Welch의 t 검정: 사용 시기 + 예
두 개의 독립적인 그룹의 평균을 비교하려는 경우 두 가지 다른 테스트 사용 중에서 선택할 수 있습니다.
스튜던트 t-검정: 이 검정은 두 데이터 그룹이 정규 분포를 따르는 모집단에서 샘플링되고 두 모집단의 분산이 동일하다고 가정합니다.
Welch의 t-검정: 이 검정에서는 두 데이터 그룹이 모두 정규 분포를 따르는 모집단에서 샘플링되었다고 가정 하지만 이 두 모집단의 분산이 동일하다고 가정하지는 않습니다 .
Student’s t-test와 Welch’s t-test의 차이점
스튜던트 t-테스트와 Welch의 t-테스트 수행 방법에는 두 가지 차이점이 있습니다.
- 테스트 통계
- 자유도
학생의 t-테스트:
검정 통계량: ( x 1 – x 2 ) / s p (√ 1/n 1 + 1/n 2 )
여기서 x 1 과 x 2 는 표본 평균이고, n 1 과 n 2 는 각각 표본 1과 표본 2에 대한 표본 크기이며, s p 는 다음과 같이 계산됩니다.
s p = √ (n 1 -1)s 1 2 + (n 2 -1)s 2 2 / (n 1 +n 2 -2)
여기서 s 1 2 및 s 2 2 는 표본 분산입니다.
자유도: n 1 + n 2 – 2
웰치의 T-검정
검정 통계량: ( x 1 – x 2 ) / (√ s 1 2 /n 1 + s 2 2 /n 2 )
자유도: (s 1 2 /n 1 + s 2 2 /n 2 ) 2 / { [ (s 1 2 / n 1 ) 2 / (n 1 – 1) ] + [ (s 2 2 / n 2 ) 2 / (n 2 – 1) ] }
Welch의 t-검정의 자유도를 계산하는 공식은 두 표준 편차 간의 차이를 고려합니다. 두 표본의 표준 편차가 동일한 경우 Welch의 t-검정의 자유도는 Student의 t-검정의 자유도와 정확히 동일합니다.
일반적으로 두 표본의 표준 편차는 동일하지 않으므로 Welch의 t-검정의 자유도는 Student의 t-검정의 자유도보다 작은 경향이 있습니다.
Welch의 t-검정의 자유도는 일반적으로 정수가 아니라는 점에 유의하는 것도 중요합니다. 수동으로 테스트하는 경우 가장 낮은 정수로 반올림하는 것이 가장 좋습니다. R 과 같은 통계 소프트웨어를 사용하면 소프트웨어에서 자유도의 십진수 값을 제공할 수 있습니다.
Welch t-검정은 언제 사용해야 합니까?
어떤 사람들은 Welch의 t-검정이 두 독립 그룹의 평균을 비교하기 위한 기본 선택이어야 한다고 주장합니다. 왜냐하면 Welch의 t-검정은 그룹 간에 표본 크기와 분산이 동일하지 않을 때 스튜던트 t-검정보다 더 나은 성능을 발휘하고 표본 크기가 동일할 때 동일한 결과를 제공하기 때문입니다. 다르다. 차이점은 동일합니다.
실제로 두 그룹의 평균을 비교할 때 각 그룹의 표준 편차가 동일할 가능성은 거의 없습니다. 따라서 항상 Welch의 t-검정을 사용하는 것이 좋습니다. 그러면 등분산에 대한 가정을 할 필요가 없습니다.
Welch의 t-검정 사용 예
다음으로 다음 두 표본에 대해 Welch의 t-검정을 수행하여 모집단 평균이 0.05 유의 수준에서 크게 다른지 여부를 확인합니다.
샘플 1: 14, 15, 15, 15, 16, 18, 22, 23, 24, 25, 25
샘플 2: 10, 12, 14, 15, 18, 22, 24, 27, 31, 33, 34, 34, 34
세 가지 방법으로 테스트를 수행하는 방법을 설명하겠습니다.
