정에서는 반응 변수 의 잔차가 정규 분포를 따른다고 가정합니다.
그러나 잔차는 정규 분포를 따르지 않는 경우가 많습니다. 이 문제를 해결하는 한 가지 방법은 다음 세 가지 변환 중 하나를 사용하여 응답 변수를 변환하는 것입니다.
1. 로그 변환: 응답 변수를 y에서 log(y) 로 변환합니다.
2. 제곱근 변환: 응답 변수를 y에서 √y 로 변환합니다.
3. 세제곱근 변환: 응답 변수를 y에서 y 1/3 으로 변환합니다.
이러한 변환을 수행하면 반응 변수는 일반적으로 정규 분포에 가까워집니다. 다음 예에서는 R에서 이러한 변환을 수행하는 방법을 보여줍니다.
R의 로그 변환
다음 코드는 응답 변수에 대한 로그 변환을 수행하는 방법을 보여줍니다.
#create data frame df <- data.frame(y=c(1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 6, 7, 8), x1=c(7, 7, 8, 3, 2, 4, 4, 6, 6, 7, 5, 3, 3, 5, 8), x2=c(3, 3, 6, 6, 8, 9, 9, 8, 8, 7, 4, 3, 3, 2, 7)) #perform log transformation log_y <- log10(df$y)
다음 코드는 로그 변환을 수행하기 전과 후에 y 의 분포를 표시하기 위해 히스토그램을 만드는 방법을 보여줍니다.
#create histogram for original distribution hist(df$y, col='steelblue', main='Original') #create histogram for log-transformed distribution hist(log_y, col='coral2', main='Log Transformed')
