중심 경향 측정: 정의 및 예
중심 경향의 측도는 데이터 세트의 중심점을 나타내는 단일 값입니다. 이 값은 데이터 세트의 “중앙 위치”라고도 합니다.
통계에는 중심 경향에 대한 세 가지 일반적인 측정 방법이 있습니다.
- 평균
- 중앙값
- 패션
이러한 각 측정값은 다양한 방법을 사용하여 데이터 세트의 중앙 위치를 찾습니다. 분석 중인 데이터 유형에 따라 다른 두 가지 지표보다는 이 세 가지 지표 중 하나를 사용하는 것이 더 나을 수도 있습니다.
이 기사에서는 중심 경향의 세 가지 측정값을 각각 계산하는 방법과 데이터를 기반으로 가장 적합한 측정값을 결정하는 방법을 살펴보겠습니다.
중심경향 측정이 유용한 이유는 무엇입니까?
평균, 중앙값, 최빈값을 계산하는 방법을 살펴보기 전에 먼저 이러한 측정값이 실제로 왜 유용한지 이해하는 것이 도움이 됩니다.
다음 시나리오를 고려해보세요.
한 젊은 부부가 새로운 도시에서 첫 집을 어디에서 구입할지 결정하려고 하는데 그들이 지출할 수 있는 최대 금액은 $150,000입니다. 도시의 일부 지역에는 값비싼 주택이 있고, 일부 지역에는 저렴한 주택이 있으며, 일부 지역에는 중간 가격의 주택이 있습니다. 그들은 예산에 맞는 특정 지역으로 검색 범위를 쉽게 좁히고 싶어합니다.
부부가 단지 각 동네의 단독 주택 가격만 살펴본다면 다음과 같은 결과가 나올 수 있기 때문에 자신의 예산에 가장 적합한 동네를 결정하는 데 어려움을 겪을 수 있습니다.
인근 A 주택 가격: $140,000, $190,000, $265,000, $115,000, $270,000, $240,000, $250,000, $180,000, $160,000, $200,000, $240,000, $280,000,…
인근 B 주택 가격: $140,000, $290,000, $155,000, $165,000, $280,000, $220,000, $155,000, $185,000, $160,000, $200,000, $190,000, $140,000, $145.0 0 0,…
인근 C 주택 가격: $140,000, $130,000, $165,000, $115,000, $170,000, $100,000, $150,000, $180,000, $190,000, $120,000, $110,000, $130,000, $120,0 0 0,…
그러나 각 동네 주택의 평균 가격(예: 중심 경향의 척도)을 알고 있다면 어느 동네의 예산과 일치하는 주택 가격이 있는지 더 쉽게 식별할 수 있기 때문에 검색을 훨씬 더 빠르게 구체화할 수 있습니다.
A 동네 평균 주택 가격: $220,000
B 동 평균 주택가격 : $190,000
C 동 평균 주택가격 : $140,000
각 동네의 평균 주택 가격을 알면 동네 C 에 예산 내에서 가장 많은 주택이 있을 가능성이 높다는 사실을 빠르게 알 수 있습니다.
이는 중심 경향 측정법을 사용하면 얻을 수 있는 이점입니다. 이는 일반적으로 데이터 값이 어디에 있는지 설명하는 경향이 있는 데이터 세트의 중심 값을 이해하는 데 도움이 됩니다. 이 특별한 예에서는 젊은 부부가 각 동네의 일반적인 주택 가격을 이해하는 데 도움이 됩니다.
요점: 중심 경향 측정은 데이터 세트의 “중심”을 설명하는 단일 값을 제공하므로 유용합니다. 이는 단순히 데이터 세트의 모든 개별 값을 보는 것보다 훨씬 빠르게 데이터 세트를 이해하는 데 도움이 됩니다.
평균
중심 경향의 가장 일반적으로 사용되는 척도는 평균 입니다. 데이터 세트의 평균을 계산하려면 모든 개별 값을 더하고 총 값 수로 나누면 됩니다.
평균 = (모든 값의 합계) / (총 값 수)
예를 들어, 한 시즌 동안 같은 팀의 야구 선수 10명의 홈런 수를 보여주는 다음 데이터 세트가 있다고 가정해 보겠습니다.
| 플레이어 | #1 | #2 | #삼 | #4 | #5 | #6 | #7 | #8 | #9 | #십 |
|---|---|---|---|---|---|---|---|---|---|---|
| 홈런 | 8 | 15 | 22 | 21 | 12 | 9 | 11 | 27 | 14 | 13 |
선수당 평균 홈런 수는 다음과 같이 계산할 수 있습니다.
