양성 예측 값 대 민감도: 차이점은 무엇입니까?
분류 모델 의 성능을 평가하는 가장 일반적인 방법 중 하나는 데이터 세트의 실제 결과에 대해 모델의 예측 결과를 요약하는 혼동 행렬을 만드는 것입니다.
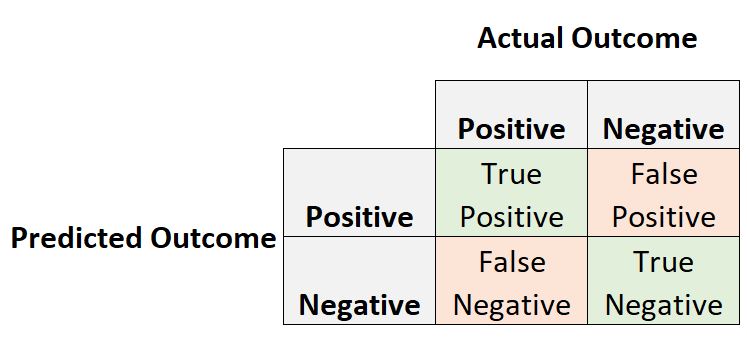
혼동 행렬에서 자주 관심을 갖는 두 가지 지표는 긍정적 예측 값 과 민감도 입니다.
긍정적 예측 값은 긍정적 예측 결과가 있는 관찰이 실제로 긍정적 결과를 가질 확률입니다.
다음과 같이 계산됩니다.
양성 예측 값 = 참양성 / (참양성 + 거짓양성)

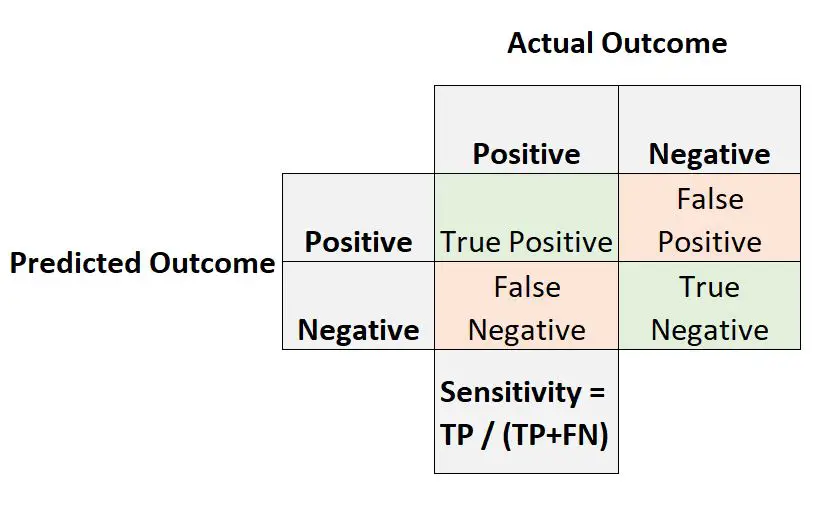
민감도 는 긍정적인 결과를 가진 관찰이 실제로 긍정적인 예측 결과를 가질 확률입니다.
다음과 같이 계산됩니다.
민감도 = 참양성 / (참양성 + 거짓음성)
다음 예에서는 실제로 이러한 두 측정항목을 계산하는 방법을 보여줍니다.
예: 양성 예측값 및 민감도 계산
의사가 로지스틱 회귀 모델을 사용하여 400명의 사람이 특정 질병에 걸렸는지 여부를 예측한다고 가정해 보겠습니다.
다음 혼동 행렬은 모델의 예측을 요약합니다.
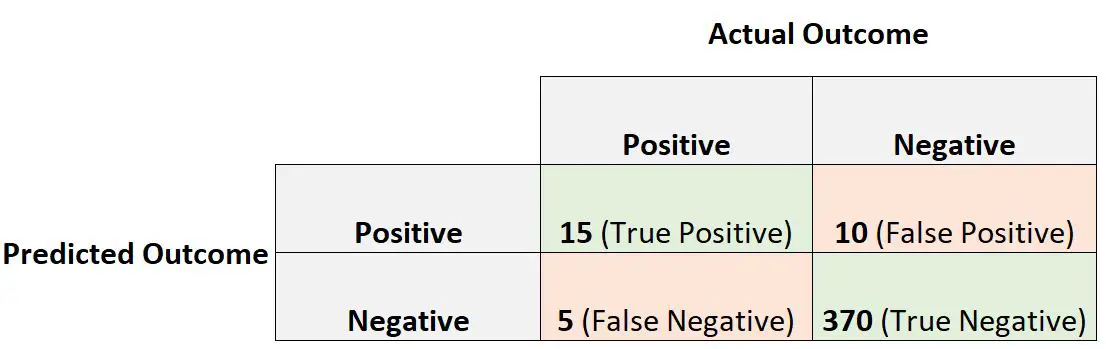
양성 예측 값은 다음과 같이 계산됩니다.
- 양성 예측 값 = 참양성 / (참양성 + 거짓양성)
- 양성 예측 값 = 15 / (15 + 10)
- 양성 예측 값 = 0.60
이는 양성 검사 결과를 받은 사람이 실제로 질병 에 걸렸을 확률이 0.60 이라는 것을 말해줍니다.
민감도 를 다음과 같이 계산합니다.
- 민감도 = 참양성 / (참양성 + 거짓음성)
- 민감도 = 15 / (15 + 5)
- 감도 = 0.75
이는 질병에 걸린 사람이 실제로 양성 검사 결과를 받을 확률이 0.75 라는 것을 말해줍니다.
추가 리소스
다음 튜토리얼에서는 다양한 통계 소프트웨어에서 혼동 행렬을 만드는 방법을 설명합니다.
Excel에서 혼동 행렬을 만드는 방법
R에서 혼동 행렬을 만드는 방법
Python에서 혼동 행렬을 만드는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기