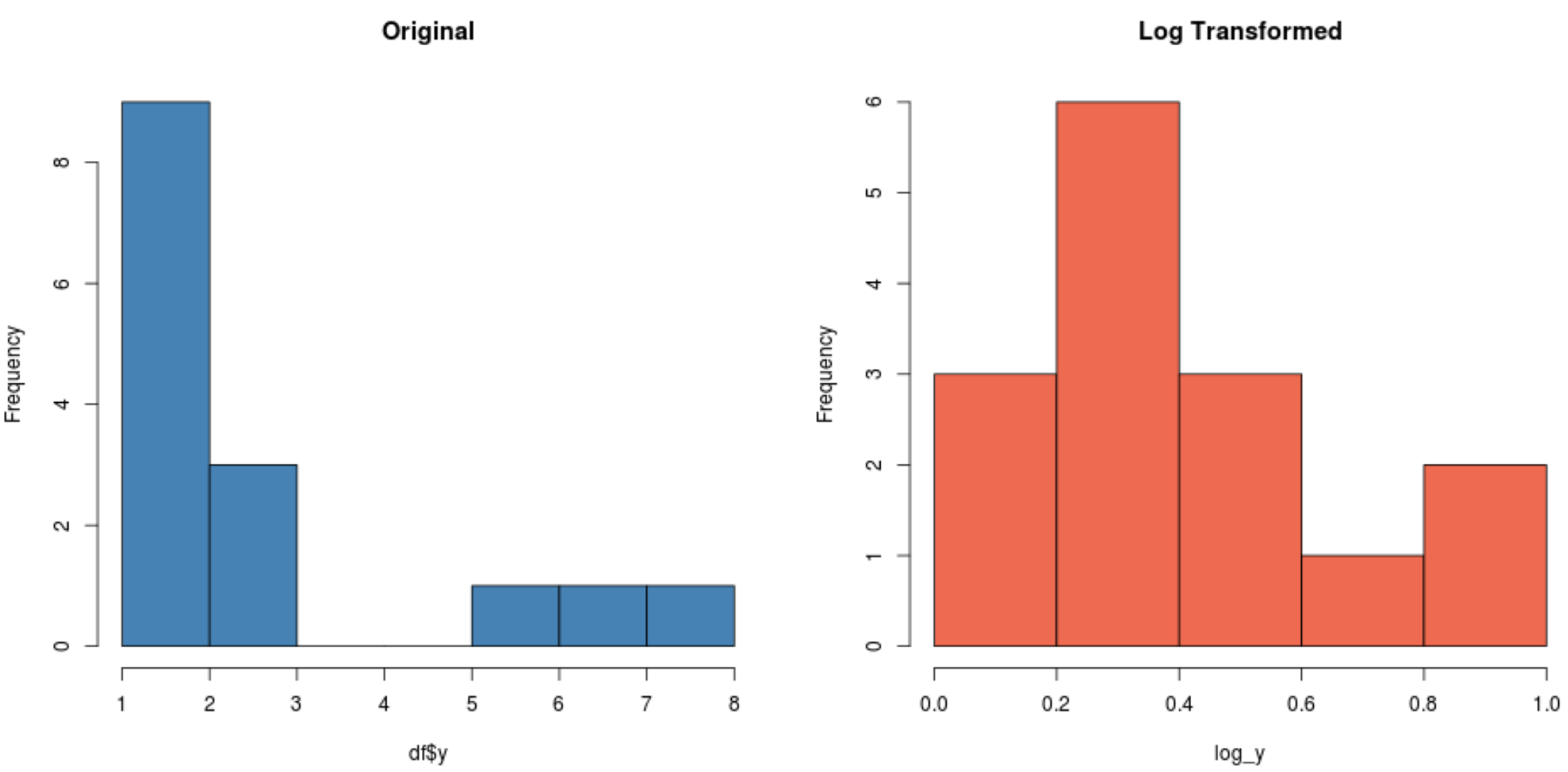
로그 변환된 분포가 원래 분포보다 훨씬 더 정규적인지 확인하세요. 여전히 완벽한 “종 모양”은 아니지만 원래 분포보다 정규 분포에 더 가깝습니다.
실제로 각 분포에 대해 Shapiro-Wilk 테스트를 수행하면 원래 분포는 정규성 가정에 실패하지만 로그 변환된 분포는 그렇지 않습니다(α = 0.05에서).
#perform Shapiro-Wilk Test on original data shapiro.test(df$y) Shapiro-Wilk normality test data: df$y W = 0.77225, p-value = 0.001655 #perform Shapiro-Wilk Test on log-transformed data shapiro.test(log_y) Shapiro-Wilk normality test data:log_y W = 0.89089, p-value = 0.06917
R의 제곱근 변환
다음 코드는 응답 변수에 대해 제곱근 변환을 수행하는 방법을 보여줍니다.
#create data frame df <- data.frame(y=c(1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 6, 7, 8), x1=c(7, 7, 8, 3, 2, 4, 4, 6, 6, 7, 5, 3, 3, 5, 8), x2=c(3, 3, 6, 6, 8, 9, 9, 8, 8, 7, 4, 3, 3, 2, 7)) #perform square root transformation sqrt_y <- sqrt(df$y)
다음 코드는 제곱근 변환을 수행하기 전과 후에 y 의 분포를 표시하기 위해 히스토그램을 만드는 방법을 보여줍니다.