- 손으로
- 마이크로소프트 엑셀을 사용하세요
- R 통계 프로그래밍 언어 사용
Welch의 T 테스트를 직접 수행
Welch t-검정을 직접 수행하려면 먼저 표본 평균, 표본 분산 및 표본 크기를 찾아야 합니다.
x1 – 19.27
x2 – 23.69
1시 2 분 – 오후 8시 42분
예술 2 2 – 83.23
# 1 – 11
# 2 – 13
그런 다음 다음 숫자를 입력하여 테스트 통계를 찾을 수 있습니다.
검정 통계량: ( x 1 – x 2 ) / (√ s 1 2 /n 1 + s 2 2 /n 2 )
검정 통계량: (19.27 – 23.69) / (√ 20.42/11 + 83.23/13 ) = -4.42 / 2.873 = -1.538
자유도: (s 1 2 /n 1 + s 2 2 /n 2 ) 2 / { [ (s 1 2 / n 1 ) 2 / (n 1 – 1) ] + [ (s 2 2 / n 2 ) 2 / (n 2 – 1) ] }
자유도: (20.42/11 + 83.23/13) 2 / { [ (20.42/11) 2 / (11 – 1) ] + [ (83.23/13) 2 / (13 – 1) ] } = 18.137. 이 결과를 가장 가까운 정수인 18 로 반올림합니다.
마지막으로 18 자유도에 대해 알파 = 0.05인 양면 테스트에 해당하는 t 분포 테이블에서 임계값 t를 찾습니다.
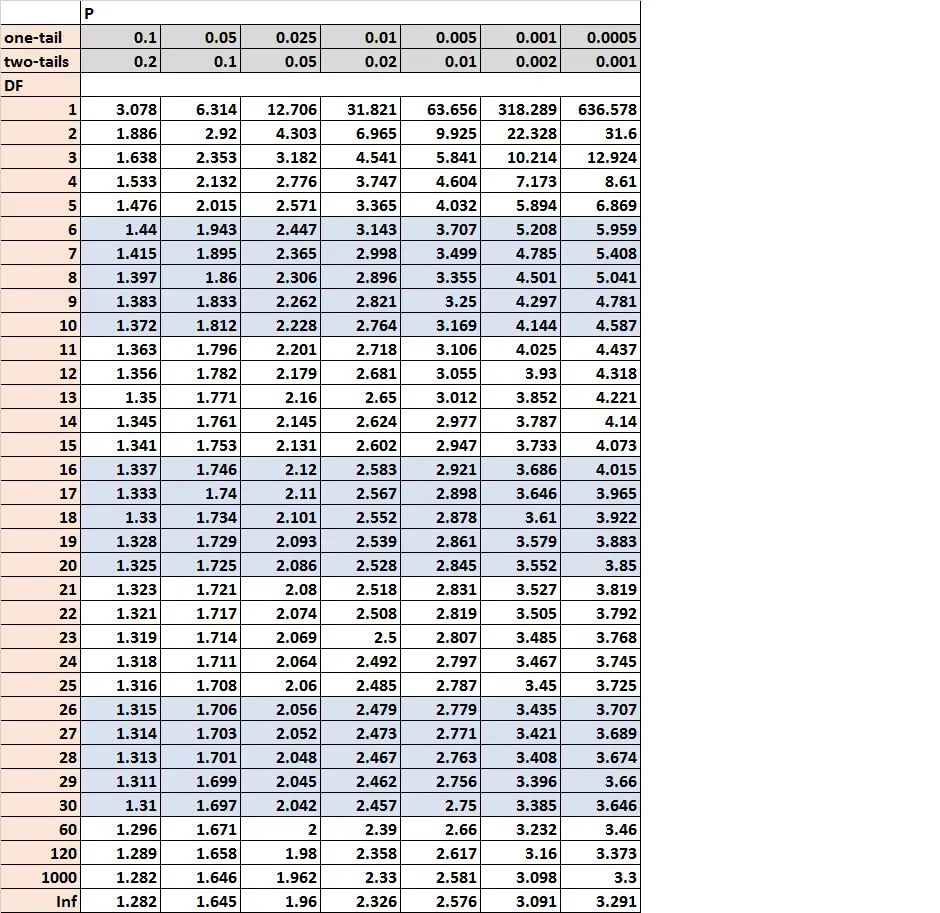
임계값 t는 2.101 입니다. 검정 통계량(1.538)의 절대값이 임계값 t보다 크지 않기 때문에 검정의 귀무가설을 기각할 수 없습니다. 두 모집단의 평균이 크게 다르다고 말할 수 있는 증거가 충분하지 않습니다.