평균 = (8+15+22+21+12+9+11+27+14+13) / 10 = 15.2 회로 .
중앙값
중앙값 은 데이터 세트의 중간 값입니다. 데이터 세트의 모든 개별 값을 가장 작은 것부터 가장 큰 것 순으로 정렬하고 중앙값을 찾아 중앙값을 찾을 수 있습니다. 홀수 개의 값이 있는 경우 중앙값은 중간 값입니다. 짝수 개의 값이 있는 경우 중앙값은 두 중간 값의 평균입니다.
예를 들어, 이전 예에서 야구 선수 10명의 홈런 수 중앙값을 찾으려면 홈런 수의 내림차순으로 선수 순위를 매길 수 있습니다.
| 플레이어 | #1 | #6 | #7 | #5 | #십 | #9 | #2 | #4 | #삼 | #8 |
|---|---|---|---|---|---|---|---|---|---|---|
| 홈런 | 8 | 9 | 11 | 12 | 13 | 14 | 15 | 21 | 22 | 27 |
짝수 개의 값이 있으므로 중앙값은 단순히 두 중간 값의 평균인 13.5 입니다.
대신 플레이어가 9명이라고 가정해 보겠습니다.
| 플레이어 | #1 | #6 | #7 | #5 | #9 | #2 | #4 | #삼 | #8 |
|---|---|---|---|---|---|---|---|---|---|
| 홈런 | 8 | 9 | 11 | 12 | 14 | 15 | 21 | 22 | 27 |
이 경우 홀수 개의 값이 있으므로 중앙값은 단순히 중간 값인 14 입니다.
패션
모드는 데이터 세트에서 가장 자주 나타나는 값입니다. 데이터 세트에는 모드가 없거나(값이 반복되지 않는 경우), 단일 모드 또는 다중 모드가 있을 수 있습니다.
예를 들어 다음 데이터세트에는 모드가 없습니다.
| 플레이어 | #1 | #2 | #삼 | #4 | #5 | #6 | #7 | #8 | #9 | #십 |
|---|---|---|---|---|---|---|---|---|---|---|
| 홈런 | 8 | 9 | 11 | 12 | 13 | 14 | 15 | 21 | 22 | 27 |
다음 데이터세트에는 모드가 15 있습니다. 가장 자주 나타나는 값입니다.
| 플레이어 | #1 | #2 | #삼 | #4 | #5 | #6 | #7 | #8 | #9 | #십 |
|---|---|---|---|---|---|---|---|---|---|---|
| 홈런 | 8 | 9 | 11 | 12 | 13 | 15 | 15 | 21 | 22 | 27 |
다음 데이터 세트 에는 8, 15, 19 의 세 가지 모드가 있습니다. 가장 자주 나타나는 값입니다.
| 플레이어 | #1 | #2 | #삼 | #4 | #5 | #6 | #7 | #8 | #9 | #십 |
|---|---|---|---|---|---|---|---|---|---|---|
| 홈런 | 8 | 8 | 11 | 12 | 15 | 15 | 17 | 19 | 19 | 27 |
최빈수는 어떤 범주가 가장 자주 나타나는지 알려주므로 범주형 데이터로 작업할 때 중심 경향을 측정하는 데 특히 유용합니다. 예를 들어, 사람들이 가장 좋아하는 색상에 대한 설문조사 결과를 보여주는 다음 막대 차트를 살펴보세요.
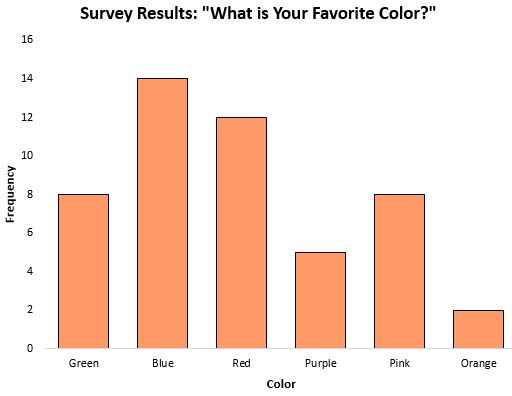
모드 , 즉 가장 자주 발생한 응답은 파란색이었습니다.