#create histogram for original distribution hist(df$y, col='steelblue', main='Original') #create histogram for square root-transformed distribution hist(sqrt_y, col='coral2', main='Square Root Transformed')
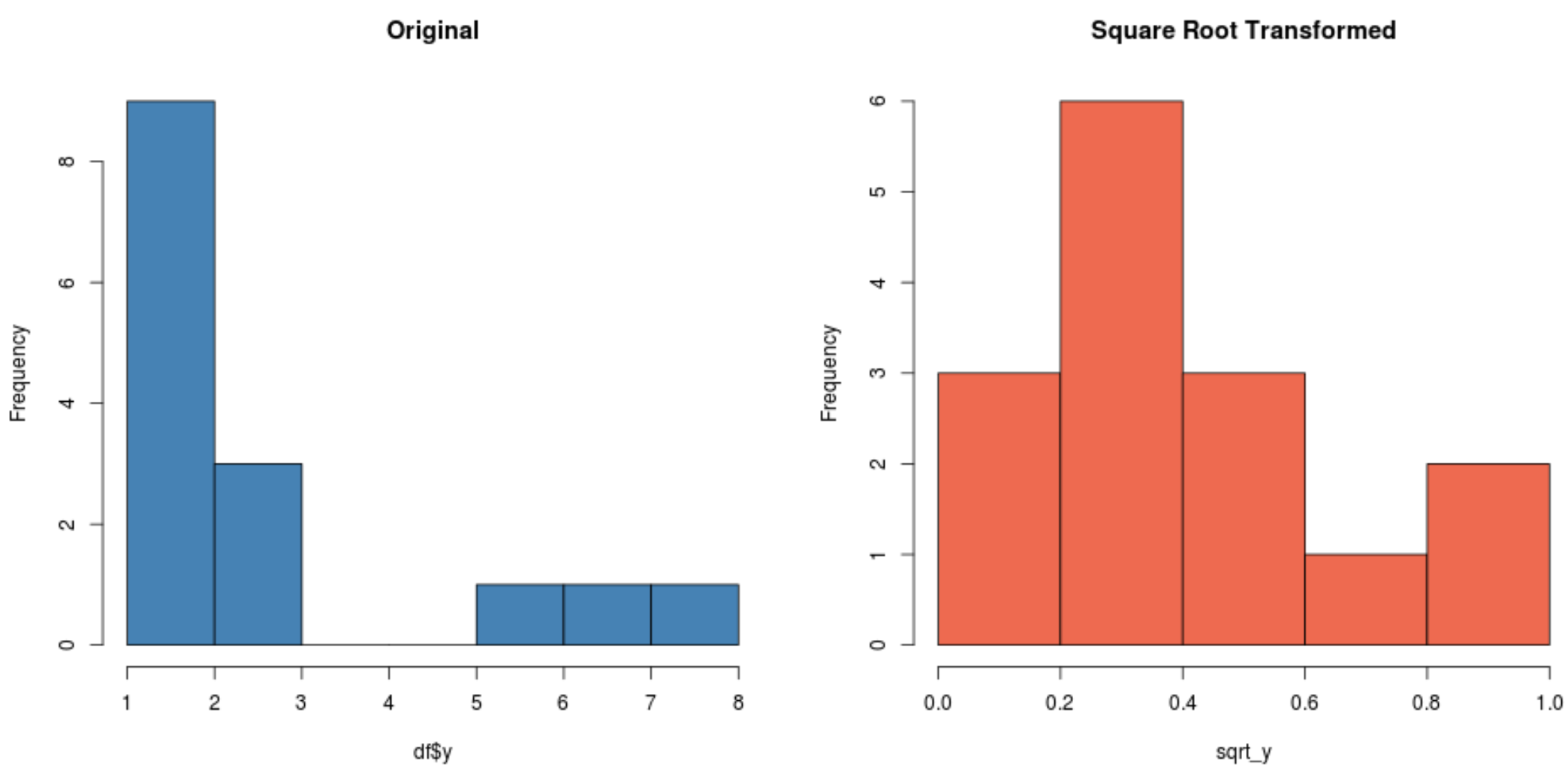
제곱근 변환 분포가 원래 분포보다 훨씬 정규 분포를 따르는지 확인하세요.
R의 세제곱근 변환
다음 코드는 응답 변수에 대해 큐브 루트 변환을 수행하는 방법을 보여줍니다.
#create data frame df <- data.frame(y=c(1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 6, 7, 8), x1=c(7, 7, 8, 3, 2, 4, 4, 6, 6, 7, 5, 3, 3, 5, 8), x2=c(3, 3, 6, 6, 8, 9, 9, 8, 8, 7, 4, 3, 3, 2, 7)) #perform square root transformation cube_y <- df$y^(1/3)
다음 코드는 제곱근 변환을 수행하기 전과 후에 y 의 분포를 표시하기 위해 히스토그램을 만드는 방법을 보여줍니다.
