F 분포를 사용하여 신뢰 구간을 만드는 방법
두 모집단의 분산이 동일한지 확인하기 위해 분산 비율 σ 2 1 / σ 2 2 를 계산할 수 있습니다. 여기서 σ 2 1 은 모집단 1의 분산이고 σ 2 2 는 모집단 2의 분산입니다.
실제 모집단 분산 비율을 추정하기 위해 일반적으로 각 모집단에서 단순 무작위 표본을 추출하여 표본 분산 비율 s 1 2 / s 2 2 를 계산합니다. 여기서 s 1 2 및 s 2 2 는 표본 1과 표본의 표본 분산입니다. . 2, 각각.
이 검정에서는 s 1 2 및 s 2 2 가 정규 분포 모집단에서 추출된 n 1 및 n 2 크기의 독립 표본에서 계산된다고 가정합니다.
이 비율이 1에서 멀어질수록 모집단 내 분산이 불평등하다는 증거가 더 강해집니다.
σ 2 1 / σ 2 2 에 대한 (1-α)100% 신뢰구간은 다음과 같이 정의됩니다.
(s 1 2 / s 2 2 ) * F n 1 -1, n 2 -1, α/2 ≤ σ 2 1 / σ 2 2 ≤ (s 1 2 / s 2 2 ) * F n 2 -1, n 1 -1, α/2
여기서 F n 2 -1, n 1 -1, α/2 및 F n 1 -1, n 2 -1, α/2 선택한 유의 수준 α에 대한 분포 F의 임계 값입니다.
다음 예에서는 세 가지 다른 방법을 사용하여 σ 2 1 / σ 2 2 에 대한 신뢰 구간을 만드는 방법을 보여줍니다.
- 손으로
- 마이크로소프트 엑셀을 사용하세요
- R 통계 소프트웨어 사용
다음 각 예에 대해 다음 정보를 사용합니다.
- α = 0.05
- n 1 = 16
- n2 = 11
- 초 1 2 =28.2
- 초 2 2 = 19.3
신뢰 구간을 수동으로 생성
σ 2 1 / σ 2 2 에 대한 신뢰 구간을 수동으로 계산하려면, 우리가 가지고 있는 숫자를 신뢰 구간 공식에 연결하기만 하면 됩니다.
(s 1 2 / s 2 2 ) * F n1-1, n2-1,α/2 ≤ σ 2 1 / σ 2 2 ≤ (s 1 2 / s 2 2 ) * F n2-1, n1-1, α/2
우리가 누락한 유일한 숫자는 중요한 값입니다. 다행히도 분포 테이블 F 에서 이러한 중요한 값을 찾을 수 있습니다.
Fn2-1, n1-1, α/2 = F10 , 15, 0.025 = 3.0602
F n1-1, n2-1, α/2 = 1/ F 15, 10, 0.025 = 1 / 3.5217 = 0.2839
(클릭하시면 표가 확대됩니다)