데이터가 범주형인 시나리오(위와 같은)에서는 중앙값이나 평균을 계산하는 것도 불가능하므로 모드는 우리가 사용할 수 있는 중심 경향의 유일한 척도입니다.
위의 야구 선수 예에서 본 것처럼 이 모드는 숫자 데이터에도 사용할 수 있습니다. 그러나 모드는 “이 데이터 세트의 일반적인 값은 무엇입니까?”라는 질문에 대답하는 데 덜 유용합니다. »
예를 들어, 이 팀의 야구 선수가 치는 일반적인 홈런 수를 알고 싶다고 가정해 보겠습니다.
| 플레이어 | #1 | #2 | #삼 | #4 | #5 | #6 | #7 | #8 | #9 | #십 |
|---|---|---|---|---|---|---|---|---|---|---|
| 홈런 | 8 | 8 | 11 | 12 | 15 | 15 | 17 | 19 | 19 | 27 |
이 데이터세트의 최빈값은 8, 15, 19입니다. 이는 가장 빈번한 값이기 때문입니다. 그러나 이는 팀 내 선수가 치는 일반적인 홈런 수를 이해하는 데 그다지 도움이 되지 않습니다. 이 경우 중심 경향을 더 잘 측정하는 방법은 중앙값(15) 또는 평균(또한 15)입니다.
또한 최빈값은 나머지 값과 멀리 떨어진 숫자인 경우 중심 경향을 측정하는 데 적합하지 않습니다. 예를 들어 다음 데이터 세트의 모드는 30이지만 이는 실제로 팀의 선수당 “일반적인” 홈런 수를 나타내지는 않습니다.
| 플레이어 | #1 | #2 | #삼 | #4 | #5 | #6 | #7 | #8 | #9 | #십 |
|---|---|---|---|---|---|---|---|---|---|---|
| 홈런 | 5 | 6 | 7 | 십 | 11 | 12 | 13 | 15 | 30 | 30 |
다시 말하지만, 평균 또는 중앙값은 이 데이터 세트의 중심 위치를 더 잘 설명합니다.
평균, 중앙값 및 모드를 사용하는 경우
우리는 평균, 중앙값 및 모드가 모두 매우 다른 방식으로 데이터 세트의 중심 위치 또는 “일반적인 값”을 측정한다는 것을 확인했습니다.
평균: 데이터 세트에서 평균 값을 찾습니다.
중앙값: 데이터 세트에서 중앙값을 찾습니다.
모드: 데이터 세트에서 가장 빈번한 값을 찾습니다.
다음은 중심 경향의 특정 측정값이 다른 측정값보다 더 나은 시나리오입니다.
평균을 사용해야 하는 경우
데이터 분포가 상당히 대칭적이고 이상값이 없을 때 평균을 사용하는 것이 가장 좋습니다.
예를 들어, 특정 도시의 개인 급여를 보여주는 다음과 같은 분포가 있다고 가정합니다.
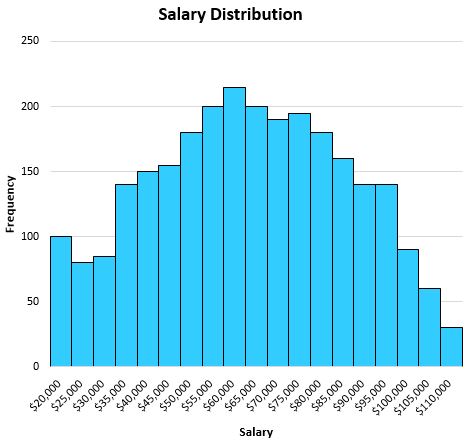
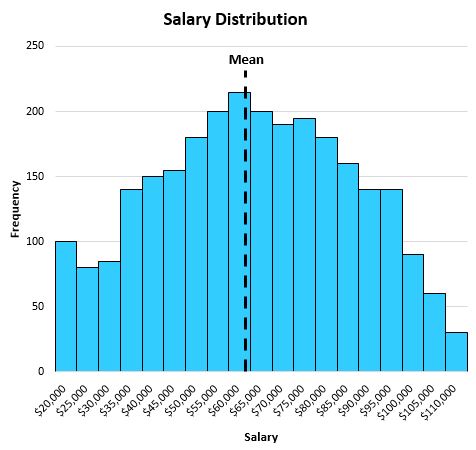
이 분포는 상당히 대칭적이므로(즉, 반으로 나누면 각 반이 대략 동일해 보임) 이상값(예: 극도로 높은 급여가 없음)이 없으므로 평균은 이 데이터 세트를 잘 설명합니다.
