Python에서 box-cox 변환을 수행하는 방법
박스콕스 변환(box-cox 변환)은 비정규 분포 데이터 세트를 보다 정규 분포된 세트로 변환하는 데 일반적으로 사용되는 방법입니다.
이 방법의 기본 아이디어는 다음 공식을 사용하여 변환된 데이터가 정규 분포에 최대한 가깝도록 λ 값을 찾는 것입니다.
- y(λ) = (y λ – 1) / y ≠ 0인 경우 λ
- y(λ) = log(y) y = 0인 경우
scipy.stats.boxcox() 함수를 사용하여 Python에서 box-cox 변환을 수행할 수 있습니다.
다음 예에서는 이 기능을 실제로 사용하는 방법을 보여줍니다.
예: Python의 Box-Cox 변환
지수 분포 에서 1000개의 값으로 구성된 무작위 세트를 생성한다고 가정합니다.
#load necessary packages import numpy as np from scipy. stats import boxcox import seaborn as sns #make this example reproducible n.p. random . seeds (0) #generate dataset data = np. random . exponential (size= 1000 ) #plot the distribution of data values sns. distplot (data, hist= False , kde= True )
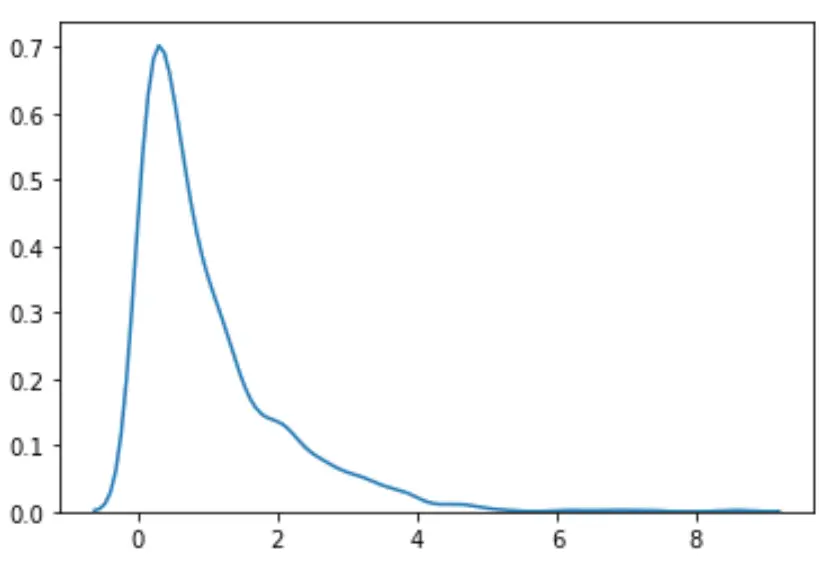
분포가 정상적으로 보이지 않는 것을 볼 수 있습니다.
boxcox() 함수를 사용하여 보다 정규 분포를 생성하는 최적의 람다 값을 찾을 수 있습니다.
#perform Box-Cox transformation on original data transformed_data, best_lambda = boxcox(data) #plot the distribution of the transformed data values sns. distplot (transformed_data, hist= False , kde= True )
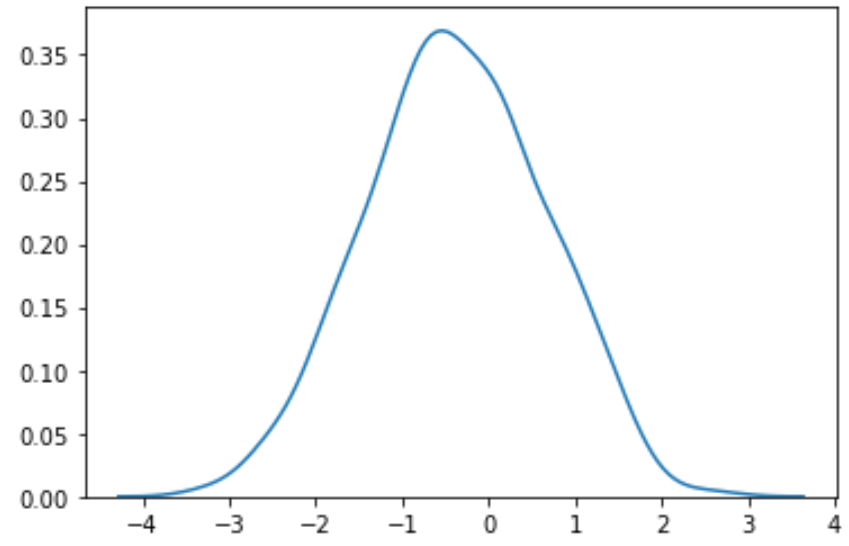
변환된 데이터가 훨씬 더 정규 분포를 따르는 것을 볼 수 있습니다.
Box-Cox 변환을 수행하는 데 사용된 정확한 람다 값도 찾을 수 있습니다.
#display optimal lambda value print (best_lambda) 0.2420131978174143
최적의 람다는 약 0.242 인 것으로 나타났습니다.
따라서 각 데이터 값은 다음 방정식을 사용하여 변환되었습니다.
새 = (기존 0.242 – 1) / 0.242
원본 데이터와 변환된 데이터의 값을 보면 이를 확인할 수 있습니다.
#view first five values of original dataset data[0:5] array([0.79587451, 1.25593076, 0.92322315, 0.78720115, 0.55104849]) #view first five values of transformed dataset transformed_data[0:5] array([-0.22212062, 0.23427768, -0.07911706, -0.23247555, -0.55495228])
원본 데이터세트의 첫 번째 값은 0.79587 입니다. 따라서 이 값을 변환하기 위해 다음 공식을 적용했습니다.
신규 = (.79587 0.242 – 1) / 0.242 = -0.222
변환된 데이터세트의 첫 번째 값이 실제로 -0.222 임을 확인할 수 있습니다.
추가 리소스
Python에서 QQ 플롯을 만들고 해석하는 방법
Python에서 Shapiro-Wilk 정규성 테스트를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기