Excel을 사용한 Welch의 T-검정
Excel에서 Welch의 t-검정을 수행하려면 먼저 무료 Analysis ToolPak 소프트웨어를 다운로드해야 합니다. 아직 Excel로 다운로드하지 않으셨다면 다운로드 방법에 대한 간단한 튜토리얼을 작성해 두었습니다.
Analysis ToolPak을 다운로드한 후에는 아래 단계에 따라 두 샘플에 대해 Welch의 t-테스트를 수행할 수 있습니다.
1. 데이터를 입력합니다. A열과 B열에 두 샘플에 대한 데이터 값을 입력하고 각 열의 첫 번째 셀에 Sample 1 과 Sample 2 라는 제목을 입력합니다.
2. Analysis ToolPak을 사용하여 Welch의 t-검정을 수행합니다. 상단 리본에 있는 데이터 탭으로 이동합니다. 그런 다음 분석 그룹에서 분석 도구 아이콘을 클릭합니다.
표시되는 대화 상자에서 t-검정: 두 표본이 동일하지 않은 분산을 가정 하고 확인을 클릭합니다.
마지막으로 아래 값을 입력한 후 확인을 클릭하세요.
다음 결과가 나타나야 합니다.
이 테스트의 결과는 수동으로 얻은 결과와 일치합니다.
- 검정 통계량은 -1.5379 입니다.
- 양측 임계값은 2.1009 입니다.
- 검정 통계량의 절대값이 양측 임계값보다 크지 않으므로 두 모집단의 평균은 통계적으로 다르지 않습니다.
- 또한 검정의 양측 p-값은 0.14로 0.05보다 크고 두 모집단의 평균이 통계적으로 다르지 않음을 확인합니다.
R을 사용한 Welch의 t-검정
다음 코드는 R 통계 프로그래밍 언어를 사용하여 두 샘플에 대해 Welch의 t-테스트를 수행하는 방법을 보여줍니다.
#create two vectors to hold sample data values sample1 <- c(14, 15, 15, 15, 16, 18, 22, 23, 24, 25, 25) sample2 <- c(10, 12, 14, 15, 18, 22, 24, 27, 31, 33, 34, 34, 34) #conduct Welch's test t.test( sample1, sample2) # Welch Two Sample t-test # #data: sample1 and sample2 #t = -1.5379, df = 18.137, p-value = 0.1413 #alternative hypothesis: true difference in means is not equal to 0 #95 percent confidence interval: #-10.453875 1.614714 #sample estimates: #mean of x mean of y #19.27273 23.69231 #
t.test() 함수는 다음과 같은 관련 출력을 표시합니다.
- t: 검정 통계량 = -1.5379
- df : 자유도 = 18.137
- p-값: 양측 검정의 p-값 = 0.1413
- 95% 신뢰구간 : 모집단 평균의 실제 차이에 대한 95% 신뢰구간 = (-10.45, 1.61)
이 테스트의 결과는 Excel을 사용하여 수동으로 얻은 결과와 일치합니다. 이 두 모집단의 평균 차이는 알파 = 0.05 수준에서 통계적으로 유의하지 않습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기