평균은 $63,000로 나타났으며 이는 대략 분포의 중앙에 있습니다.
중앙값을 사용해야 하는 경우
데이터 분포가 치우쳐 있거나 이상값이 있는 경우 중앙값을 사용하는 것이 가장 좋습니다.
편향된 데이터:
분포가 치우쳐져도 중앙값은 여전히 중앙 위치를 포착합니다. 예를 들어, 특정 도시의 개인 급여 분포가 다음과 같다고 가정해 보겠습니다.
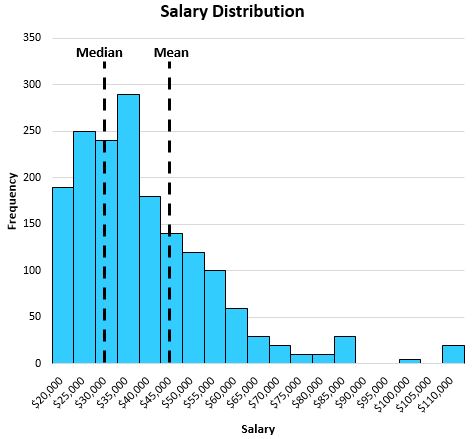
중앙값은 평균보다 개인의 “일반적인” 급여를 더 잘 반영합니다. 이는 분포 꼬리에 있는 값이 클수록 평균이 중앙에서 긴 꼬리 쪽으로 이동하는 경향이 있기 때문입니다.
이 특정 예에서 평균은 이 도시에서 일반적인 개인이 연간 약 $47,000를 벌고 있음을 알려주는 반면, 중앙값은 일반적인 개인이 연간 약 $32,000를 벌어들이는 것을 말하는데, 이는 일반적인 개인을 훨씬 더 잘 대표합니다.
특이치:
또한 중앙값은 데이터에 이상값이 있을 때 분포의 중심 위치를 더 잘 포착하는 데 도움이 됩니다. 예를 들어, 특정 거리에 있는 주택의 면적을 보여주는 다음 그래프를 살펴보세요.
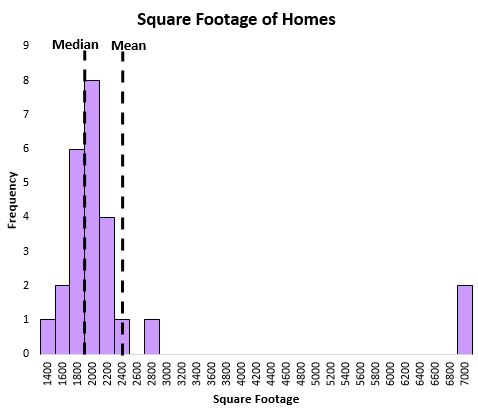
평균은 몇몇 매우 큰 주택의 영향을 많이 받는 반면 중앙값은 그렇지 않습니다. 따라서 중앙값은 해당 거리에 있는 집의 “전형적인” 평방 피트를 평균보다 더 잘 포착합니다.
모드를 사용하는 경우
이 모드는 범주형 데이터로 작업하고 어떤 범주가 가장 자주 나타나는지 알고 싶을 때 가장 잘 사용됩니다. 여기 몇 가지 예가 있어요.
- 사람들이 좋아하는 색상에 대한 설문조사를 실시하고 있으며 응답에서 가장 자주 나타나는 색상이 무엇인지 알고 싶습니다.
- 귀하는 웹사이트 디자인에 대한 세 가지 선택 중에서 사람들의 선호도를 조사하고 있으며 사람들이 어떤 디자인을 가장 선호하는지 알고 싶습니다.
앞서 언급했듯이 범주형 데이터로 작업하는 경우 중앙값이나 평균을 계산하는 것도 불가능하므로 최빈값이 중앙 경향의 유일한 측도가 됩니다.
일반적으로 주택 면적, 선수당 홈런 수, 개인 급여 등과 같은 수치 데이터로 작업하는 경우 일반적으로 중간값 또는 평균을 사용하여 “일반적인” 값을 설명하는 것이 가장 좋습니다. 데이터 세트.
참고: 데이터 세트가 완벽하게 정규 분포를 따르는 경우 평균, 중앙값 및 최빈값이 모두 동일한 값을 갖는다는 점에 유의하는 것이 중요합니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기