#create histogram for original distribution hist(df$y, col='steelblue', main='Original') #create histogram for square root-transformed distribution hist(cube_y, col='coral2', main='Cube Root Transformed')
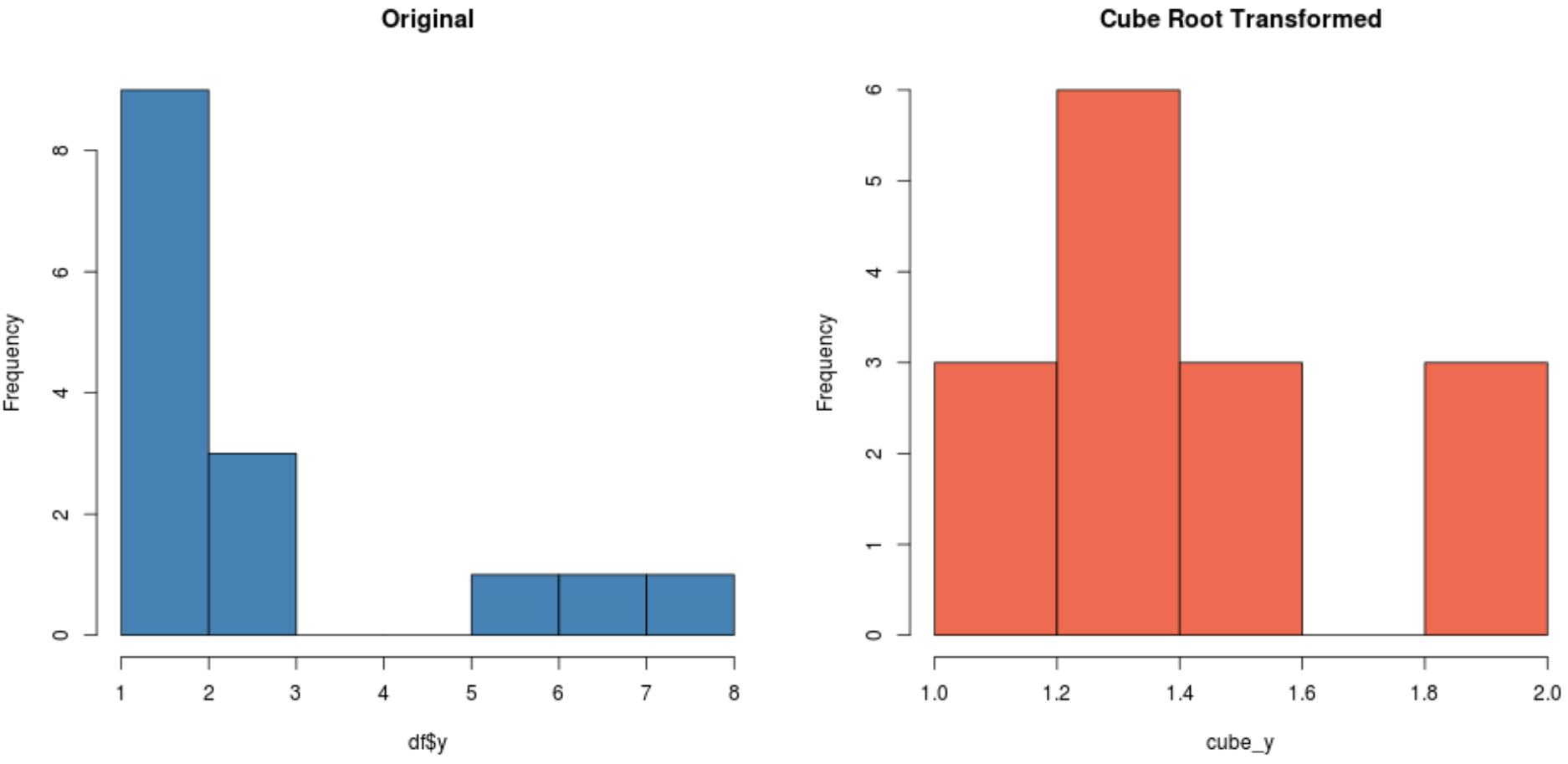
데이터세트에 따라 이러한 변환 중 하나가 다른 변환보다 정규 분포가 더 높은 새 데이터세트를 생성할 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기