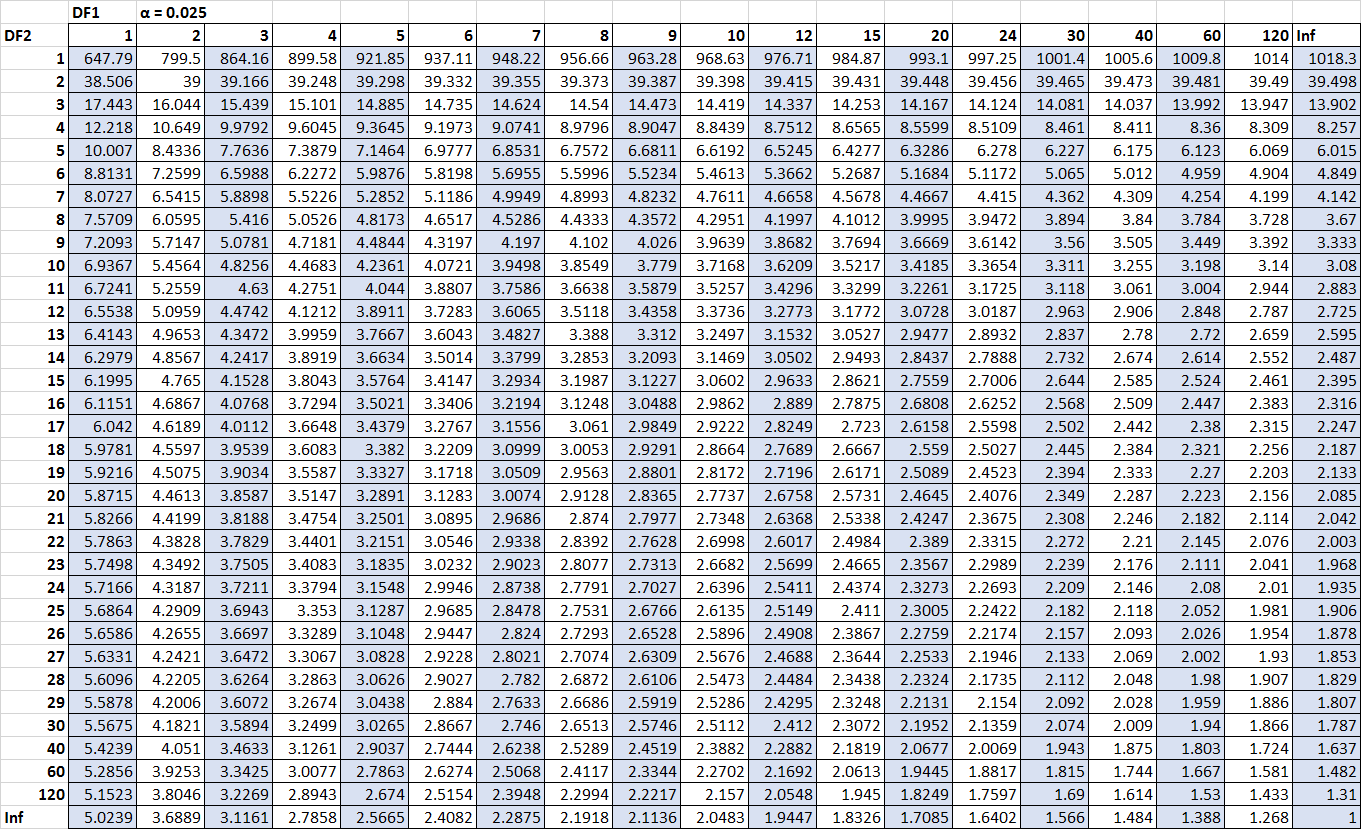
이제 모든 숫자를 신뢰 공식 구간에 연결할 수 있습니다.
(s 1 2 / s 2 2 ) * F n1-1, n2-1,α/2 ≤ σ 2 1 / σ 2 2 ≤ (s 1 2 / s 2 2 ) * F n2-1, n1-1, α/2
(28.2 / 19.3) * (0.2839) ≤ σ 2 1 / σ 2 2 ≤ (28.2 / 19.3) * (3.0602)
0.4148 ≤ σ 2 1 / σ 2 2 ≤ 4.4714
따라서 모집단 분산 비율에 대한 95% 신뢰 구간은 (0.4148, 4.4714) 입니다.
Excel을 사용하여 신뢰 구간 만들기
다음 이미지는 Excel에서 모집단 분산 비율에 대한 95% 신뢰 구간을 계산하는 방법을 보여줍니다. 신뢰 구간의 하한과 상한은 E 열에 표시되고 하한과 상한을 찾는 데 사용되는 공식은 F 열에 표시됩니다.
따라서 모집단 분산 비율에 대한 95% 신뢰 구간은 (0.4148, 4.4714) 입니다. 이는 신뢰 구간을 수동으로 계산할 때 얻은 것과 일치합니다.
R을 사용하여 신뢰 구간 만들기
다음 코드는 R의 모집단 분산 비율에 대한 95% 신뢰 구간을 계산하는 방법을 보여줍니다.
#define significance level, sample sizes, and sample variances alpha <- .05 n1 <- 16 n2 <- 11 var1 <- 28.2 var2 <- 19.3 #define F critical values upper_crit <- 1/qf(alpha/2, n1-1, n2-1) lower_crit <- qf(alpha/2, n2-1, n1-1) #find confidence interval lower_bound <- (var1/var2) * lower_crit upper_bound <- (var1/var2) * upper_crit #output confidence interval paste0("(", lower_bound, ", ", upper_bound, " )") #[1] "(0.414899337980266, 4.47137571035219 )"
따라서 모집단 분산 비율에 대한 95% 신뢰 구간은 (0.4148, 4.4714) 입니다. 이는 신뢰 구간을 수동으로 계산할 때 얻은 것과 일치합니다.
추가 리소스
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기