Sas에서 퍼지 매칭을 수행하는 방법(예제 포함)
불완전하게 일치하는 문자열을 기반으로 SAS에서 두 데이터 세트를 결합하려는 경우가 종종 있습니다.
이를 흔히 퍼지 매칭 이라고 합니다.
SAS에서 퍼지 일치를 수행하는 가장 쉬운 방법은 COMPGED 함수와 함께 SOUNDEX 함수를 사용하는 것입니다.
이 두 함수는 문자열 간의 유사성을 수량화하는 데 사용되며 유사한 문자열을 “일치”하는 데 사용할 수 있습니다.
다음 예에서는 이러한 함수를 사용하여 SAS에서 퍼지 일치를 수행하는 방법을 보여줍니다.
예: SAS에서 퍼지 일치를 수행하는 방법
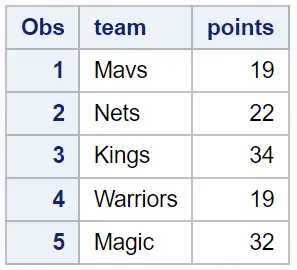
다양한 농구 선수의 팀 이름과 포인트에 대한 정보가 포함된 다음과 같은 데이터세트가 SAS에 있다고 가정해 보겠습니다.
/*create first dataset*/
data data1;
input team $points;
datalines ;
Mavs 19
Nets 22
Kings 34
Warriors 19
Magic 32
;
run ;
/*view dataset*/
proc print data =data1;
그리고 다양한 농구 선수의 팀 이름과 어시스트가 포함된 또 다른 데이터세트가 있다고 가정해 보겠습니다.
/*create second dataset*/
data data2;
input team $assists;
datalines ;
Netts 8
Majick 7
Keengs 8
Warriors 12
Mavs 4
;
run ;
/*view dataset*/
proc print data =data2;
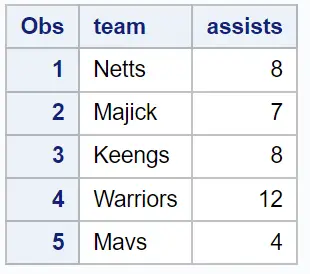
이 데이터 세트의 많은 팀 이름은 유사하지만 이전 데이터 세트의 팀 이름과 정확히 동일하지는 않습니다.
SAS에서 다음 구문을 사용하여 유사 일치를 수행하고 유사한 팀 이름을 기반으로 두 데이터 세트를 함께 가져올 수 있습니다.
/*use fuzzy matching to merge datasets based on similar team names*/ data data3; setdata1 ; tmp1= soundex (team); /*encode team names from data1 */ do i=1 to nobs; set data2( rename =(team=team2)) point =i nobs =nobs; tmp2= soundex (team2); /*encode team names from data2* / dif= compged (tmp1,tmp2); /*determine similarity between team names */ if dif<=50 then do ; drop i tmp1 tmp2 dif; /*dr op unnecessary variables*/ output ; end ; end ; run ; /*view resulting dataset*/ proc print data=data3;
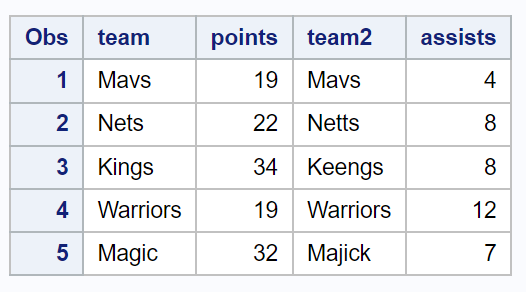
SOUNDEX 및 COMPGED 함수는 유사성을 기준으로 팀 이름을 일치시키고 두 데이터세트를 병합하는 최종 데이터세트를 생성할 수 있습니다.
추가 리소스
다음 튜토리얼에서는 SAS에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
SAS: 일대다 병합을 수행하는 방법
SAS: 병합 문에서 (in=a)를 사용하는 방법
SAS: A가 B가 아닌 경우 병합하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기